
Are you ready to delve into the fascinating world of organizing information and enhancing data intelligence? As organizations increasingly recognize the importance of unstructured data and semantic intelligence, the integration of taxonomies and ontologies into a semantic layer has become paramount in driving effective knowledge organization systems and supporting new business initiatives and AI endeavors.
The need for smarter approaches to data structuring and interpretation has never been more pressing. According to Gartner, “Growing levels of data volume and distribution are making it hard for organizations to exploit their data assets efficiently and effectively. Data and analytics leaders need to adopt a semantic approach to their enterprise data to drive business value and break data silos.” This is where knowledge organization systems can come to the rescue.
The Progress Semaphore and Enterprise Knowledge team recently hosted a webinar on “The Role of Taxonomy and Ontology in Semantic Layers.” The session focused on the importance of knowledge organization for unleashing the full potential of enterprise data assets. The following are some frequently asked questions from the webinar that our Semaphore team of experts has tried to explain in more detail.
Question 1: How do taxonomies and ontologies work within an organization?
Taxonomies and ontologies play a crucial role in organizing and leveraging information within enterprises. Taxonomies provide structured classifications that facilitate different use cases, so data and resources are easily accessible and logically organized. These use cases include efficient navigation and search, metadata management, consistent tagging and harmonization. By standardizing terminology and grouping related concepts, taxonomies can enhance communication and collaboration across teams. Ontologies capture domain-specific knowledge in a structured format, supporting automated reasoning and promoting interoperability between various systems and data sources. Together, taxonomies and ontologies empower organizations to harness the full potential of their information assets, improving decision making, fostering innovation and driving operational excellence.
Question 2: Does the business glossary serve as the “building block” for the taxonomy?
It’s important to understand that any form of controlled terminology is valuable input to the building of an enterprise taxonomy. Business glossaries are just one such source. But it is of paramount importance that one does not get bogged down in debating what source is more important than another. A common challenge to the development of a taxonomy or ontology is that it is “too hard,” and that the effort to pull together such “complicated” artifacts is an impediment to getting started with a semantic layer. But, in fact, the basics of a business taxonomy or ontology are always present in an organization. How can this not be the case? Are there lists of accounts? Customers? Products? Processes? Of course, there are. No organization could function without an understanding of the basic concepts by which the business operates. A taxonomy or ontology is nothing more than the encoding of that understanding and knowledge. To suggest that a business “doesn’t have time” to develop an ontology is the same as saying the business doesn’t have time to understand what it is doing. In fact, at a very basic level, the entire point of a taxonomy, ontology, business glossary—any of these things—is for an organization to be able to clearly document what it is doing, so that the understanding can be communicated across the business, from people to computers.
So yes, a business glossary can inform the development of a business taxonomy. It’s an excellent place to start. However, it’s important to understand that a glossary is intended to supply definitions of critical terminology. It is not directly intended to support the tagging of content, the organization of search results or the structure of navigation menus. So, it will have to be adapted.
Question 3: Is there any template for modeling ontologies?
There are many different takes on how to model ontologies and other conceptual representations of the world. And, often, regardless of the modeling approach, you will almost certainly have to make concessions to how the ontology will be used in real-world applications. That is, building a working ontology is often a compromise to make it work efficiently and effectively. So, choose an approach so that ontologies are developed consistently, but don’t let them prevent their practical application. Because an unused, difficult-to-maintain ontology does not have any value.
Question 4: How can we model ontologies and integrate them with open ontologies and vocabularies such as FIBO, BFO and others?
It’s always a good idea to look for externally developed ontologies that may be relevant to your business. Defining an ontology involves a systematic approach to defining concepts, entities and their relationships within a specific domain. Integrating with existing open ontologies and vocabularies like FIBO, BFO or those from the OBO Foundry leverage established standards and promotes interoperability—both within and outside the organization. Those ontologies can be imported and used in Semaphore or mapped against them. One common use case pattern is to build a model for classification or fact extraction which in turn uses a public/open ontology standard to represent the common language or concepts commonly recognized in the domain. But caution is also advised when it comes to taking the external ontologies too literally. They were likely not designed specifically for your business objectives so be sure you are using them in a way that is relevant to your organization’s needs. Learn how Semaphore helps enterprises take the FIBO vocabulary and put it to work.
Question 5: How can I get started with building a semantic layer?
Semantic layers are important in knowledge management, bridging the gap between data and meaningful insights. Enterprise Knowledge has provided excellent materials outlining what semantic layers are and how to implement them in enterprise contexts. This is a great place to start your journey.
Semaphore supports the development of semantic layers by providing the capabilities for creating, maintaining and using business glossaries, taxonomies and ontologies and developing consistent metadata by automatically tagging and classifying content. Adding Semaphore to your digital ecosystems provides the critical component of a semantic layer.
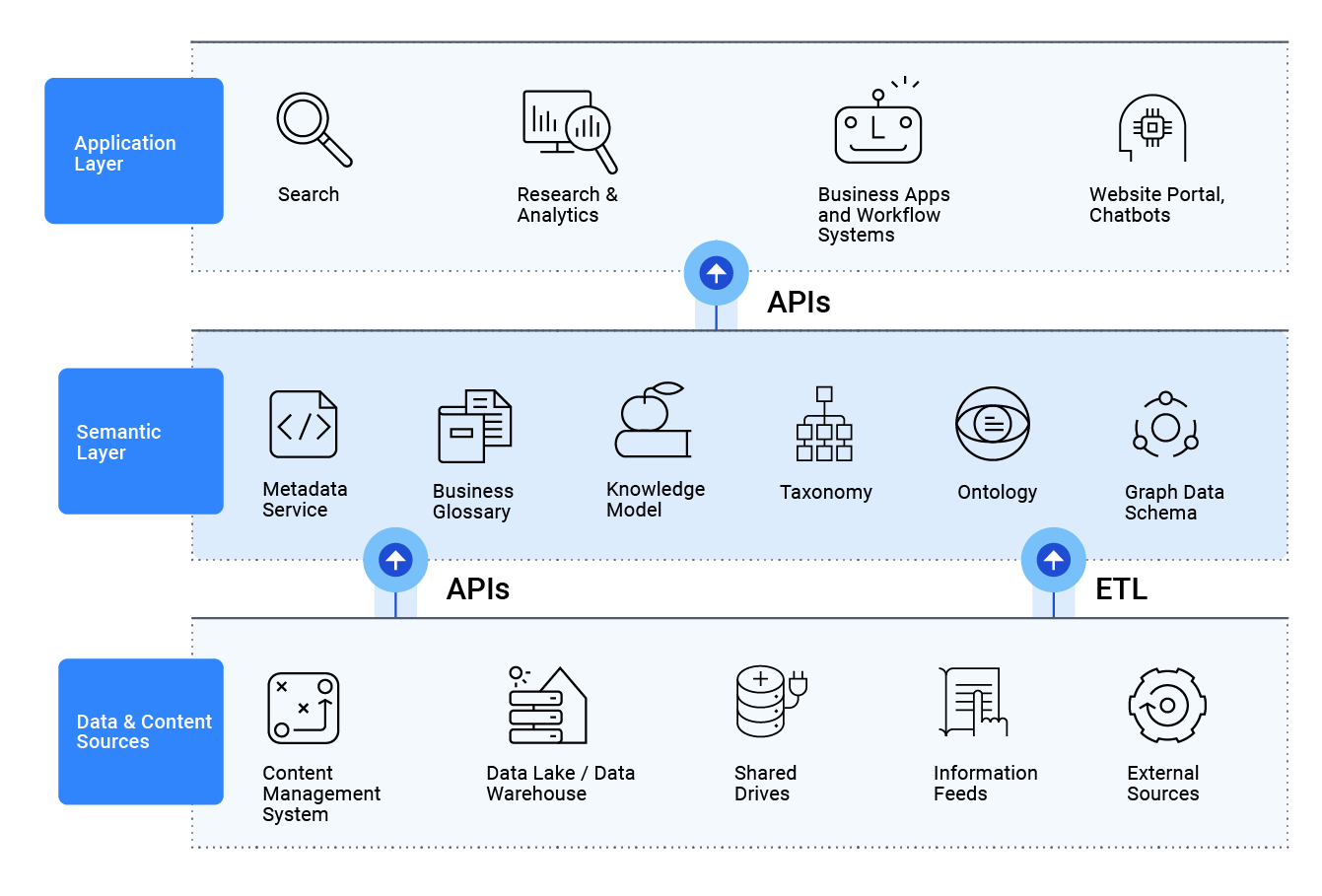
Semantic layers can significantly enhance data meshes and data fabrics by applying agile metadata, encoding interoperability and providing greater contextual understanding. By integrating semantic layers into these architectures, organizations can overcome the challenges of disparate data sources, formats and schemas—enabling seamless data integration and data agility. This facilitates better data discovery, harmonization, governance, consistency and reliability in data consumption.
Question 6: With consuming systems of a semantic layer likely distributed across an organization, what are some best practices for engagement and implementing a centralized model?
One important theme of semantic layers is that they don’t require owners of databases to turn over any control of data. A central repository of data isn’t a prerequisite. Unlike a data lake, a semantic layer starts by defining the meaning and context of data in an organization, e.g., what is it used for, how is it defined, what processes does it support, how does it relate to other data, etc. A semantic layer can start small by identifying specific use cases where the benefit of data integration is clear. This is why semantic layers often employ graph architectures, so new information can be quickly added without radical changes to the underlying data structures. These factors can make adopting a semantic layer easier to implement in a highly distributed organization with a lower initial investment.
Question 7: What is the link between taxonomies, ontologies, knowledge graphs and data catalogs?
Both taxonomies and ontologies are modeling areas of knowledge. This is why in Semaphore we refer to them in general as knowledge models. That is, they provide context (meaning, relationships, labels, definitions, etc.) about the concepts used in business, research or other organizational processes. What drives those processes? It’s the effective creation, management and use of data, communications, documents, etc.—wherever information exists that is used to make decisions. A data catalog keeps track of where the data is, in what database it was created, what the names of the fields are, where that data is consumed, etc. A knowledge graph can combine all these things so that you can know not only where data is, but what it means in relation to other data—regardless of where it is stored. An often-overlooked challenge is identifying what data is actually about. Just because you know the field name and the database doesn’t mean you know what the data is about, what purpose it serves or how it can be matched or associated with similar data in other systems. And what if the data is encoded in the text of a document? How do you make that part of the “graph”? This is why Semaphore is not just a taxonomy or ontology tool. Our focus is on how to make use of those knowledge models to gain a better understanding of your data.
Question 8: How can AI enhance the effectiveness of taxonomies?
Generative AI can be used by organizations to create, enrich and manage their taxonomies and knowledge organization systems more efficiently. Progress is developing ways to use generative AI with Semaphore to support the development and enhancement of taxonomies, making it easier for business experts to get closer to the data faster. Enterprise Knowledge outlines in their blog, “Generative AI for Taxonomy Creation,” how generative AI technologies like ChatGPT can be used to generate taxonomies. At the same time, Semaphore can also optimize the use of LLMs and generative AI by applying its NLP and classification capabilities to strategically leverage internal data and documents when providing
Watch our recent webinar, “Leveraging Generative AI to Jump Start Your Semantic Knowledge Modeling,” where we outline a unique approach to using generative AI to provide and assist with your semantic modeling and taxonomy development. Combining generative AI with a human in the loop, using the powerful Semaphore technology, can deliver better overall results in your use of generative AI.
Question 9: How does Semaphore support taxonomy enrichment?
Semaphore is a semantic platform that enables users to create and manage taxonomies, ontologies, controlled vocabularies, thesauri and other model types to be used with automated tagging and fact-extraction processes so organizations can leverage the value of all enterprise information. There are several ways that Semaphore supports the enrichment of models. These include NLP text-mining and analysis of relevant content and machine-generated synonym expansion. Generative AI is also being leveraged to enrich the language of concepts and to build taxonomic structures.
Question 10: Can Semaphore upload different ontologies? How does Semaphore accelerate the link between an ontology and the physical layer?
There is no limit to the number or size of ontologies or other types of knowledge models that can be imported into Semaphore. It can also import different ontology formats. That said, Semaphore is all about applying many different knowledge models to real-world data and content in a consistent way, so it makes sense that a transformation might be required. One of the primary reasons our clients select Semaphore is its ability to create and intelligently populate metadata properties of a content management system or other type of database. The metadata could be describing the data, enriching the data or generating data that is latent in documents. The assigned data is conceptually linked back to the Semaphore model used to create it, forming the essence of a knowledge graph. In this sense, Semaphore is designed from the ground up to link the physical layer and the semantic/conceptual layer.
Thank you to everyone who joined our webinar and raised these questions. It was great to see the level of interest you have in the topics discussed and Semaphore as a whole. Also thank you to everyone who reached out after the event with their feedback and kind comments. Finally, special thanks again to our guest speaker, Heather Hedden from Enterprise Knowledge. Heather always provides that deeper level of understanding when it comes to this topic, and I hope we can feature her again in the future.
Watch the webinar on demand and take a look at the webinars we have coming up.

Jim Morris
Jim began his career developing, supporting and managing systems and teams that facilitated the delivery of library and information services to R&D and Academic institutions. His experience later broadened into enterprise information management, intranet portals, content management systems, enterprise taxonomies and scientific ontologies. Jim joined the Semaphore team as an information scientist and solution engineer with a special interest in applying linked data and graph principles to vocabulary and metadata management. For almost 10 years, he’s shared his passion with clients across industries, continuing to advocate for the professions and practices enabling organizations to use information as effectively as possible.
Related Tags
Related Articles

Latest Stories in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites