
Progress ve la conectividad como la nueva integración. La canalización de datos híbridos simplifica la integración al conectarse directamente a los datos. Las aplicaciones comerciales necesitan datos, pero para construirlos de manera eficiente y ponerlos en manos de los usuarios, los desarrolladores no pueden pasar horas codificando una conexión de datos a la vez. Necesitan integrar aplicaciones y datos rápidamente, sin importar dónde vivan esos datos; en el sitio, en la nube o en ambos.
Acceso en tiempo real a fuentes de datos infinitas
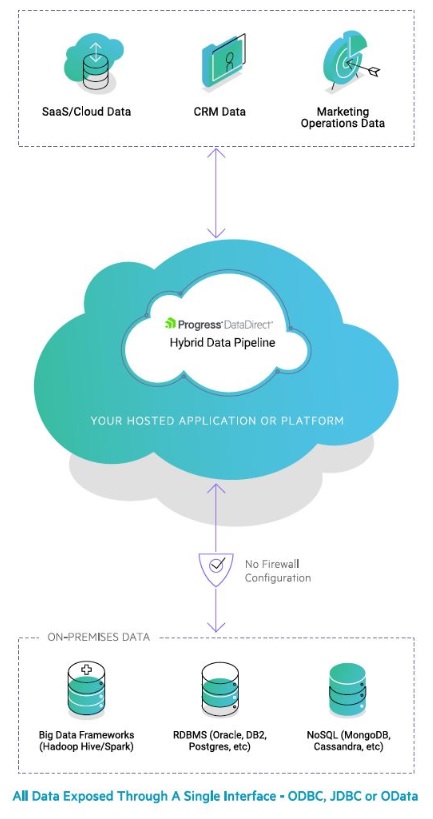
Progress DataDirect Hybrid Data Pipeline cambia completamente la forma en que las aplicaciones acceden a los datos.
Hybrid Data Pipeline es un servicio de acceso a datos ligero e integrable que simplifica la integración al conectarse directamente a los datos. Esto proporciona a las aplicaciones la capacidad de utilizar SQL u OData para realizar el acceso en tiempo real a datos locales y en la nube. Esto evita que los desarrolladores tengan que hacer ETL. Conectarse directamente a los datos es más ágil que configurar un nivel medio y la integración en tiempo real es a veces mejor que ETL.
Manténgase al día con las APIs
La canalización de datos híbrida expone una amplia gama de fuentes de datos con una única interfaz estándar (REST y SQL). Y admite API basadas en estándares: ODBC, JDBC y OData para permitir que las aplicaciones existentes aprovechen fácilmente sus características. No es necesario que los desarrolladores codifiquen sus aplicaciones en API específicas de fuentes de datos. Hybrid Data Pipeline es fácil de instalar y configurar. Los clientes pueden estar en funcionamiento rápidamente, en aproximadamente 30 minutos, utilizando sus habilidades y conceptos existentes.
Hybrid Data Pipeline se mantiene al día con la gama cada vez mayor de fuentes de datos locales y en la nube a las que las aplicaciones de los clientes deben acceder para que sus clientes no tengan que hacerlo.