
データハブのカスタムステップをNon-Codingで作成する
今回は、現時点ではベータ版ですが、コミュニティで開発中のPipesというツールを紹介します。https://github.com/marklogic-community/pipes/wiki PipesはカスタムステップをGUIで作成するためのツールです。以下のようなUIになっています。
基本構成編
このPipesを使用して、これまでに作成したCustomer1のフローを実装してみたいと思います。 Customer1のフローは次のようなものでした。(URIを参照)

図2 前回作成したCustomer1フロー
実は上記の図1はこのフローのマッピングステップを実現しています。 これに加えて、カスタムステップでのトリプルの作成と、URIの変更をPipesで1つのステップとして実装してみたいと思います。
準備
- データハブのデータフローとカスタムステップ
- Pipesのjarファイルと構成ファイル
データハブ
使用するデータはこれまでに使用してきたものと同じcustomer1.csvです。以前のフローはそのままにして新しくフローを作ります。フローの名前はCustomer1Newとしておきます。 そこには、Ingestionステップとデフォルトのままのカスタムステップを作成します。次のようなフローができます。 Ingestion ステップでは名前をloadCustomer1に、Source Directory Pathは適宜csvファイルがあるディレクトリに設定し、Source FormatソースフォーマットはDelimited Textに設定してください。 URIはこの後で変更するためTarget URI Replacementは変更しなくても構いません。
カスタムステップは以下のように、名前をcurateCustomer1 , Source collection はLoadCustomer1を選択し、targetEntityとしてはCustomerを選択してください。 このcurateCustomer1のモジュールは、この後でPipesが自動生成するコードを使用しますので、デフォルトのままにしておいてください。
図4 curateCustomer1の設定
この新しいフローの作成完了後に、loadCustomer1ステップだけを実行しておいてください。データは前回と同じで以下のようなデータです。
customer1.csv
id,Kanji_sei,Kana_sei,Kanji_mei,Kana_mei,Gender,Pref,Address,Tel,Date,introducedBy 0001,田中,たなか,一郎,いちろう,男,東京都,中野区中野1ー1−1,03-1274-7834,1990/3/31, 0002,鈴木,すずき,大輝 ,だいき,男,千葉県,野田市清水33-1,03-2421-3416,1995/1/20,0001 0003,佐藤,さとう,美咲,みさき,女,東京都,世田谷区北沢3-2-4,03-5621-3663,1997/6/5,0001 0004,伊藤,いとう,健太,けんた,男,神奈川県,川崎市高津区5-3-2,07-3421-3456,1969/6/27,0002 0005,吉田,よしだ,遥,はるか,女,東京都,渋谷区神宮前6-12-9,03-4563-2345,1964/4/14,0002 0006,松本,まつもと,杏奈,あんな,女,東京都,千代田区丸の内3-2-1,03-5675-3466,1995/7/22,0003 0007,清水,しみず,彩香,あやか,女,千葉県,柏市柏43-3-1,07-2324-5621,1974/7/2,0002 0008,青木,あおき,諒,りょう,男,神奈川県,横浜市青葉区4-3-2,05-4233-4322,1981/5/2,0003 0009,中野,なかの,達也,たつや,男,東京都,足立区千住12-4-3,03-5343-4356,1982/8/25,0001 0010,坂本,さかもと,裕太,ゆうた,男,東京都,練馬区石神井町12-3-4,03-4452-3453,1983/9/11,0001
Pipesの準備
Pipesを実行するためのjarファイルは以下のサイトからダウンロードしてください。https://github.com/marklogic-community/pipes/releases
このblogの執筆時点のバージョンはベータ4です。 次に以下のような内容のapplication.propertiesという名前のファイルを作成します。
# this is where the UI will be running, make sure the port is not used server.port=8081 # MarkLogic DHF settings mlHost=localhost mlStagingPort=8010 mlAppServicesPort=8000 mlAdminPort=8001 mlManagePort=8002 mlModulesDatabase=data-hub-MODULES # this is the root of your DHF project to deploy backend modules to mlDhfRoot=/space/dhf-project # customModulesRoot=/space/marklogic-pipes/Examples
主に変更の必要がある項目は次の4項目です。
| 項目 | 意味 |
| mlStagingPort | STAGINGデータベースに設定されているアプリケーションサーバのポート番号です。デフォルトは8010です。 |
| mlModulesDatabase | データハブでMODULESデータベースとして使用されているデータベース名です。デフォルトはdata-hub-MODULESです。 |
| mlDhfRoot | データハブプロジェクトのルートディレクトリです。 |
| customModulesRoot | ユーザ定義ブロックを格納するディレクトリです。後半で使用しますが、ここではひとまずコメントアウトしておきます。 |
ここでは、application.propertiesが置かれているディレクトリを /space/marklogic-pipes としておきます。もちろん他のディレクトリでも構いません。このディレクトリで次のコマンドを実行します。
sudo java -jar marklogic-pipes-1.0-beta.4.jar --deployBackend=true --mlUsername=ユーザ --mlPassword=パスワード
ここでのユーザとパスワードはMarkLogicのユーザとパスワードです。 この後ブラウザで、localhost:8081を参照すると以下のような画面になります。
図5 Pipesの初期画面
右上の「Reset graph to default DHF config」という白紙のアイコンをクリックすると次の2つのブロックが表示されます。
図6 Custom Step InputブロックとCustom Step Outputブロック
Inputブロックはカスタムステップが受け取る情報つまりcontent、uri、collectionsを出力しています。アウトプットはカスタムステップの処理結果を入力します。 どのような情報がcontentに入っているかを見たい場合には、Custom Step InputのinputとCustom Step Outputのoutputを結んで、右上のPreview Execute Graphボタンをクリックしてください。
図7 ブロックを繋ぐ
図8 Preview Graph Execution
Preview Graph Execution がポップアップされます。ここでは、Source Databaseではデータソースの データベース(ここではdata-hub-STAGING)を選択、Source Collectionではデータソースのコレクション(ここではloadCustomer1)を選択してください。 EXECUTE PREVIEWボタンをクリックするとこのカスタムステップへのinputが表示されます。
通常のカスタムステップでは、このInputとOutputブロックの他に
・ソースブロック ・エンティティブロック ・dhf/envelopeブロック
という3つのブロックを加えた5つのブロックが基本となります。 まずは、ソースブロックとエンティティブロックを作成します。どちらも左上のSetting and block creationというアイコンをクリックして作成します。 Setting and block creationでは、カスタムステップ情報としてグラフの命名やその他メタデータを登録できます。SOURCE BLOCKタブをクリックしてソースブロックを作成します。
図10 SOURCE BLOCKでのソースブロックの作成
ここでは、Block nameとしてCustomer1Source、ソースデータベースとソースコレクションとして、先ほどと同様にdata-hub-STAGINGとloadCustomer1を選択してください。 これにより下のFieldsにそのコレクション内のデータのプロパティが列挙されます。Fieldsの下のsourceの左側の三角形をクリックしてください。
図11 ソースブロックのプロパティの選択
カスタムステップの中で使用するプロパティとinstanceの左側のチェックボックスにチェックを入れておきます。 最後に「CREATE SOURCE BLOCK」ボタンをクリックしてCustomer1Sourceというソースブロックを作成します。 次にENTITY BLOCKSタブをクリックして、エンティティブロックを作成します。
図12 ENTITY BLOCKSでのエンティティブロックの作成
Select an entityで既存のエンティティを選択します。ここではCustomerというエンティティを選択して、「CREATE ENTITY BLOCK」ボタンをクリックします。 ここまででソースブロックとエンティティブロックを作成できました。 Setting and block creationアイコンをクリックし元の画面に戻り、適当な場所を右クリックすると、作成したソースブロックとエンティティブロックがリストにあることがわかります。
図13 ブロックのリスト
右クリックしたドロップダウンリストから Add Node-> Sources -> Customer1Source Add Node -> Entities -> Customer Add Node -> dhf -> envelope を選択すると次のような画面になります。
図14 必要なブロック
あとは、必要なマッピングを行うためにそれぞれの出力プロパティと入力プロパティを繋いでいきます。
図15 各ブロックの項目を連結する
この時点でPreview Execute Graphをクリックしてこのグラフによるキュレーションの結果を見てみましょう。
図16 当グラフで作成した結果
以前に作成したCustomer1フローでのマッピングとはまだ異なるところがありますが、とりあえずこの時点でこのカスタムステップをデータハブにデプロイしてみます。 右上のExport DHF custom step modeleアイコン(ドキュメント内に</>が表示されているアイコン)をクリックすると次のようなポップアップが開きます。
図17 Export DHF moduleポップアップ
Save to project codeとDeploy to MarkLogicにチェックをいれ、Select DHF5 Step to updateでは最初に作成したCustomer1Newフローの中のcurateCustomer1ステップを選択してExportボタンをクリックしてください。 最後にデータハブクイックスタートに戻り、curateCustomer1ステップを実行すると、FINALデータベースに上記の結果が作成されていることがわかります。 以下では、以前作成したMappingCustomer1と同様の関数を使ったマッピング処理と、そのためのユーザ定義ブロックについて説明します。
マッピング・変換ロジック編
MappingCustomer1でのマッピングは次のようなものでした。
図18 MappingCustomer1
ConcatやparseDateなどの関数を使っていました。これらに対応するものがPipesでもあります。 使用できるブロックの一覧は、 https://github.com/marklogic-community/pipes/wiki/3.-What-is-a-Block%3F-Block-types-and-an-introduction-to-the-Pipes-Block-library にあります。また、AddTripleCustomer1では次のような3つのトリプルをドキュメントに挿入していました。
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json",
"predicate": "introducedBy",
"object": "/customer/customer1/59662b07-5d52-4fc1-93af-35d23cf327be.json"
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json",
"predicate": "http://www.w3.org/2000/01/rdf-schema#label",
"object": "吉田遥"
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json",
"predicate": "http://www.w3.org/1999/02/22-rdf-syntax-ns#type",
"object": "http://xmlns.com/foaf/0.1/Person"
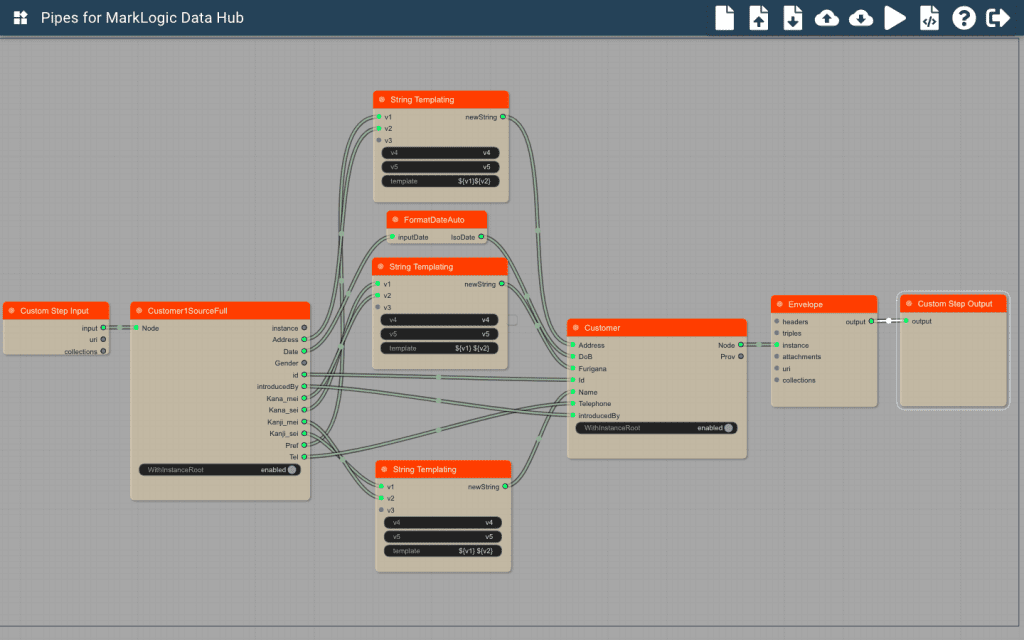
さらに以下の例ではURIとしてIdを使いたいと思います。 これらの変更を上記の基本的なPipesのグラフに追加していきます。 まずマッピングの基本部分を実装したグラフが以下の図です。
図19 マッピング部分の実装例
PrefとAddressの連結(間にスペースを入れない)してAddressへ、Kana_seiとKana_meiを連結してFuriganaへ、Kanji_seiとKanji_meiを連結してNameへということを行なっています(NameとFuriganaについては姓名の間にスペースを入れています)。このために Add Node -> String -> String Templating というブロックを使用しています。このブロックでは、templateというWidgetでテンプレートを指定し、各インプットv1、v2、v3、v4 をそのテンプレートに応じて形式を編集します。 Widgetのtemplateという部分をクリックするとウィンドウの中央あたりにポップアップが表示され、そこでテンプレートを編集できます。 ここではPref Addressについては${v1}${v2}とスペースを間に挿入せずに指定し、その他の2つについては${v1} ${v2}と間にスペースを入れて指定してください。 あとは連結したいプロパティをそれぞれString Templatingブロックのv1とv2に繋ぎます。
次が日付のフォーマット変換ですが、こちらは Add Node -> Date -> FormatDateAuto というブロックを使用します。日付の形式によらずに自動でISO形式に変換します。 ソースブロックのDateをFormatDateAutoのInputDateへ、FormatDateAutoのIsoDateをエンティティブロックのDoBへ繋ぎます。 この後でPreviewを実行すると以下のような結果が得られます。
図20 マッピングの基本部分の実行プレビュー
Address、DoB、Furigana、Nameが適切に変換されているのがわかります。 次にURIを変更します。これにもString Templatingブロックを使用します。Widgetのtemplateのところで /Customer1/${v1}.json と指定します。
図21 URIの変更
エンティティブロックのIdからString Templatingブロックのv1へ、String TemplatingブロックのnewStringからEnvelopeブロックのuriへ繋いでください。 こちらもプレビューでuriを見ると/Customer/0001.jsonのように変更されていることがわかります。 最後にトリプルを作成します。トリプルの作成には2種類のブロックを使用します。 Add Node -> triples -> CreateTriple Add Node -> Basic -> Array という2つのブロックです。 CreateTripleブロックは、主語と目的語を入力とし、述語をWidgetで指定します。 3つのトリプルの最初のトリプル
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json",
"predicate": "introducedBy",
"object": "/customer/customer1/59662b07-5d52-4fc1-93af-35d23cf327be.json"
を作成するためには、主語としては、新しく生成したURIつまり/Customer1/0001.jsonのようなURIになります。 そのため上記のnewStringがEnvelopeブロックへ繋がっているString TemplatingブロックのnewStringからもう一つ線を引き、CreateTripleブロックのsubjectへ繋ぎます。 また、目的語はintroducedByから作成したURIを使用します。 そのために、introducedByからStringTemplatingでURIを生成し、それをCreateTripleブロックのobjectと繋ぎます。述語である「introducedBy」はWidgetのPredicateに指定します。 生成されたトリプルはCreateTripleブロックの出力であるtripleからArrayブロックへ繋ぎます。これは、EnvelopeのTripleはArray型がデフォルトになっているためにArrayに連結します。 最初のトリプルの生成は以下の図のようになります。
図22 トリプル作成
図23 トリプル作成の結果
続いて、
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json", "predicate": "http://www.w3.org/2000/01/rdf-schema#label", "object": "吉田 遥"
というトリプルを作成します。主語については上記のトリプルとまったく同じです。目的語はエンティティのNameに繋がっているStringTemplatingのnewStringを繋ぎます。
図24 URI-label-名前 トリプルの作成
最後のトリプルである
"subject": "/customer/customer1/9fbeb3a2-b7df-4c67-888a-6e8cc764d44f.json", "predicate": "http://www.w3.org/1999/02/22-rdf-syntax-ns#type", "object": "http://xmlns.com/foaf/0.1/Person"
については、目的語が固定の文字列であることから Add Node -> String -> Constant というブロックを使用します。このブロックではWidgetで任意の文字列を指定し、それを出力として使用することができます。
図25 URI-type-Person トリプルの作成
これら3つのトリプルを追加した後のプレビューは以下のようになります。
図26 トリプル追加結果
最終的なグラフは以下のようになります。
図27 コレクションやAttachmentsを連携したカスタムステップの実装
これを再度データハブへデプロイします。
図28 データハブへのデプロイ
今回は、データハブのカスタムステップを実装するためのツールPipesについて、実際にこれまでに使用してきた例を使ってカスタムステップ作成方法を解説しました。 ウィンドウを右クリックするとここで紹介したものの他に多くの関数ライブラリがあることがわかりますし、ユーザがブロックを作成することもできます。 このようなツールによってフロー開発者の責務を分割できると、新しいデータや要件の変更にさらに迅速に対応できることがわかるかと思います。
ツール自体はまだベータ版ですので、これからも追加修正が行われていくと思いますが、このようなツールによって一つの方向性を示すことができればと思います。
太田佳伸
MarkLogic以前は、RDB、ORDB、ObjectDB、サーチエンジン、XMLDB等々のベンダーでエンジニア、エバンジェリスト、テクノロジスト等を経験してきました。
最近はPoCや新しい機能の調査を担当しています。
平日はMarkLogicのServerSide JavaScript、休日は高校生にC /C++等々のロボットプログラミングを教えています。