
The typical process of migrating data from a relational database into MarkLogic has always translated to ad-hoc code or csv dumps to be processed by the MarkLogic Content Pump (mlcp). Apache NiFi introduces a code-free approach of migrating content directly from a relational database system into MarkLogic. Here we walk you through getting started with migrating data from a relational database into MarkLogic.
Note: The following steps assume that MarkLogic v9 (or higher) is already running and is available locally. Additionally, Java 8 needs to be installed and configured.
NiFi Setup
Check out instructions on how to download a binary or build and run NiFi from source code, as well as a quick guide in getting it up and running. MarkLogic’s NAR files are available for download, along with instructions on what to do with them.
With NiFi running, load your browser to: http://localhost:8080/nifi. You might be surprised with a blank page on fresh start of the scripts, it takes a while to load.

Figure 1: Apache NiFi toolbar
Now that we have our NiFi instance running, we can start configuring our processes. For additional information about the available processors, visit the Apache NiFi documentation.
Defining the Flow
We want to establish a basic flow with the following steps:
- Retrieve records from the relational database
- Convert each row into a json document
- Ingest data into MarkLogic
NiFi Basics: How to add a processor
To add a Processor to your dataflow canvas, drag the Processor icon from the top of the screen down to the canvas and drop it there:
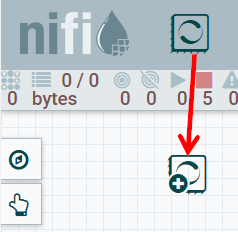
Figure 1: Adding a Processor to dataflow canvas
This will generate a dialog box that prompts you to select the Processor to add (see Figure 2). You can use the search box on the upper right to reduce the number of Processors displayed.
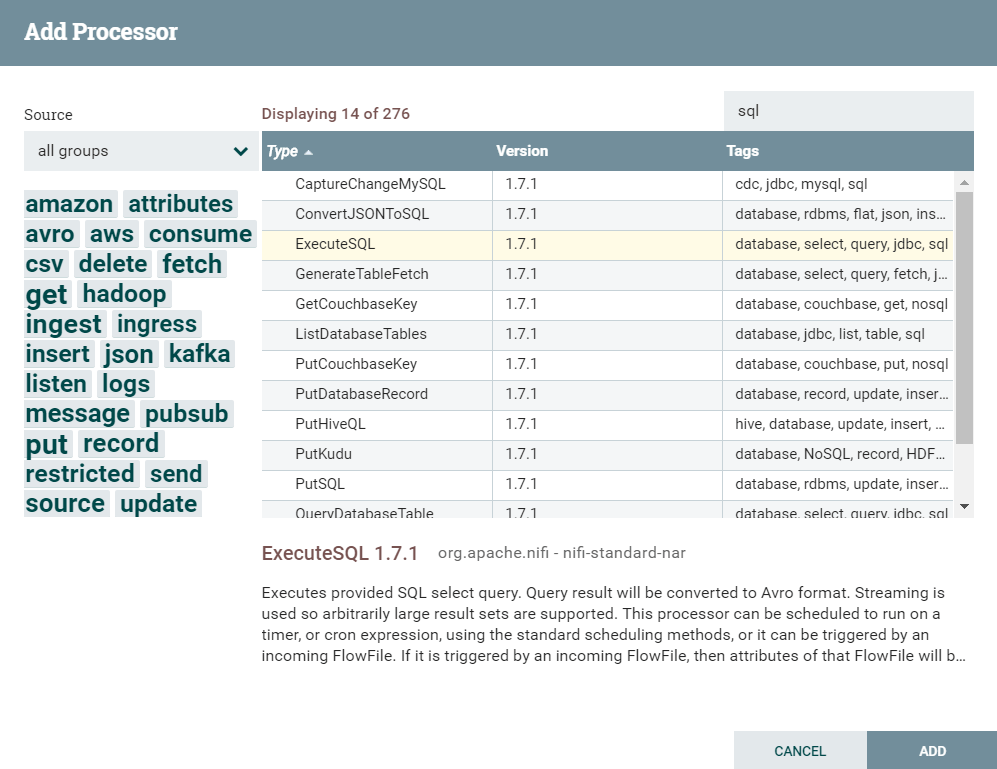
Figure 2: Add Processor screen
Flow Step 1: Retrieving relational data
As shown in Figure 2, there are several processor options to retrieve data from a relational database. QueryDatabaseTable and GenerateTableFetch have the ability to remember a column’s last value (a “Maximum-Value Column”). This is optimal for processing a table whose records never get updated (e.g., audit logs) since previously processed rows will not be processed again.
Add ExecuteSQL Processor
Let’s add an ExecuteSQL Processor to the dataflow canvas. This processor requires the user to supply the full SQL statement, giving room for de-normalizing the records at relational database level via joins. ExecuteSQL will retrieve the records from the database and return the records in Apache Avro format.
Configure ExecuteSQL Processor
Configure the Processor by right-clicking on the Processor and selecting Configure:
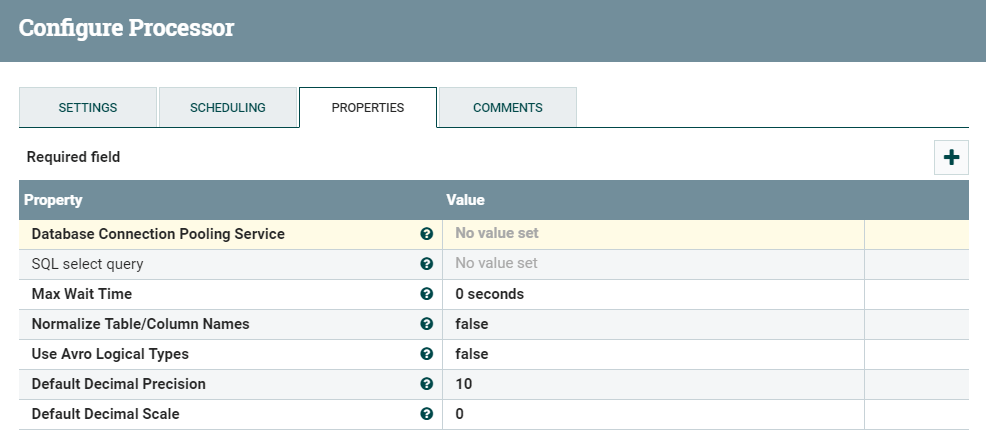
Figure 3: ExecuteSQL Processor Properties
The “Database Connection Pooling Service” needs to be created and configured by selecting “Create new service”:

Refer to Figure 4 for Database Connection Pooling Service property values. Be sure to supply the appropriate connection URL, Driver Class Name, and Driver Location for your relational database. The example below is for a MySQL database running on my local machine.
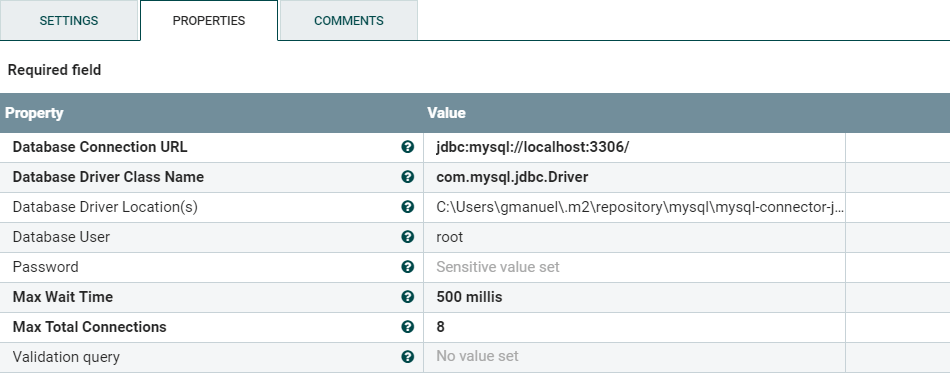
Figure 4: ExecuteSQL Processor’s Database Connection Pooling Service properties
Important: Remember to enable the connection pool after configuration by clicking the lightning bolt:

The “SQL select query” property value is the actual SQL select query used to get the data from the relational database. It can be as simple as select * from employee, or as complex as a 5-table join.
If you have a large number of records or expect a very long transaction period, you may want to adjust the “Max Wait Time” property.
Make sure to review the “Scheduling” tab to ensure it only runs when you want. The default is to run almost instantaneously after the first execution completes. If you only want to run the process once, consider having a really high run schedule for timer driven strategy, or specifying a fixed CRON value for execution.
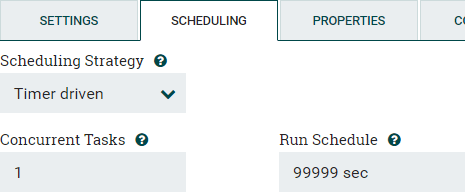
Figure 5: Configuring Processor Scheduling
Lastly, check the “Settings” tab and auto-terminate for cases of failures:

Figure 6: Selecting auto-terminate upon failure under “Settings”
Flow Step 2: Convert each row into a JSON document
This goal needs to be split into two steps:
- Convert Avro to JSON
- Split the entire result set into individual rows/records.
Convert Avro to JSON
Add a ConvertAvroToJSON Processor and configure it as follows:

Figure 7: ConvertAvroToJSON Processor Properties
The “Wrap Single Record” property ensures that we will always be processing an array. Note that:
- If set to False, the record is not processed as an array:
{"emp_id" : 1, "first_name" : "Ruth", "last_name" : "Shaw", ... } - If set to True, the record will be processed as an array: [
{"emp_id" : 1, "first_name" : "Ruth", "last_name" : "Shaw", ... }]
Under “Settings” tab, we auto-terminate on failure (see Figure 6).
Split the entire result set into individual rows/records
Add a SplitJSON Processor with the following configuration:
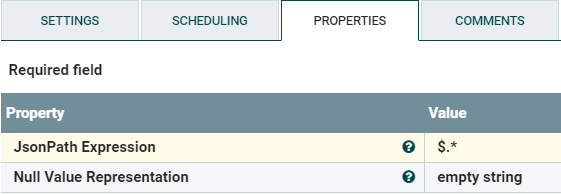
Figure 8: SplitJSON Processor Properties
If you are familiar with XPath, this article helps translate XPath to JsonPath. Note: This JsonPath is outside the scope of MarkLogic and will not work in your XQuery or Server-side JavaScript out-of-the-box.
Under “Settings,” auto-terminate on failure and original:

Flow Step 3: Ingest data into MarkLogic
Apache NiFi is meant to run continuously, and the starting Processor will execute at the configured frequency until it is stopped or disabled. Therefore, for consistency during re-runs, we recommend using the existing primary key as part of the resulting document URI. For example, an employee with ID of 1 will result in URI of /employee/1.json. In order to do this, we extract the primary key and store it as part of the FlowFile attribute.
Add an EvaluateJsonPath Processor and configure it as follows:
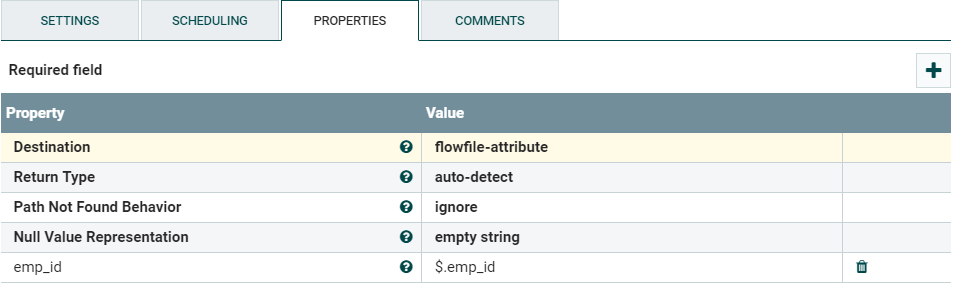
Figure 9: EvaluateJsonPath Processor Properties
The “Destination” is stores the extracted primary key value into the flowfile-attribute instead of overwriting the FlowFile’s content. The emp_id property is added using the “plus” icon. The value of this property is a JsonPath expression to be evaluated.
Under “Settings,” we auto-terminate on failure and unmatched.
For our final step, we push the documents into MarkLogic using a PutMarkLogic Processor, which makes use of MarkLogic’s Data Movement SDK behind the scenes, allowing documents to be written in batches, improving throughput and reducing latency.
If you search for “marklogic” when adding a Processor, two processors will be available:
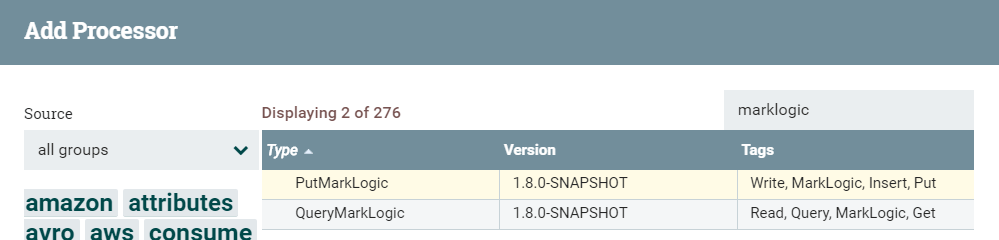
We configure the PutMarkLogic Processor as follows:
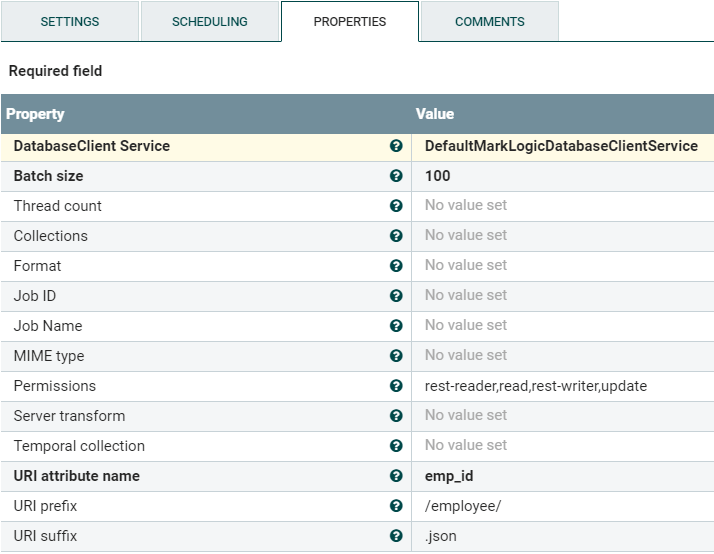
Figure 10: PutMarkLogic Processor Properties
Create the “DatabaseClient Service” property value; it’s similar to the “Database Connection Pooling Service.” Use the following screenshot as reference:
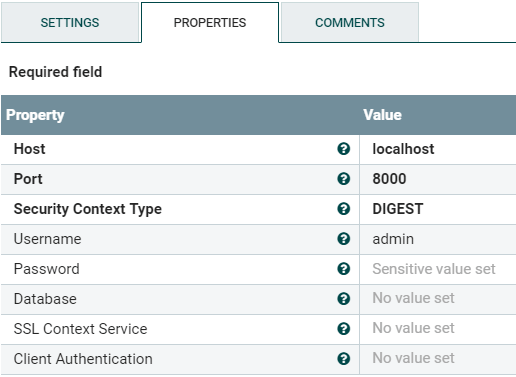
Figure 11: PutMarkLogic Processor’s DatabaseClient Service properties
The port for the DatabaseClient Service needs to support the MarkLogic REST API. You can also adjust the “Database” value if you want the documents written to a specific database and not the configured content database for specified port.
You can also configure the PutMarkLogic Processor’s “Permissions” property, as needed by your security model. Note that the “URI attribute name” property value is the extracted property emp_id from the earlier EvaluateJsonPath Processor.
Under “Settings,” terminate on both success and failure.
Wiring Processors Together
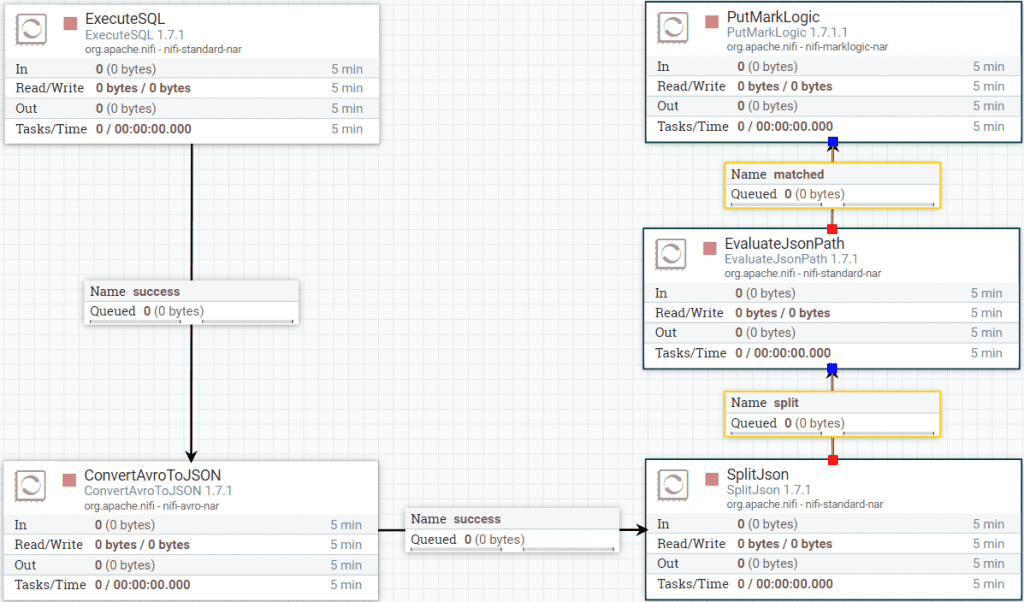
Now that we have all the processors in place, it’s time to wire them all together. Your NiFi dataflow canvas should look similar to this:
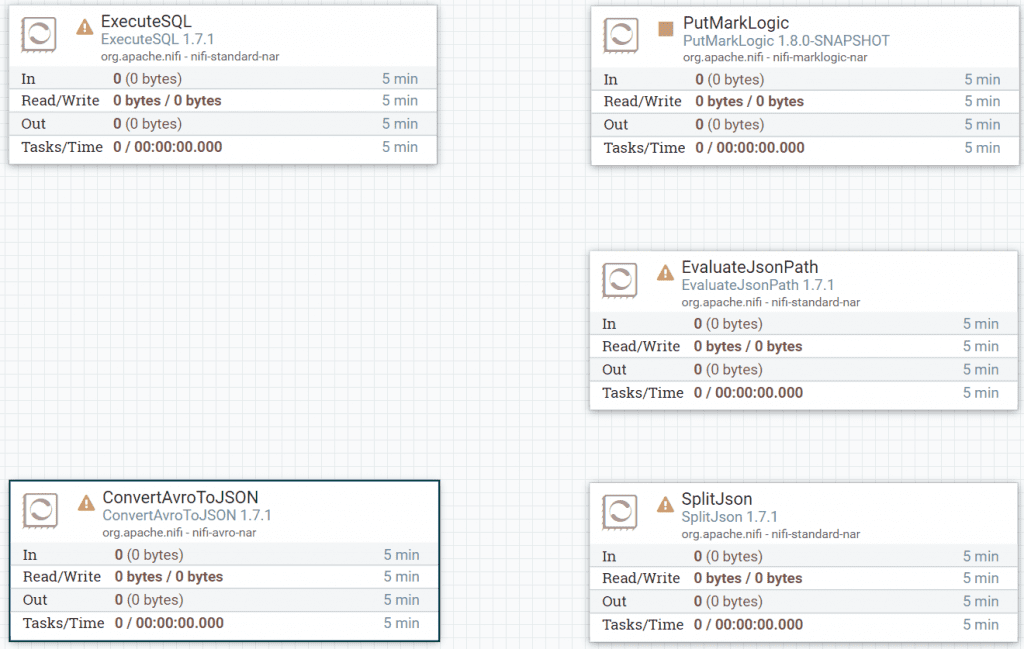
Figure 12: Dataflow canvas with only Processors
Hovering the mouse over the ExecuteSQL Processor will get the “connection” icon ( ) to appear. Click and drag this icon towards the ConvertAvroToJSON Processor and drop it there to make a connection:
) to appear. Click and drag this icon towards the ConvertAvroToJSON Processor and drop it there to make a connection:

If the connection is successfully created, a connection configuration screen will display. Configure the relationship for success:

We repeat the same process for the rest of our Processors:
- Drag the connector from ConvertAvroToJSON to SplitJson processor to establish a connection on success.
- Drag the connector from SplitJson to EvaluateJsonPath processor to establish a connection on split.
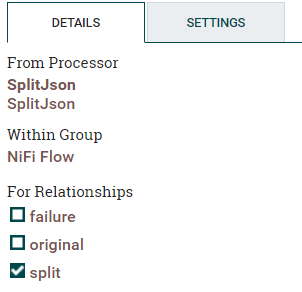
- Drag the connector from EvaluateJsonPath to PutMarkLogic processor to establish a connection on matched.
You should now have a flow similar to this:
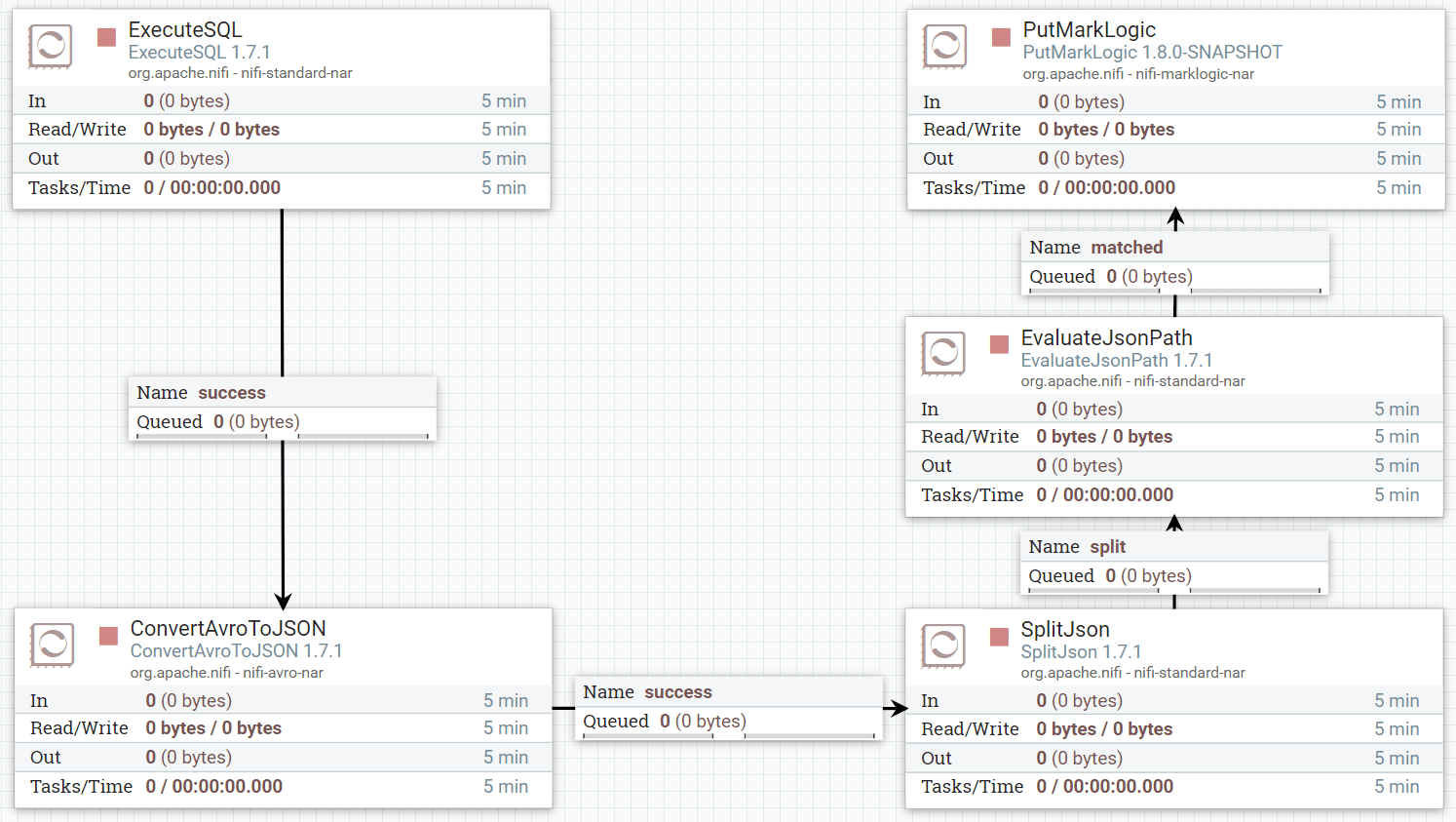
Figure 13: Dataflow canvas with Processors and connections
Run it!
Right click on a blank area to display the menu and click “Start”:
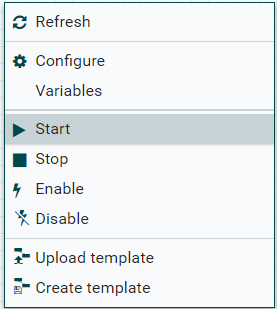
Note: Processors will not be able to be modified while they are running. If there is any processor you need to re-configure, you would need to “Stop” that processor.
Use MarkLogic’s Query Console (http://localhost:8000) to confirm that the relational rows were converted to documents:
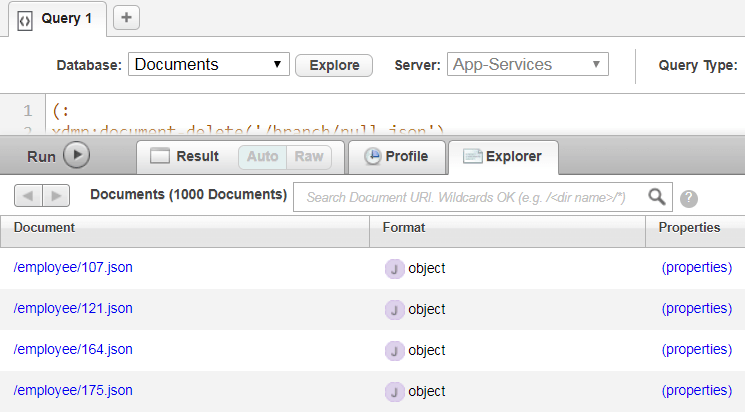
With content of:

Figure 14: Relational rows converted to documents in Query Console
Congratulations! Now you have your data migrated from your relational database into MarkLogic.
Bring DHF into the Mix!
A detailed guide on getting an Operational Data Hub is available to help you get started, along with the Data Hub QuickStart tutorial, which will walk you through getting your entities and input flows created.
To incorporate your existing flows, let’s adjust a few things. First, we either create a new MarkLogic Database Client Service, or adjust the service that is currently being used by our PutMarkLogic Processor as follows. Note that you must disable the service to make any changes.
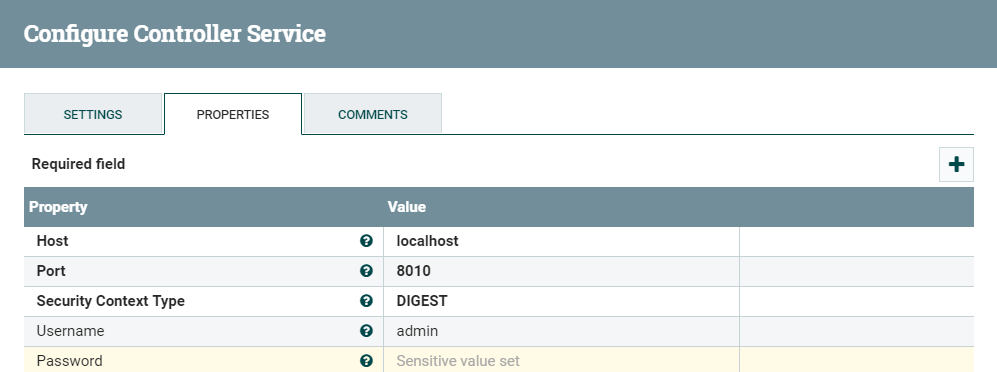
Figure 15: PutMarkLogic Processor’s DatabaseClient Service properties, updated for Data Hub
Note that the port now matches the staging datahub configuration. http://localhost:8010 is the default port used in the MarkLogic Data Hub QuickStart tutorial.
Modify our PutMarkLogic Processor as follows. Note that you must stop the Processor prior to making any changes:
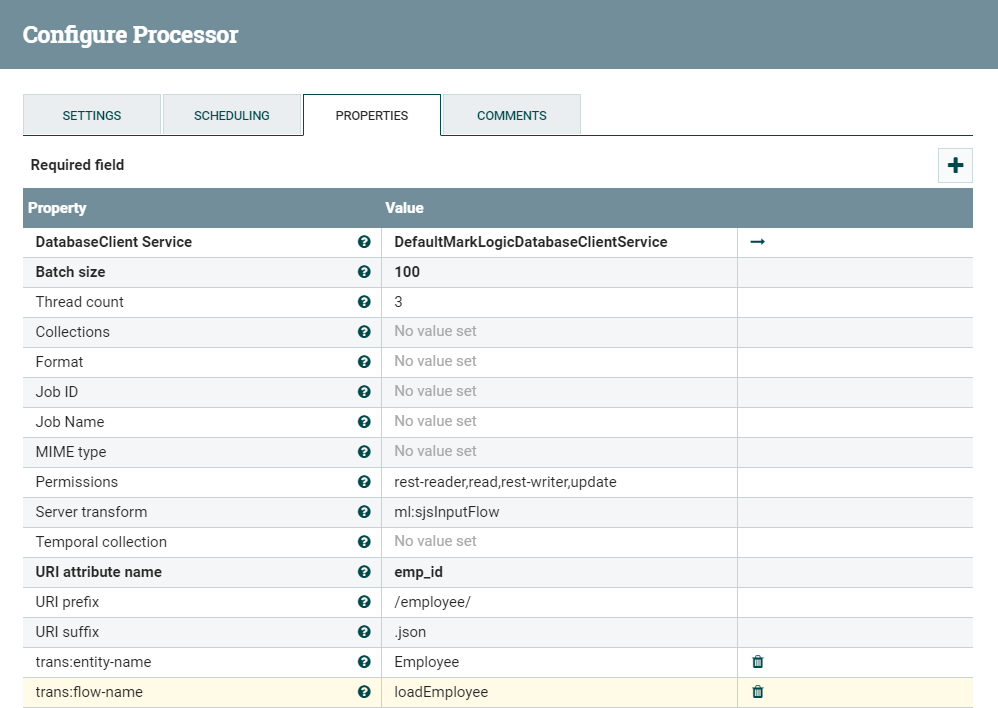
Figure 16: PutMarkLogic Processor Properties, updated for Data Hub
The data hub documentation on ingesting with the REST API will help determine which transform module to use given your flow implementation.
If you run the new flow into your MarkLogic data hub, you can check the staging database using the DHF QuickStart UI to confirm:

With content of:

Congratulations! Not only have you migrated data from your relational database into MarkLogic, you can now harmonize your data before downstream systems can access it.
Saving and Reusing a NiFi Template
Wiring the processors took no time at all to implement, but doing it over and over again can become tedious and can easily introduce mistakes during execution. In addition, our data sources may not limited to just relational sources (for example, REST calls, twitter feeds, CSVs, etc.). To “save” our work, we can select components and save them as a NiFi template that we can reuse later.
Select the components on the canvas you want to save as a template, including the connectors. Notice the darker blue borders.
Click on the “Create Template” icon ( ) on the operate panel that appears on the left-hand side. You should see this:
) on the operate panel that appears on the left-hand side. You should see this:
Provide a name and description for the template and click CREATE. If successful, you will see a prompt like this:
We can now make use of the template icon ( ) on the top. Click and drag it down to the canvas to get the following prompt:
) on the top. Click and drag it down to the canvas to get the following prompt:

If you expand the drop down, you can hover over the question mark icon to show the description of the template. This is a good reason to be concise but descriptive when creating your templates.

When you add the template to your existing canvas, the new processors may overlap on top of existing processors. Rearrange them as needed (i.e., side by side).
After adding this template, you may notice that the PutMarkLogic and SplitJson processors have yellow triangle alert icons because sources have not yet been specified. Note that the template creates a new MarkLogic DatabaseClient Service for the new processor instance created by the template. Double click on the processor to configure and click on the “Go To” icon (green arrow) of the DatabaseClient Service property. Notice that we now have an extra instance of the DefaultMarkLogicDatabaseClientService that is currently disabled.
We have two options at this point:
- Delete this instance and select the existing and enabled instance. This is recommended if we will be using the same MarkLogic instance with the same credentials and transforms.
- Rename and enable this new instance. This is recommended if we will be using a different instance and/or if we are to use a different transform (e.g. a different ingest flow, if we are using DHF).
If we choose Option 1, then configure the new instance of the PutMarkLogic processor to use the original instance of DefaultMarkLogicDatabaseClientService.
More information about templates are available in the Apache NiFi User Guide.
