Business Rules with GraphQL

On-Demand Data Retrieval in Rules
Business processes are complex, and for many decision services, it is not desirable or practical to pass all the data required for all conditions as part of the input payload. This would result in highly inefficient processes as the input data would be too large and could take too long to gather.
In this blog, we explore how we can dynamically retrieve data on demand using GraphQL.
What Is GraphQL?
GraphQL is a query language. It offers a flexible and efficient way to request only the necessary data. You can read more about it in this introduction.
GraphQL is a query language for APIs and a runtime for executing those queries using a type system you define for your data. It was developed by Facebook (now Meta Platforms) and is known for its efficiency and flexibility. Some of the key benefits of GraphQL include:
1. Declarative Data Fetching: Consumers can request exactly the data they need. This optimizes data transferred over the network. It leads to faster and more efficient data retrieval.
2. Strongly Typed Schema: GraphQL APIs are defined by a schema that specifies the data types and relationships. This schema acts as a contract between the client and the server, maintaining consistency and reducing errors. GraphQL lets you query the schema.
This optimized data retrieval makes it a great choice for Corticon as rules can request precisely what they need based on dynamic conditions in the decision service.
Design Pattern
In this design pattern, rules drive what additional data is necessary. Corticon.js uses a GraphQL Service Callout (SCO) to access specific data subsets, providing a powerful solution for querying data on demand and processing it efficiently.
This is illustrated in the following diagram:
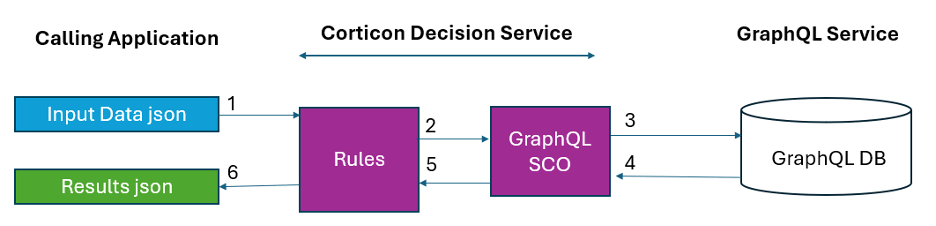
This diagram shows the execution flow between the calling application, the Corticon Decision Service and a GraphQL API:
1. Step 1: The calling application sends the initial input data (JSON format) to the Corticon Decision Service.
2. Step 2: The rules, based on a set of conditions, decide to use the GraphQL SCO to access additional data.
3. Steps 3 and 4: The SCO queries the data subset necessary for the rules.
4. Step 5: The data subset is inserted into the “in memory” data payload available for rule processing. Now, the Corticon Decision Service can continue rules execution with the complete data set.
5. Step 6: The Corticon Decision Service has finished processing all data and returns the results to the calling application in JSON format.
Where Is the SCO?
The SCO is available on GitHub, accompanied by a full Corticon.js project sample.
Please start with the readme file first.
The project contains three different decision services illustrating various possibilities.
The three decision services are each implemented in their own rule flow. The next three sections will provide a brief overview of each rule flow.
Simplest Rule Flow
The simplest rule flow is in GetOneCountrySimplest.erf and it implements only two steps:
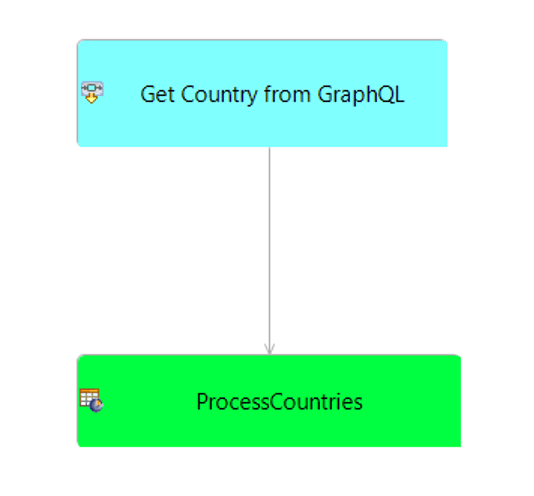
The first step in blue invokes the SCO, and then the second step in green processes the received data. In this design pattern, the query name and its associated parameter (the country code) are passed in the input payload to the decision service. This way, effectively, the calling application—and not the decision service itself—specifies what to query.
Here is an example:
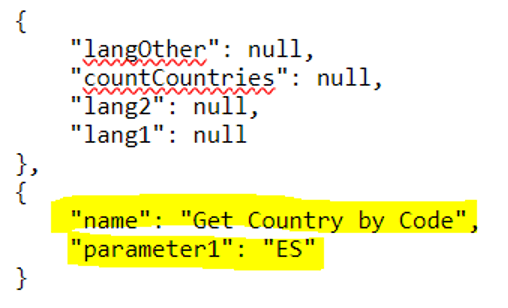
The calling application is specifying the name of the query to get country by code and the country code is ES for Spain.
We get the following result:

Rules Specify Queries
Of course, there are times when it is more desirable to have the rules decide when and what to query based on various conditions. In other words, instead of the calling application specifying the query parameters, the modeler makes the decision.
This design pattern is illustrated in GetOneCountry.erf.
This ruleflow implements an additional step compared to the previous case as shown here:
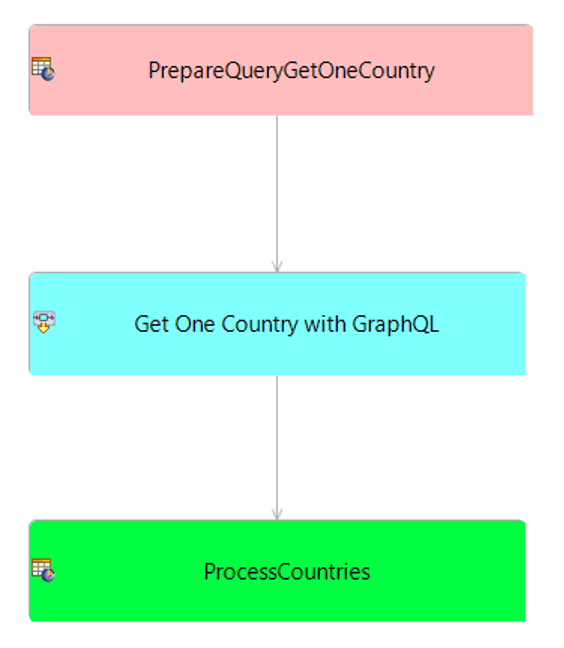
The only difference from the previous case is that the first step is specifying the query and the country code as shown here:

This design pattern is easier to integrate as the calling application does not have to specify anything for the GraphQL queries.
Multiple GraphQL Queries
The GraphQL SCO is not limited to a single query type or one query per decision service. This is illustrated in the rule flow GraphQL.erf where we first query all South America countries and then all Europe countries:
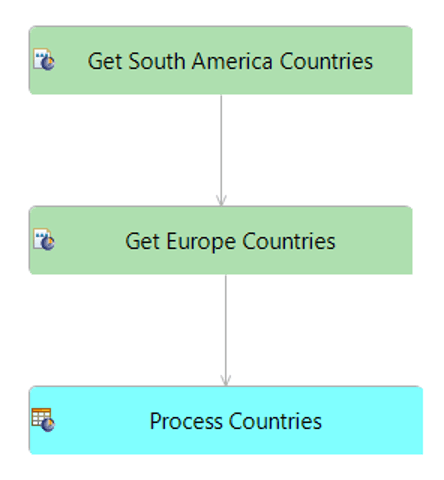
The first two steps query all the countries for a specific continent. Each one is implemented in a sub-flow. For example, to get South American countries, we have the following sub-flow:
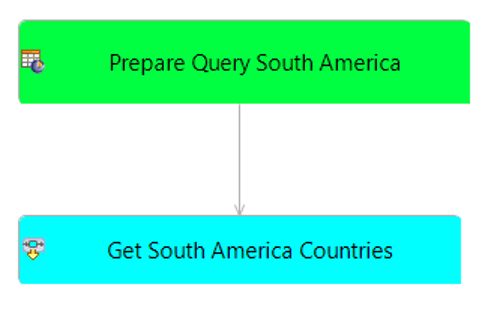
Here is how the GraphQL parameters are specified in the prepare query step:

Conclusion
Progress Corticon.js is no-code rule management software that offers extensive flexibility with integrating GraphQL data sources into decision services as shown by the three design patterns explored in this blog. Additionally, leveraging GraphQL in Corticon.js provides a powerful and highly efficient solution for querying and processing data.
To take the next step, enroll in free training for Corticon.js. or get familiar with the product by visiting the Corticon.js webpage.
For a more in-depth blog on GraphQL service callout with full CRUD capabilities, check out "Mastering Custom Corticon Operators: Flexibility Beyond Standard Implementations."

Thierry Ciot
Thierry Ciot is a Software Architect on the Corticon Business Rule Management System. Ciot has gained broad experience in the development of products ranging from development tools to production monitoring systems. He is now focusing on bringing Business Rule Management to Javascript and in particular to the serverless world where Corticon will shine. He holds two patents in the memory management space.
Related Tags
Related Articles

Latest Stories in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites