
Now a staple in the enterprise technology stack and data strategy, Artificial Intelligence (AI) projects are moving swiftly from prototype to production. Businesses have tested use case suitability and are now embedding foundational generative AI (GenAI) models into existing applications to democratize access to knowledge, enhance the user experience and augment workforce productivity. Document question answering, support chatbots and virtual assistants, recommendation engines and natural-language search are just some of the use cases.
Leveraging generative AI is all about being able to find the most relevant data in response to questions. Tools and techniques are evolving and pushing the industry forward in terms of how we perform searches and what we can do with the results from those searches. These tools promise significant gains but also pose new challenges. You just need to know how to choose your data and search stack—and choose well.
The Progress MarkLogic team is excited to announce early access to MarkLogic Server 12.0 to provide state-of-the-art search technology for harnessing generative AI in the enterprise. With this release, we open new avenues for retrieving enterprise information and enabling better access to knowledge, enhancing the experience for both employees and end users.
Addressing Generative AI Challenges
Demonstrating authentic business value from GenAI initiatives remains the highest barrier to adoption for more than 50% of companies, an overwhelming majority still battling foundational data quality issues, inadequate risk controls and escalating costs.
Let’s look at these barriers:
- Data Quality: LLMs hallucinate all the time, meaning they make things up and miss subtle but key details as it has no factual knowledge or working concept of truth. The foundational role of data quality for trustworthy AI cannot be overstated in this context.
- Data Security: Many large organizations are cautious with how they use open generative AI and LLM models with private and sensitive data and have clear and strict governance policies that restrict the use of AI in their enterprise to minimize risk.
- Response Accuracy: Inaccurate responses can lead to poor business decisions, reputational harm and serious liability risks. Recently, a national air carrier was sued for misleading a customer with wrongful information generated by an AI-powered chat service.
- Rampant Costs: Tokenization and inference costs can be a significant barrier to adoption. The economics of GenAI operations, infrastructure and vectorization need to align with your business. If you have a database with billions of documents, it could be very expensive to vectorize all content—and it may not be necessary.
Gartner observed that companies who successfully move more of their AI projects into production, achieve more business value and experience enhanced model precision and consistency are the ones who actively use Trust, Risk and Security Management controls for AI to overcome these challenges.
The road to successful and scalable AI projects hinges on improving the quality and accuracy of the GenAI model’s output, enhancing the security and protection of your data and IP investments and keeping implementation costs under control.
To keep an LLM model on task, you must feed it domain-specific, up-to-date, well-governed and tightly secured information.
Harness Generative AI with State-of-the-Art Search
To improve the explainability, efficiency and accuracy of generative AI models and their ability to surface relevant information, leverage best-of-breed toolsets based on knowledge graph technologies and hybrid search through retrieval augmented generation (RAG).
There are many approaches to RAG these days, and they are fast evolving. Combining these new features with the powerful search capabilities of MarkLogic allows you to securely implement the RAG process you need on your data.
The new features in preview in MarkLogic 12.0 enable you to address one of generative AI’s key challenges: finding the right data. Building on a proven foundation of comprehensive indexing and query capabilities, this release of MarkLogic Server introduces native vector operations and relevance-based algorithms. These additions improve generative AI retrieval accuracy and simplify the development of secure AI-enhanced applications.
Search and multi-model data management work in concert in MarkLogic Server. The result is a single, flexible and secure foundation to build any data architecture that will augment the LLM model of your choice with your private data to power intelligent and trustworthy applications.
Because MarkLogic Server works with structured and unstructured data—including geospatial and temporal data that can be retrieved using multiple query languages—you can implement your RAG architecture in a way that fits your data model and metadata maturity. This can be done with full-text or structured queries, through vector embeddings or a knowledge graph or via any combination.
The First Capability Trio Coming to MarkLogic Server 12.0
The first features in the MarkLogic Server 12.0 release are already here to help you build effective RAG systems and achieve high accuracy and relevance of responses returned by GenAI models.
Search is in the DNA of MarkLogic Server. The core architecture of MarkLogic Server is a database with the heart of a search engine. Using the powerful indexing and search capabilities of the MarkLogic platform, we have been working with customers for decades to solve some of the hardest data management and information retrieval challenges out there.
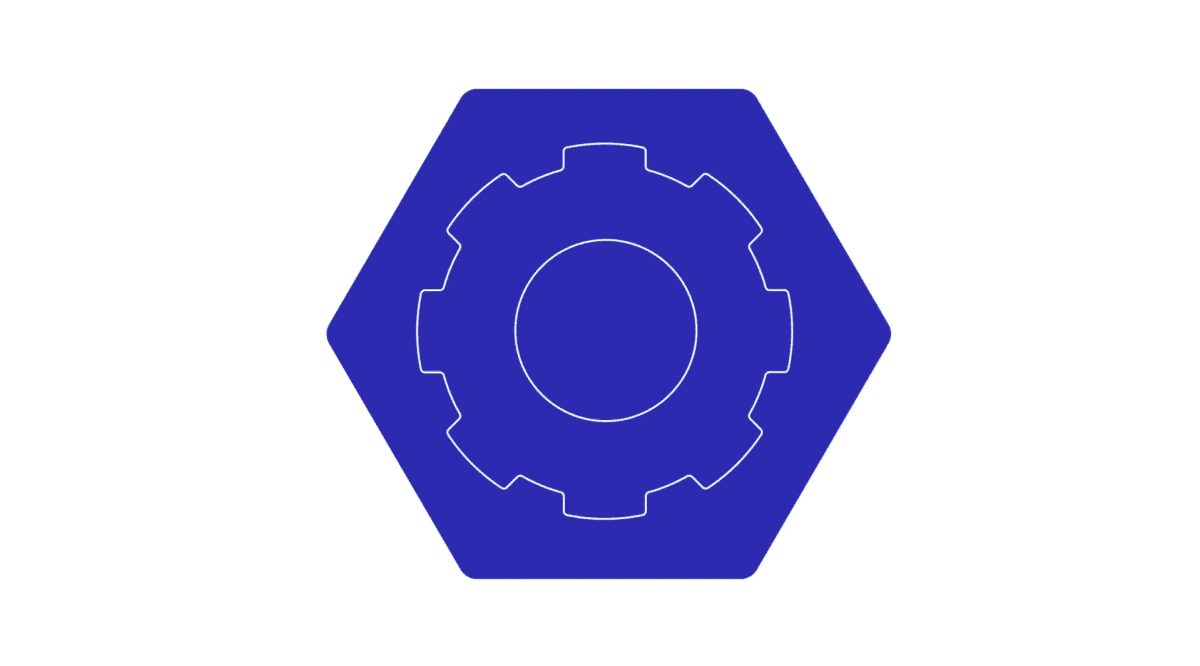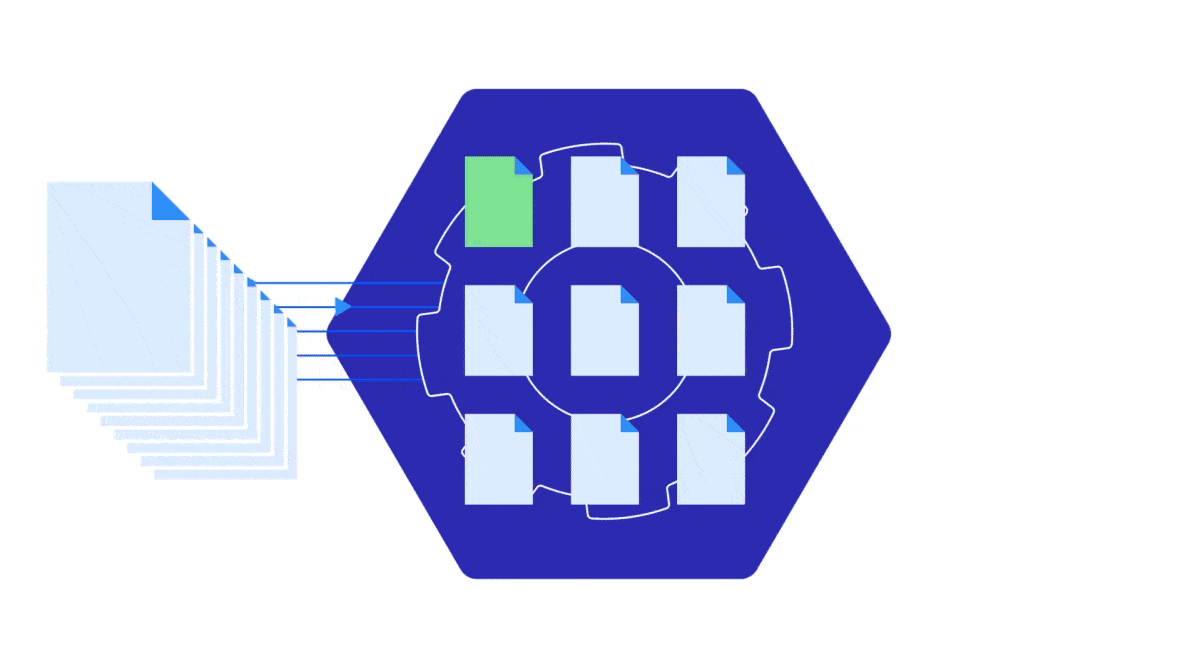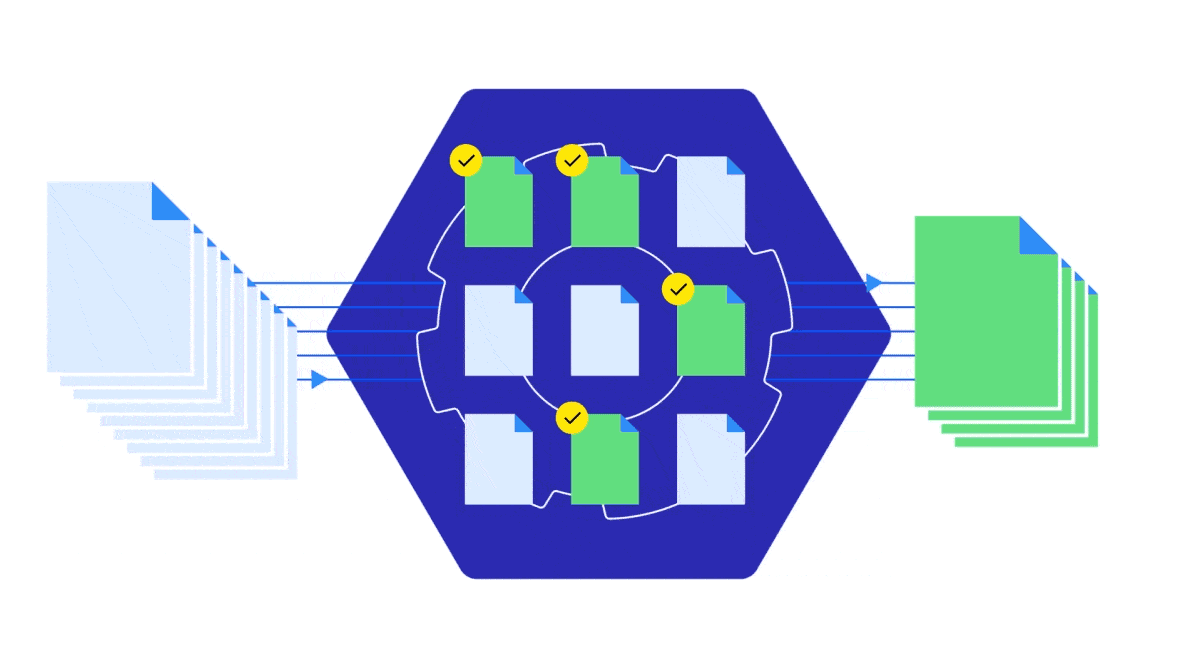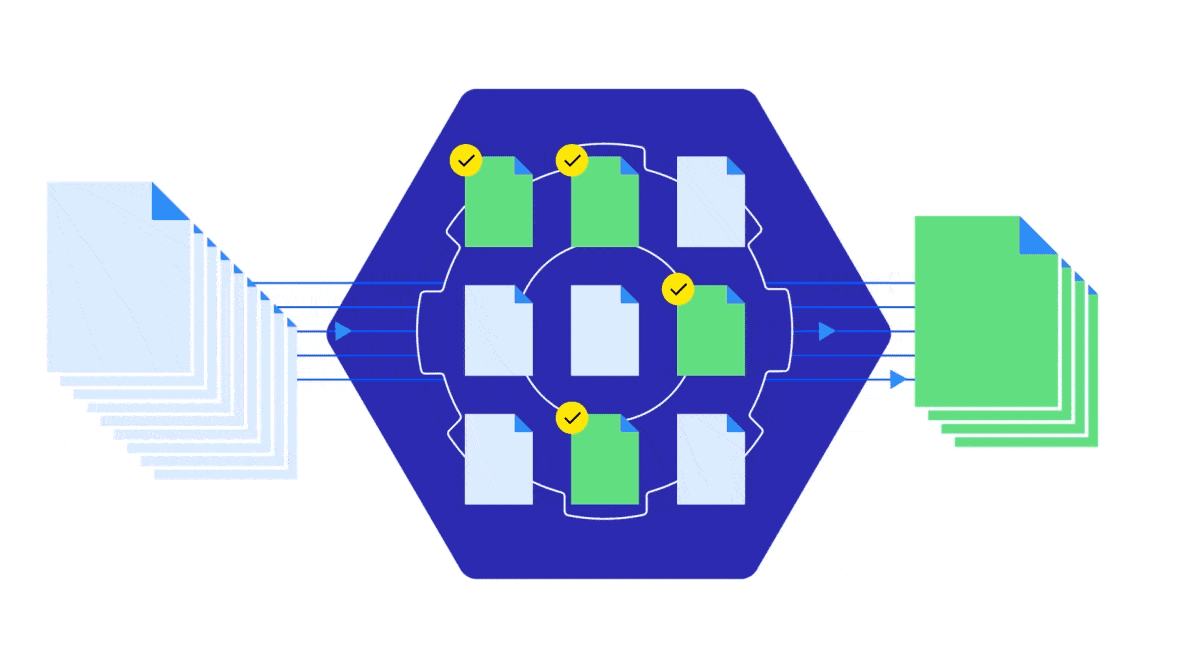
The MarkLogic native search capabilities allow you to perform a composable, hybrid search combining full-text and semantic search with vector operations in a single query to retrieve and re-rank results with maximum recall and precision.
Native Vector Operations

You can now natively perform vector operations in MarkLogic Server, such as storage and distance calculations, to improve generative AI retrieval accuracy. Store vector embeddings close to your data in JSON or XML format and enable large-scale similarity searches for AI systems on vast amounts of unstructured data. Complement with full-text queries through Optic API to rerank results for maximum relevance.
The native vector capabilities in the MarkLogic platform allow you to deliver answers to queries based on similarity search and improve GenAI retrieval accuracy. Developers can utilize MarkLogic native vector capabilities by representing documents or parts of documents as vectors and performing searches against the vectors to find similar documents.
This is the first step towards offering full native vector search in MarkLogic Server. The general availability of the feature will include a K-Nearest Neighbor (KNN) index. Vector search, or similarity retrieval, is a technique used in information retrieval to find items that are similar to a given query item based on their mathematical representations as vectors. This is the most popular technology behind many GenAI retrieval techniques.
BM25 Relevance Ranking
The Best Match 25 (BM25) algorithm is one of the best methods to produce a ranking for the relevance of documents against a query. MarkLogic Server has long had various relevance ranking capabilities built into its universal index, the primary one being TF-IDF. While document length normalization has been a long-standing feature, it is applied at indexing time rather than being tunable at query time.
BM25 is an industry-standard variation on TF-IDF that assesses document length and allows you to tune how the algorithm determines the document length when scoring the query results.
The BM25 algorithm adds more flexibility when dealing with documents of varying lengths. It adds a query time based on document length. Along with document length weighting, BM25 can be specified as a scoring option in all MarkLogic 12.0's search APIs.
Graph Shortest Path Support
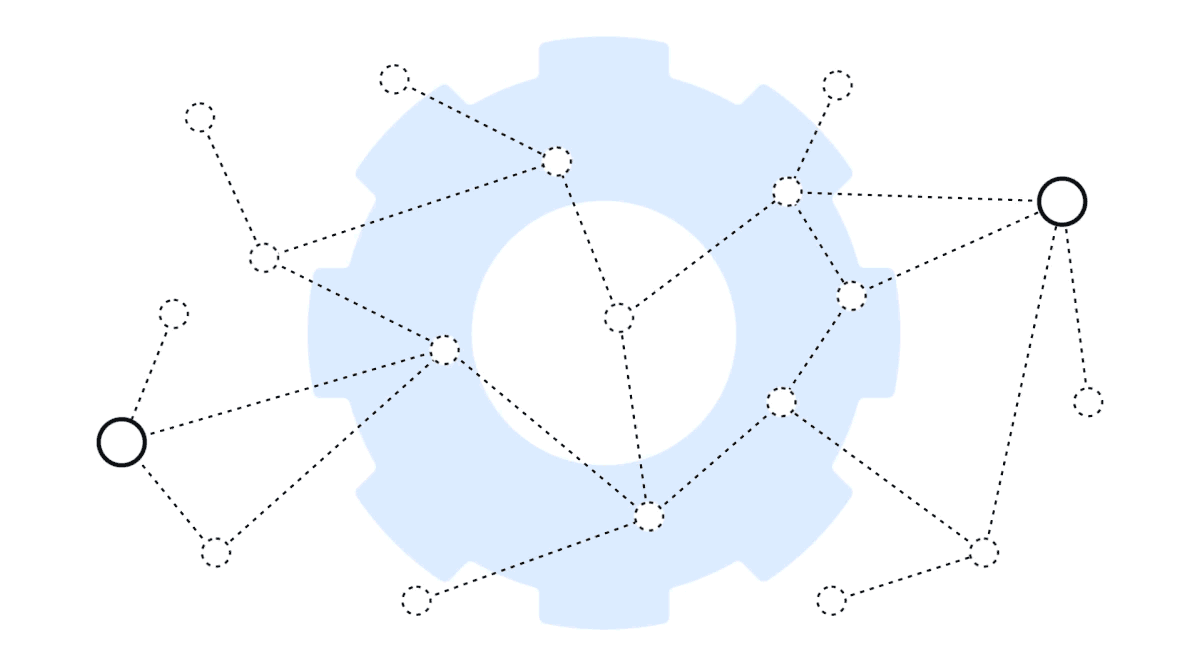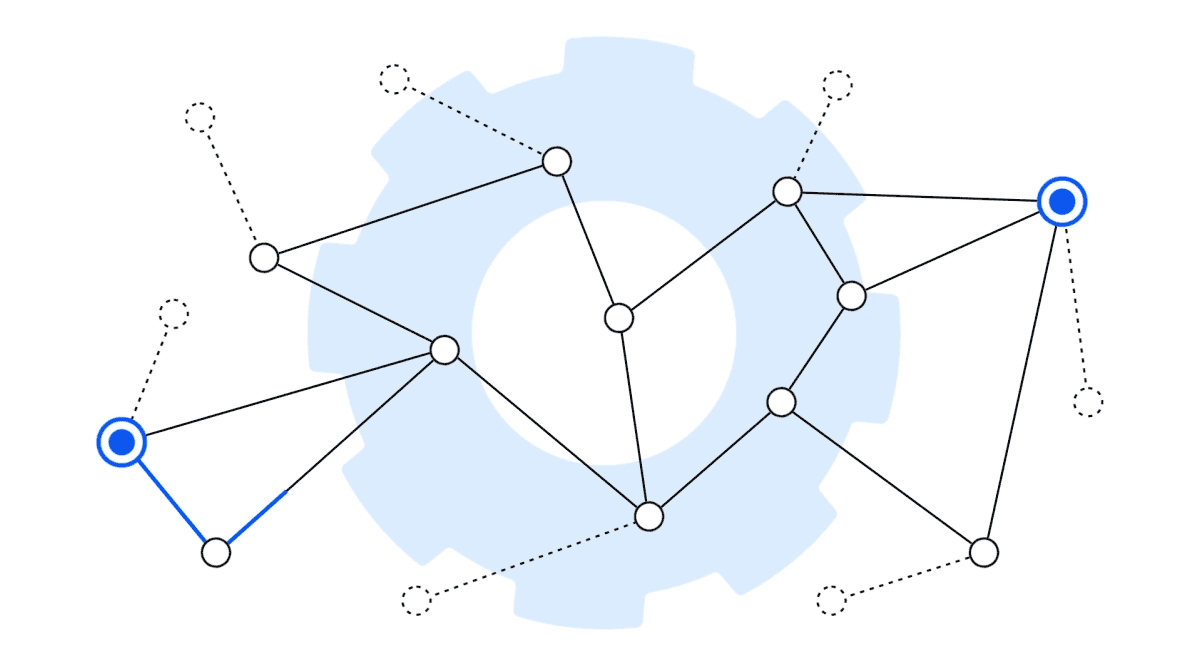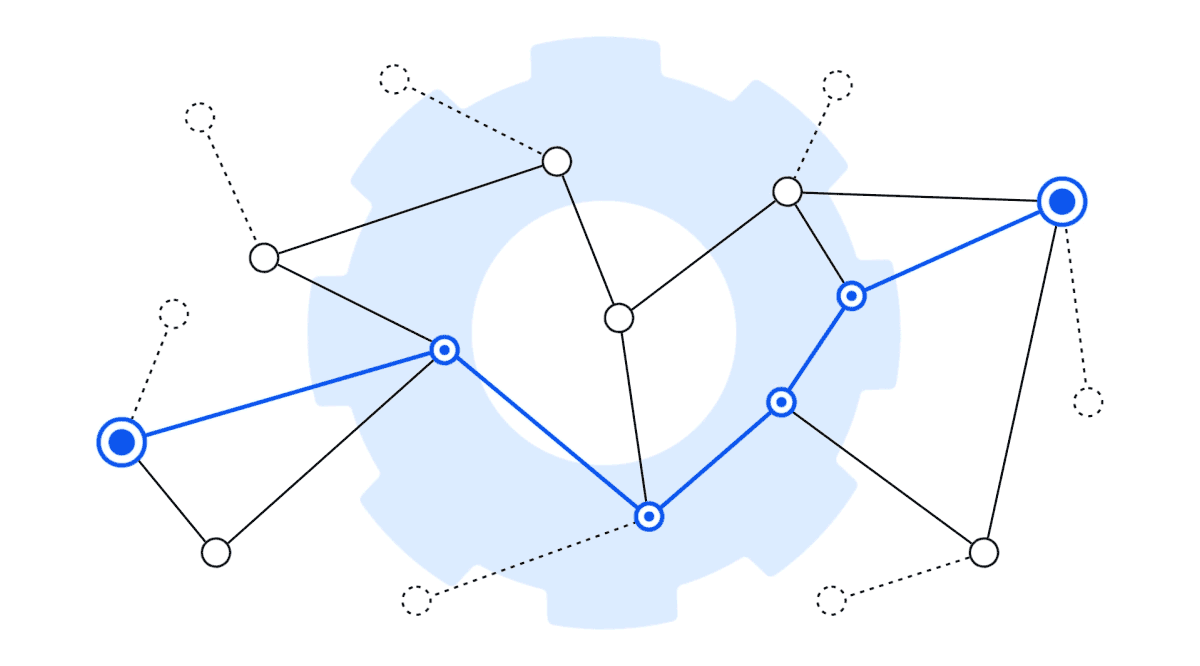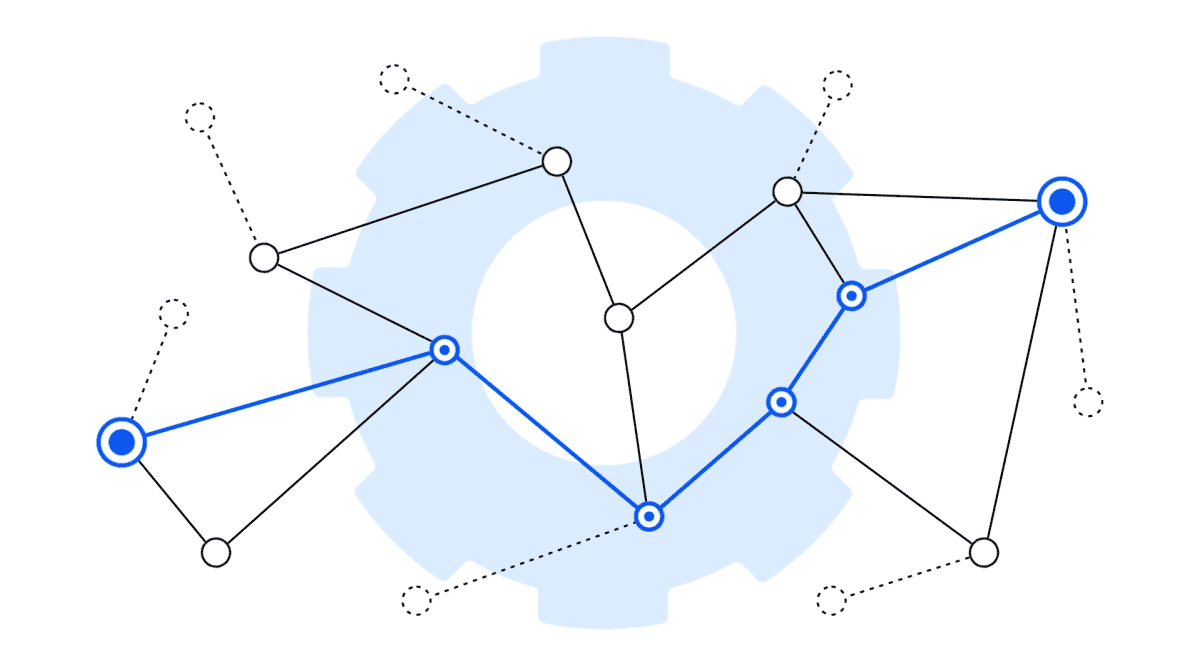
The shortest path graph algorithm is an algorithm that's commonly used in routing use cases such as navigation and network analysis. It allows you to find the shortest path between two nodes in a graph or find the paths to all nodes within a certain number of hops from a node.
When it comes to techniques that identify the most relevant information to feed to LLMs for analysis and summarization, the shortest path algorithm adds yet another tool to the platform. It allows you to leverage and implement different techniques for RAG—whether implemented in combination with a graph RAG process or other innovative RAG approach you might want to apply in the future.
RAG with MarkLogic Hybrid Search
Our goal with the general availability of MarkLogic 12.0 will be to build on our already powerful search capabilities to provide you with the most flexible platform for implementing the RAG architecture you need to meet your business or mission needs. This means we need to be able to find the most relevant data, implement various combinations of indexing and retrieval techniques for different RAG approaches and do it all in one platform.
One way MarkLogic Server supports a RAG implementation is through comprehensive hybrid search that combines keyword-based scoring methods like BM25 with vector reranking operations. This allows you to build your retrieval flow to find both semantically similar concepts and exact matches like proper names and numbers—boosting the most relevant documents to the top of your search result.
Using the Optic API, the unique multi-model query language of MarkLogic Server, you can build a single query that first runs a traditional information retrieval search (full-text and structured queries with optionally weighted terms) and then use vector relevance on top of the initial results to re-rank them. This improves relevance order, without sacrificing recall or precision.
Developers can combine all scores from both searches into one, under one security model, without orchestrating them from different tools. This approach contributes to a faster, easier, simpler and more secure RAG architecture implementation.
This also helps overcome well-known challenges of standalone vector databases or simple vector search. Vector databases perform semantic searches at scale, but can lack profound semantic understanding of the relationships, context and nuance necessary for the accuracy and explainability of the AI-generated responses. They are also computationally heavy which can hurt the performance and scalability of information retrieval and data workloads.
Choosing a RAG approach with the MarkLogic hybrid search is extremely flexible and versatile as it will enable you to leverage all your data with the AI model of your choice. Most importantly, you don’t need to vectorize all your content, which would be unjustifiably expensive.
The takeaway here is that you can implement a MarkLogic hybrid search to:
- Progressively add vectors to your content
- Reduce vectorization costs 2–10x depending on usage patterns
- Easily switch vector embedding models
Graph RAG with Knowledge Graphs
In combination with Progress Semaphore, the MarkLogic platform enables you to implement a graph RAG architecture that uses semantic knowledge graphs and semantic search with SPARQL queries to provide externalized long-term memory capabilities for GenAI. The Semaphore platform generates knowledge models, while the native semantic capabilities of MarkLogic store and visualize the semantic triples and run SPARQL queries against the graph data.
Using knowledge graphs with semantic search for RAG helps surface insights with repeatable confidence and continuously refreshes enterprise knowledge repositories with new facts to contextualize and validate prompts for AI systems. Knowledge Graphs bring superb robustness to a RAG implementation as they:
- Represent computationally efficient, long-term memory
- Are easily updated and enriched with new facts
- Facilitate quality checks and better accuracy
- Consistently retrieve fact-based information with no hallucinations
The newly introduced graph shortest path algorithm in MarkLogic Server can significantly improve semantic search performance and effectively traverse Knowledge Graphs to identify additional facts important to user queries. By incorporating pathfinding search algorithms, RAG systems can significantly improve their ability to provide relevant context to GenAI models, resulting in more accurate, contextually appropriate and efficient responses to user queries.
What’s Coming Next in MarkLogic Server 12.0
Our first early access release of MarkLogic 12.0 is a stepping-stone towards enabling users to maximize the benefits of search capabilities in their enterprise data management systems.
Watch our release webinar to see what’s on the roadmap and get a demo of MarkLogic hybrid search and other early-access features.
MarkLogic for Generative AI
The MarkLogic platform is poised to address other barriers to building trustworthy generative AI applications by improving data quality and readiness. It enables organizations to easily switch between foundational model providers for improved results thanks to its GenAI model independence, hardens security through robust data security controls and accelerates application development with an integrated UI development toolkit.
Learn more about how MarkLogic supports generative AI in the enterprise.

James Kerr
James Kerr is a Software Fellow at Progress and the Product Manager for MarkLogic Server. He has been with the MarkLogic team for nearly 15 years, holding positions in consulting, alliances, cloud enablement, performance engineering and product management. During this time, James has worked with customers to build some of the largest, most complex data management systems on MarkLogic. He now brings that extensive customer experience and operational knowledge from the field to help guide the product into its next chapter as part of Progress.
Related Tags
Related Articles

Latest Stories in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites