
The promise of the paperless office has been a bumpy road, hindered by ever-evolving technologies, employees who don’t like to adopt new processes and customers who just prefer paper. Since policies are documents it is logical they be stored in an electronic document store. In our last post on why you are stuck in document hell, we saw that the Document store was terrific for storing large files of pictures of paper. And not much else.
Electronic document management systems (EDM) that firms acquired in the early 2000s have failed to keep up with the changing needs. Documents became form-driven, yet EDM still provides only non-mutable formats (eg., PDF). And these PDFs grew exponentially due to inbound/outbound of communications (mail, email, fax, efax, etc). Further, due to acquisition and growth of product lines, the number of EDMs within the enterprise have grown – and so have the costs, as traditional EDMs still price by seat.
Consolidations in the insurance industry and the many attempts at digital transformation have impacted all the processes of the insurers who are facing multiple challenges related to documents. Hopes were raised with the rise of NoSQL and Hadoop – but some of those technologies fell flat because they still didn’t allow an easy way to tackle the diversity of documents and processes and “shapes” of the data. Most NoSQL solutions only allowed ingest of a single data model, whereas multiple data models are the norm.
Building an EDM that does offer the 21st century flexibility to search across all your documents (regardless of format) requires a 21st Century Document store. According to Amit Unde, CTO Insurance for LTI, a global technology consulting firm that focuses on digital convergence, the document store needs to be built on a multi-model database platform.
“While metadata is mostly the same, for key entities in Insurance such as policy, product, client info, claim, etc, data elements vary based on the line of business and coverages,” he said. “The multi-model databases are perfect to store these entities, as you can process them based on the common ‘metadata’ without having to force-fit into a single data model.”
But like NoSQL stores, not all multi-model databases are the same. Here are five important considerations your document store should have.
5 Key Functions CIOs Need in an Insurance Document Store
1. Load ‘As Is’ Capability
Whatever OCR or preprocessing workflow is used, you need a document store that can load as is the binaries and the metadata of those binaries, and index the content of the documents and manage the two in a coherent way. In an environment with multiple document sources (inbound, outbound), you need to keep track of the source data. You can harmonize later in the database by using the envelope pattern for example.
By using the envelope pattern, you’re building your canonical data model in an agile way, from the ground up. Your model can meet the combined requirements of all the applications and services that use this data, but each application only needs to understand the parts of the model it uses. And, because there is a consistent canonical form in each record, anyone using the data coming out won’t have to understand the source schemas from the upstream systems.

2. Manage Entity Associations With Semantics
The value of the documents is not only in the binary record and its metadata but also in the content itself. OCR, which is applied on documents for years, can of course help in auto-extracting metadata but more interestingly, the semantic analysis and machine learning helps in correlating document content with client lifecycle. You can do this by extracting concepts and entities that might exist in ERP systems but also sentiments to better understand churn risks.
A multi-model database that can leverage semantic enrichment performed by machine learning models and semantic specialists to perform cross-domain queries lets you mix unstructured and structured sources to get the holistic vision of the customer from both objective and subjective perspectives.

3. Adapting to the Context
“File plan” is a key dimension of EDM strategies in order to ensure proper content governance. However the broader the solution is used, the more flexible the file plan should be. The structure should indeed be able to adapt to the context in which the documents are accessed. We recently deployed an EDM solution for one of our clients where the File plan is generated dynamically-based on the context. The vision had to be contract- or customer-centric depending on the context.
Leveraging semantics, ontologies and inference capabilities we deployed a document structure that can be inferred at query time depending on the context, the actual structure being derived from ontologies.
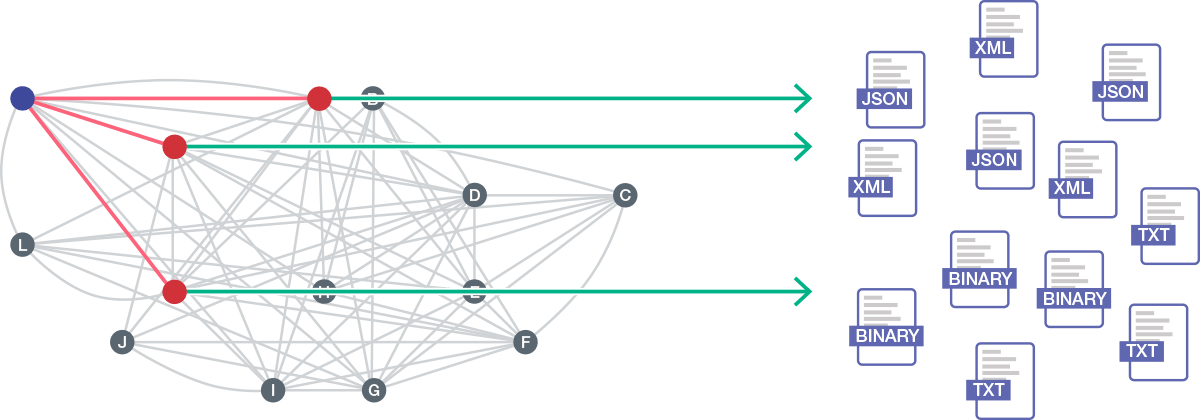
4. Comprehensive Indexes to Search and Query Billions of Documents and Metadata
In order to define sophisticated queries and not sacrifice speed, you need a database that will create a full complement of rich indexes that includes range, geospatial, triples and universal text. By having the index embedded in the database you don’t need to worry about coding separate queries and joining them together at the application level. Look for the ability to have weight query terms for relevance. That way, each user or department can create their own search relevant to their needs, AND save the search for re-use. This helps analysts prioritize and find high value information more quickly. Saved queries in combination with an alerting framework, lets individuals know when relevant documents are ingested into the database. Information can be displayed on a map, graph, network diagram, or even HUD instead of plain text results.

5.Role-based and Element-Level Security on Documents
Documents are sensitive, they can contain personal data, contract conditions details, health details or other confidential information. To avoide confidential data leakage, look for a system that will allow you to only expose those documents that users should see. This becomes even more important if you are consolidating document silos into a document data hub, which would then be processed by multiple departments(from call-centers to claim-clearing departments to litigation departments. This role-based security helps you avoid any confidential data leakage.
Three more security features you should look for are:
- Compartment security: The right content for the right profile In a recent deployment for a insurer, documents were accessed from internal and external users. Some documents such as invoices were open for anyone, some, like litigation reports, were restricted, while others such as health-related information were confidential. In such environment the permissions are derived from the user location, document type and document type metadata. Compartment security in MarkLogic allows to set permissions based on the combination of different compartments.
- Encryption at REST: Protect against inside attackers To protect the data from unauthorized access and steal, look for the ability to encrypt data at REST. A tool like Cryptsoft’s Key Management SDKs let’s you manage data security from across the entire enterprise using a comprehensive, standards-compliant KMIP toolkit. This makes data integration and at-rest encryption easier than with other systems that use multiple key management tools while maintaining the same, or better, levels of security.
- Redaction: Share — but only that which is necessary The insurance value chain involves multiple players which all have to share content – either in part or in whole. When confidential data are involved, data obfuscation is a must. For example, you can use redaction to eliminate or mask sensitive personal information such as credit card numbers, phone numbers, or email addresses from documents. For best practices, look for rule-based redaction. A redaction rule let you tell the database how to locate the content within a document that should be redacted and how to modify that portion. A rule expresses the business logic, independent of the documents to be redacted.

Managing billions of documents – that come in all shapes and sizes, to be accessed by multitudes of individuals requires a flexible, 21st Century EDM. A document database built on a multi-model database system will allow you to transform the way documents are stored, enriched and disseminated so you can make smarter decisions.


Eric Poilvet
Eric is director Solutions Architecture at MarkLogic. He supports the company's customers from the pre-sales phases to the release of solutions. He is involved, among other things, in manufacturing, media and insurance industries on the design of innovative solutions based on MarkLogic operational DataHub.
Eric is currently based in France and previously spent 2 years in MarkLogic London office.
