MarkLogic Node.js API — Working with Binary Documents

In this article, we are going to explore the possibilities that Node.js developers have when it comes to managing and working with binary documents in a MarkLogic database.
When I first started at MarkLogic, I was blown away by how easily the database can ingest structured, semi-structured, and unstructured documents. If you’ve worked with databases before, you know the struggle of persisting binary data. In MarkLogic, that’s very easy — any type of binary can be ingested: PDF, Word document, Powerpoint, MP3, MP4 … you name it.
There’s a lot that could be discussed about how MarkLogic stores binary documents — there is support for small ( < 512 MB by default ) binaries, large binaries, as well as ‘external’ binaries. To learn more about these, please have a look at the Application Developer’s Guide.
Binary Nodes and Properties
There is also something particular about binary documents: they are not searchable because MarkLogic stores them as binary nodes internally.
So what if you have a large selection of videos or music, and you’d like to assign some information to them? Say — the location of where the video was recorded, or the artist of your favourite track — information that you want to search on later on.
MarkLogic comes to the rescue with properties metadata! This piece of metadata is really just an XML document that shares the same URI with a document in a database. The properties metadata has element-value pairs to store information relating to the binary.
Binaries (and their properties documents) are governed by a role-based security model. You must authenticate as a user that has been assigned a role with a read permission on the binary document in order to be able to view that binary document and search across its properties.
Check out MarkLogic University’s series of short video tutorials to learn more about security in MarkLogic.
Going back to the previously mentioned example of the artist of your favourite track, you could have a song in your database identified with a URI such as /song/j-balvin-safari.mp3. This document could have the following properties assigned to it with these element-value pairs:
<artist>J Balvin</artist> <title>Safari</title>
You can add properties metadata during the document insert process or you can also update the document at a later point in time. If a document has properties metadata, you can also see that in your Query Console:

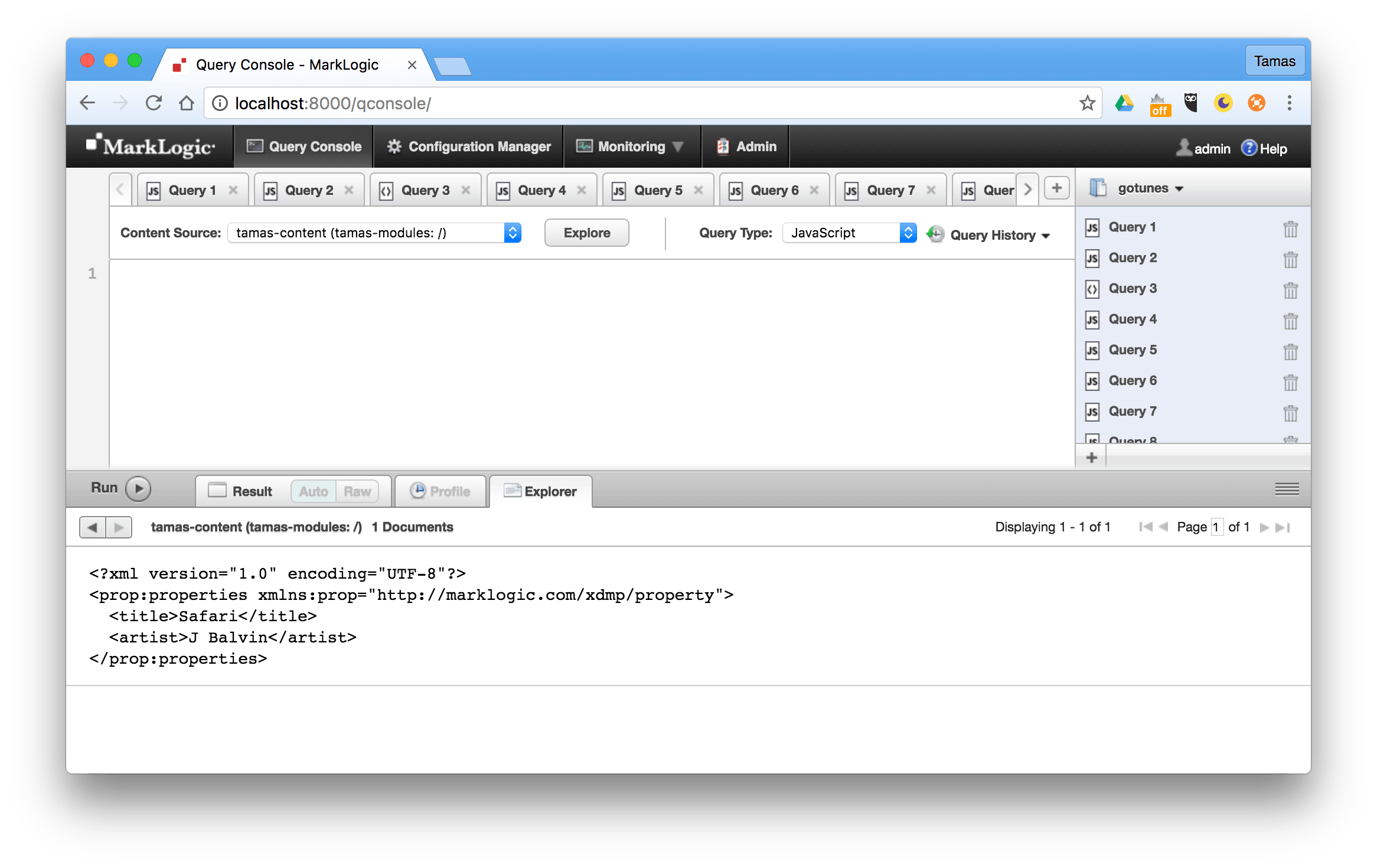
You can take a look at these short, bite-sized video tutorials on how to insert documents and how to update documents using the MarkLogic Node.js Client API.
Extracting Metadata from Binaries
Some binary documents contain metadata by definition — think about a Microsoft Office Word document for example — that has metadata information stored, such as the author, word/character count, last saved time, etc. You can extract such metadata in MarkLogic and store it as properties.
There are quite a few ways that this can be achieved in MarkLogic — have a look at the Search Developer’s Guide’s chapter on binary documents to learn more.
Inserting Documents
If you want to follow this article by way of examples, please clone the following GitHub repository: https://github.com/tpiros/marklogic-nodejs-binaries.
To insert a binary document along with some metadata, you can use the Node.js Client API in the following way:
db.documents.write({
uri: uri,
contentType: 'audio/mpeg',
properties: {
artist: 'J Balvin',
title: 'Safari',
album: 'Energia'
},
content: readStream
})
.result((response) => console.log(response))
.catch((error) => console.log(error));Notice the properties property specified as part of the document descriptor — this is what allows us to assign properties metadata against the binary document.
If you’d like to follow this article and you have already cloned the GitHub repository, you can execute npm run setup to insert some binaries into your database. Please also make sure that you setup the project dependencies, as outlined in this readme file.
Now that we have a few binary documents in the database, let us continue our discussion on how to display the binaries. There are a few options available for you — these are all dependent on what size the binary is and whether you’d like to fully or partially read the binary itself.
Displaying Images
To display an image we can use the MarkLogic Node.js Client API’s stream result handling pattern. (We also have a promise result handling pattern available.)
Using Streams
Generally speaking, it’s good practice to work with streams when reading binary documents — and to ask for chunks of data — these are smaller pieces of data that the database sends to our application. When working with streams in JavaScript, we can also use event listeners via the on() method and we can listen on a few events such as data, error and end. The data event gets emitted each time we receive a data chunk. The example below assumes that we have an image loaded into our database already:
http.createServer((req, res) => {
const uri = req.url;
let data = [];
db.documents.read(uri).stream('chunked')
.on('data', (chunks) => {
data.push(chunks);
})
.on('error', (error) => console.log(error))
.on('end', () => {
let buffer = new Buffer(data.length).fill(0);
buffer = Buffer.concat(data);
res.end(buffer);
});
}).listen(3000);To take a look at this example in action please run npm run image.
Displaying Videos using Range Requests
When it comes to displaying videos using the Node.js Client API we also need to talk about a few other things including partial HTTP GET statements and Content-Range headers.
What is the difference between streaming a binary in chunks (like in the example we saw before for images) or streaming a binary using the Content-Range header?
Well, the difference is important — using range requests (via the aforementioned header) retrieves part of a binary document, which means that you can specify a start and end byte to retrieve, and this gives you the option to get retryable, random access to parts of a binary.
Accessing Part of a Binary
But why is this so important? Well let’s think about this for a moment — let’s assume that there exists a video in our database that we’d like to display to the user. First of all, under no circumstances should we download the entire video for the user — instead we want to download and show the first X amount of bytes — just enough so that they can start watching the video. As they watch along, we want to download the subsequent parts of the video (i.e. buffer the video). Also, what if the user doesn’t want to start from the beginning? We can easily handle that scenario as well by using a Content-Range header.

So how does this work in practice? The MarkLogic Node.js Client API allows you to pass in a range to grab parts of a document:
db.documents.read({
uris: '/binary/song.m4a',
range: [0,511999]
});This would then return exactly the amount of bytes that we have asked for.
Handling Ranges from the Browser
Now comes the tricky bit. How can we dynamically populate the range array displayed in the previous example? We basically need to check for the existence of the Content-Range header and if it exists we need to get the start and end bytes sent via that header and pass that onto the range array.
It is also very important that in this case we return an HTTP header of 206.
Let’s take a look at how this would look like in practice:
db.documents.probe(uri).result().then((response) => {
let {contentLength, contentType} = response;
contentLength = Number(contentLength);
let rangeRequest = req.headers.range;
if (rangeRequest) {
let [partialStart, partialEnd] = rangeRequest.replace(/bytes=/, '').split('-');
let start = Number(partialStart);
let end = partialEnd ? Number(partialEnd) : contentLength;
let chunksize = end - start;
let streamEnd = end;
end = end - 1;
let header = {
'Content-Disposition': 'filename=' + uri,
'Content-Range': 'bytes ' + start + '-' + end + '/' + contentLength,
'Accept-Ranges': 'bytes',
'Content-Length': chunksize,
'Content-Type': contentType
};
res.writeHead(206, header);
let stream = db.documents.read({uris: uri, range: [start, streamEnd]}).stream('chunked');
stream.pipe(res);
stream.on('end', () => res.end());
} else {
res.setHeader('Content-Type', contentType);
res.setHeader('Content-Length', contentLength);
let stream = db.documents.read({uris: uri}).stream('chunked');
stream.pipe(res);
}
}).catch((error) => console.log(error));If you’d like to see this code in action please execute npm run range.
In the code above we are first calling the db.documents.probe() method, which allows us to actually see the Content-Type of the document which later on we can reuse. Further to this we also check the existence of the Content-Range header, extract the start and end bytes, and build our header that we will return along with the 206 status code.
Once that’s done we create a stream by calling db.documents.read() with the stream result handling pattern.
It’s important to note that when returning the 206 status code some calculation is also required to get the right length of data and pass that in via the appropriate headers. So, for example, if we were to request bytes 0-100 from a file that has a total content length of 1000 we need to specify the following headers:
Content-Range: 'bytes 0-100/1000' Content-length: 101
Remember that when specifying the Content-Range you specify the first and last byte inclusive.
Also notice that we have an else statement to cover scenarios where there are no range headers sent.


Working with Metadata
In the beginning of this article, I mentioned that there is a way to store metadata against binary documents — we refer to this as properties.
Using the MarkLogic Node.js Client API it is possible to manage — insert, update and delete — the properties metadata. If you have followed along using the scripts found on GitHub, the setup script has inserted properties metadata for some of the binary documents.
To extract this metadata and display it, all we need to do is to tell our API to retrieve this piece of information:
db.documents.read({
uris: uri,
categories: ['properties']
})
.result().then(data => res.end(JSON.stringify(data[0].properties)))
.catch(error => console.log(error));
If you’d like to see this in action, please execute npm run metadata.
Example Application
All the previous examples have used separate scripts to retrieve metadata or to stream a video. If you are curious, please run the following command npm run app to launch a sample application that uses React and the previously discussed techniques to display information about a video.

The application’s source code is available on GitHub.
Conclusion
When creating applications, you often encounter binary documents in a variety of formats — such as JPEGs, PDFs, and so on. The MarkLogic Node.js Client API allows you to easily manage and display such binary documents in your application — and it also helps you to assign and manage metadata.
Tamas Piros
View all posts from Tamas Piros on the Progress blog. Connect with us about all things application development and deployment, data integration and digital business.
Comments
Topics
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites