
Relational databases are designed for either OLTP or OLAP workloads. You can’t use one database for both. Today, that limitation is no longer acceptable as IT struggles to keep pace with the speed of business.
To recap, in previous posts I discussed two aspects of how relational databases have inflexible data models that are not designed for change, are not designed to handle data variety, and are not designed for scale. In this post, I am going to discuss another problem that has been recognized as a huge challenge in the world of relational databases: mixed workloads.
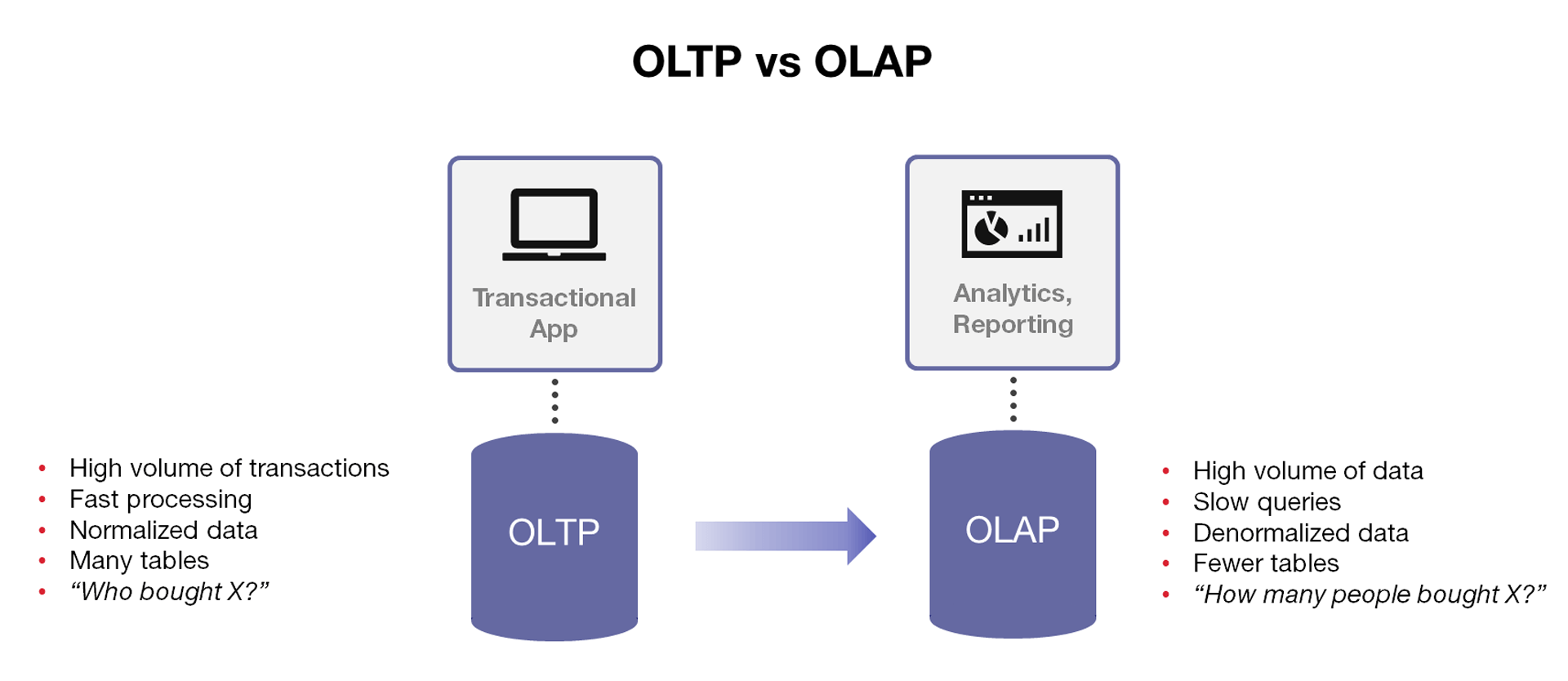
When discussing mixed workloads, it is helpful to differentiate between the two types of workloads that relational databases are designed to handle—operational and analytical. With relational databases, you have to choose which workload to optimize for. You cannot have both. While most people have just come to accept this as a fact of working with databases, it turns out that it is extremely inconvenient and causes a lot of pain for both IT and the business.
Some Background on Mixed Workloads
“Mixed workloads” refers to the ability to handle both operational and analytical workloads. Operational workloads encompass the day-to-day business transactions that are occurring in real-time, such as purchases being made by large numbers of customers. Analytical workloads are those operations intended for business intelligence and data mining, such as when an analyst wants to look at an aggregate of purchases over a specified time period.
In the mid-1990s a clear split was acknowledged and discussed between classes of databases optimized for operational workloads, known as OLTP systems (online transaction processing), and databases optimized for analytical workloads, known as OLAP systems (online analytical processing). OLTP systems are designed for fast transactions. In OLTP systems, data is modeled to be optimal for the application built on it, and generally require consistent, speedy transactions. Contrasted to OLTP systems, OLAP systems are designed for analytics, and have distinctly different schema designs, database sizes, and query characteristics. In OLAP systems, the data is modeled to be optimal for slicing and dicing, including aggregates and trends. It was actually E.F. Codd, the originator of the relational model, who introduced the term OLAP in a white paper in 1993. “Data warehouses” and “data marts” are other names ascribed to certain types of OLAP systems.
There is a great presentation that a MarkLogic customer has given a number of times that includes a graph of where databases (and particular vendor products) fall on the spectrum from operational velocity to analytical volume. If you’re interested in watching the presentation, you can find it here.
Specialized Architectures and Increasing Complexity
As relational databases evolved, so did the database architectures designed to handle each and every different type of workload. There are an endless number of books and articles in which experts agree and disagree on the best ways to model data for different scenarios. You may have heard of some of the types of architectures that have evolved: star schemas, snowflake schemas, and OLAP cubes that are common lingo among professional relational database modelers.
I was at Oracle OpenWorld recently, and I listened to the common plight of DBAs that were told to “just cube it.” Each time a data has to be moved around and remodeled to ask a new question, complexity increases. In today’s world where business have enormous amounts of data and require real-time analytics, this old school approach in which the data model must be reconsidered every time a new type of query is asked is no longer acceptable.
What Actually Happens: Wasting Time on Maintenance and ETL
Unfortunately, the split between operational and analytical systems has contributed to the creation of disparate data marts, data warehouses, reference data stores, and archives that have proliferated out of necessity at most organizations.
The process looks like this…
Data from operational systems was moved via ETL to a central data warehouse designed to be the warehouse for all business decisions. However, that broke down when it could not answer new and different questions that appeared. So, another ETL process was used to move a certain subset of data to a data mart. Other systems were set up to capture reference data. Then an archive system captured all the historical data from all of the systems.
In most organizations, each time a new question needs to be asked or a new application built, a newer, better model is created—and no model is ever the same. What was just a simple schema and handful of databases soon multiplies into dozens or even hundreds. And the whole question of what to do with the unstructured data that doesn’t fit so nicely into rows and columns is largely ignored (or it is stuffed somehow into a relational database where users cannot get much value from it).

The typical situation in today’s data centers: overwhelming complexity
Have you ever asked why most IT departments today spend the majority of their time and money just maintaining the myriad of systems in the organization? The problem is that the relational model forces complexity upon IT departments because the model was not designed to deliver information to different sets of users in the right way at the right time. They were designed to be specialized, at the cost of flexibility. But in the world of polyglot persistence, having to knit together many specialized systems get overly complicated, resulting in “Frankenbeast architectures.”
One Outcome of Complexity: “Shadow IT” and Security Lapses
There are many problems that start to creep in as complexity increase, one of which is that CIOs now have to handle more “shadow IT” and security lapses than ever before. Today, oversight of enterprise data has continued to slip away from CIOs as employees and departments fix their own problems by using software that is not overseen or managed by a centralized IT department.
Most CIOs think they have a few dozen “shadow IT” apps in use, but more often it is a few hundred. In one survey, organizations were found to be using an astounding 923 distinct cloud services, and only 9.3 percent met enterprise security requirements (Skyhigh, June 2015) This change is a direct result of the perceived unresponsiveness to the needs of the business, and creates enormous risk and inefficiencies for the organization as a whole.

This is happening as the cost of a lapse in security continues to grow and cybercriminals use more sophisticated attacks. An organization’s reputation can be severely damaged with just one breach, and a data breach can also be costly. One study found that a single cybersecurity incident can cost a company $5.4 Million on average, or $188 per record. (Ponemon Institute, 2013) Unfortunately, protecting data is harder than ever with the proliferation of data silos that create more entry points, vulnerabilities, and data leakage.
Time to Reset Expectations
It would be way too extreme to say that relational databases are the cause of all the issues with shadow IT and security lapses. In fact, the best in breed relational databases have great security features. But what I’m talking about has little to do with security features. The problems I’m talking about have to do with the accidental complexity that has has resulted from trying to use relational databases for things they were never designed for. With increased complexity, lots of unintended problems start to appear.
Today, organizations are finding that rather than having to setup dozens of different databases to answer each and every question, they can use a database that can handle operational and analytical workloads simultaneously. NoSQL databases can handle mixed workloads, and they can do it quite well. And, the benefit is that it requires a fewer architectural components, less maintenance, less complexity, and faster answers.
It is not the purpose of this post to go into too much detail on NoSQL, but you can read more about how this is done with MarkLogic in this post. Or, you can explore how MarkLogic is used by our customers to create 360 views that rely on MarkLogic’s ability to aggregate disparate data and do both OLTP and OLAP processing on that aggregate data.
Read the next blog in this series that discusses why relational databases are a mismatch for modern app development or download the white paper, Beyond Relational, which covers all of the reasons why relational databases aren’t working in more depth.
All posts in this series:
- RDBMS Are Not Designed To Handle Change
- RDBMS Are Not Designed for Heterogeneous Data
- RDBMS Are Not Designed For Scale
- RDBMS Are Not Designed for Mixed Workloads
- RDBMS Are A Mismatch for Modern App Development

Matt Allen
Matt Allen is a VP of Product Marketing Manager responsible for marketing all the features and benefits of MarkLogic across all verticals. In this role, Matt interfaces with the product and engineering team and with sales and marketing to create content and events that educate and inspire adoption of the technology. Matt is based at MarkLogic headquarters in San Carlos, CA and in his free time he is an artist who specializes in large oil paintings.
