
Our vision for MarkLogic® is and has been to make it the best database for integrating data from silos. This naturally led us down the path towards Master Data Management (MDM) as organizations started choosing MarkLogic to integrate data, harmonize data and match and merge data to deduplicate records.
Recently released, MarkLogic’s Smart Mastering is an open source feature available on GitHub that provides the capability to quickly match and merge data from any domain to create a unified 360 view. And, the feature is easily integrated as part of MarkLogic’s Operational Data Hub architecture—it’s not a separate MDM tool.
The highlights include:
- Multi-domain, multi-model – Smart Mastering is for any data from any domain—this includes customers, suppliers, objects, locations or any other entities. With MarkLogic’s multi-model approach, you can load your data as is, including structured and unstructured data.
- Smart matching – Uses an automated probabilistic approach that relies on AI and fuzzy matching to score suspected duplicate data. It also relies on thesaurus lookups for name variations and various algorithms for non-person entities such as double metaphone, levenshtein distance, smart date matching, field weighting and score backoff. The result of the matching process is a relevance-ranked list of results with confidence scores for suspected duplicates.
- Smart merging – Uses an automated, non-destructive process to merge matching entities above the confidence threshold. It creates a third instance of the data (stored as JSON or XML documents) that includes the original source data and a full history of changes, along with a new section in the document for the mastered data. Metadata is also included to indicate counts and versions as necessary. Selecting the best version of the data is flexible and rules-based—you can keep the newest piece of data, the one that conforms to a particular format or keep all versions.
- Ability to unmerge – If a change is made (like when new information becomes available), you can unmerge records with one simple function. And, because it all happens in the MarkLogic database, you keep the full lineage and provenance for every step.
- Lightweight and agile – Provides out-of-the-box API libraries and rule configurations to get started. And, it leverages MarkLogic’s approach to data integration, which is much faster and far more flexible than the waterfall relational approach.
- Feature of the Operational Data Hub – It all happens in the context of a MarkLogic Operational Data Hub (ODH), providing massive scalability and performance (think hundreds of terabytes and thousands of transactions per second). It also provides certified data security, including tracking provenance and lineage.

Figure 1: Smart Mastering Process in a MarkLogic Operational Data Hub (ODH)
The MDM Challenge – Exposing the Ugly Truth
MDM—the process of creating a golden master record—falls under the umbrella of data integration and focuses on data quality and data governance. The result is that if you do MDM right, it improves everything from customer service to business analytics. With the rise of big data and the increasing challenges of data integration, this specific aspect of data integration is now a big priority.
Mastering data is not a simple task; it’s much more than just looking at two records and determining which one is the right version of the truth. In reality, it’s quite complex. Let’s look at these examples from various domains:
- Person entity – Everyone has a name, address, phone number, etc. But, someone’s name may differ depending on the context. They may use one name on a driver’s license or other legal documentation and another name on a customer form. It is not only important to sort out who this person is exactly, but also understand that two different records can both “correctly” define the same person. And, it is important to be able to go back and make changes later if a new piece of information becomes available.
- Object entity – Consider a lighthouse that has certain dimensions, including height. It would typically be assumed to have just one height. However, the height would differ based on whether it was recorded at low or high tide, whether it was measured by land or by sea, whether the measurement came from a hobbyist or a scientist and whether it was measured 100 years ago or after the sea level rose and the beach eroded. And, of course, was it measured accurately? What device? What units? It may be impossible to get one “correct” answer. The challenge is figuring out how to use all of the data available to get the most operational value out of it. Seeing the full transactional history of data helps in making the right decisions.
- Place entity – Consider a place such as the greater Los Angeles geographical area. One system may call it the “LA Area” while another system may call it the “LA Basin.” Other systems may use additional variations, perhaps spelling out “Los Angeles.” Another challenge is that one system may call this a “region” and another may call it “RGN” or just “location.” The challenge is, the organization wants to have a single view of this one place on the map, but they may have a purpose for describing it differently depending on the context. None of the names are wrong; they are all “correct.” The challenge is when to use which version of the truth for which use case.
As these examples illustrate, finding “truth” in your data is quite difficult, especially without context and knowledge of upstream data sources. That is why in today’s world, it’s better to use a trust-based approach that acknowledges different perspectives of the same entity. In other words, we can trust that one customer record is the better one because it was data entered into a loan application, whereas another record was just created from a customer-service call. But, we’re not just going to throw out the other record—we just might trust it less for a given purpose.
The opposite of a trust-based approach to MDM is a truth-based approach. A truth-based approach seeks to determine the single source of truth or “golden record.” It also leads to throwing out the data that doesn’t “survive” simply because it’s deemed to not be the best version of the truth. Most leading MDM vendors think about MDM using a truth-based approach. In reality, finding that golden record is as elusive as finding the golden snitch—it’s really hard, if not impossible.
The challenge is that traditional MDM tools have a huge technological barrier to implementing trust-based MDM. The static relational model on which they are built, along with a legacy philosophy, means that they are slow to implement and prone to error. And, standing alone, they are not built to handle operational workloads at the center of the enterprise architecture.
Why Traditional MDM Usually Fails
According to one study, there is a 76% failure rate with traditional MDM. Why is that?
Here are some of the main reasons why traditional MDM fails:
- Slow to implement – Traditional MDM relies on complex relational data modeling, and ETL is required to move data into and out of the system.
- Too simplistic – Rather than using modern AI and machine learning, traditional MDM uses simplistic models that are usually riddled with inaccuracies, sometimes as high as 80% according to one MarkLogic partner.
- No unmerge – Traditional MDM uses strict survivorship rules to determine which record to keep. The loser dies forever. Unfortunately, with a high error rate and in today’s regulatory environment, keeping that old data is really important.
- Weak governance – Provenance timestamps on every table are difficult to model in relational terms and slow to query in traditional MDM tools (they do not have the performance characteristics of a database).
- More silos – Traditional MDM tools still require a database to provide operational data access and a data warehouse for analytics. Traditional MDM tools are really just fancy middleware.
- Not trusted – Each additional silo adds another endpoint, which adds security risk.
MarkLogic’s Smart Mastering Is a Better Approach to MDM
MarkLogic was designed as a database for integrating data, and it so happens that it is also very good for doing MDM with Smart Mastering. But, it’s not a separate solution, it’s a feature of the MarkLogic Operational Data Hub that you can leverage as part of the hub.
Organizations see this as an advantage—they don’t need a full-fledged traditional MDM tool. They are choosing MarkLogic over Informatica to do MDM because it accomplishes the end goal of mastering data faster and with higher-quality results.
The comparison table below walks through some of the reasons why MarkLogic’s Smart Mastering is a better approach to MDM:
| MarkLogic Smart Mastering | Traditional MDM Tools | |
| Fast and lightweight | Yes Mastering happens in the database as a feature of the data hub. | No Slow waterfall approach. Not operational or transactional. Still requires a relational database (and schema). |
| Secure and governed | Yes Full data lineage and auditability since everything happens in the database. | Maybe May not stand up to regulatory scrutiny without enterprise data governance capabilities. |
| Eliminates ETL | Yes Load data as is, do iterative transformation in the database. | NoETL tool required to move data, lack of data lineage. |
| Trust-based philosophy | Yes Probabalistic approach that acknowledges real-world ambiguity and change. | No “Truth-based” approach that defines data sources as either trusted/untrusted or correct/incorrect. |
| “Fit for purpose” | Yes Acknowledges that some data may be right for one use case but not for another. | No Tries (in vain) to create a “golden record” that is a single source of truth for every use case. |
| AI and fuzzy logic | Yes Relevance scoring, database intelligence and probabilistic algorithms for accurate results. | No Simplistic models and deterministic matching that result in poor accuracy. |
| Ability to unmerge | Yes Merge corrections are okay; they can be reversed. No data is ever lost. | No Strict survivorship rules and data loss that is irreversible. |
How Smart Mastering Works
To better understand how Smart Mastering works, let’s walk through how it works at a high level. First of all, it’s important to understand that Smart Mastering is just one significant step on the data integration journey towards creating a 360 view.
Data integration is a very agile process in MarkLogic:
- Define Data Services API – Define the business need and data services required.
- Load, discover, model – Load data as is, search it, do minimum amount of modeling required.
- Map, harmonize, curate – Harmonization and mastering to create a unified 360 view.
- Build Data Services API – Expose data to deliver immediate business value, iterate as needed.
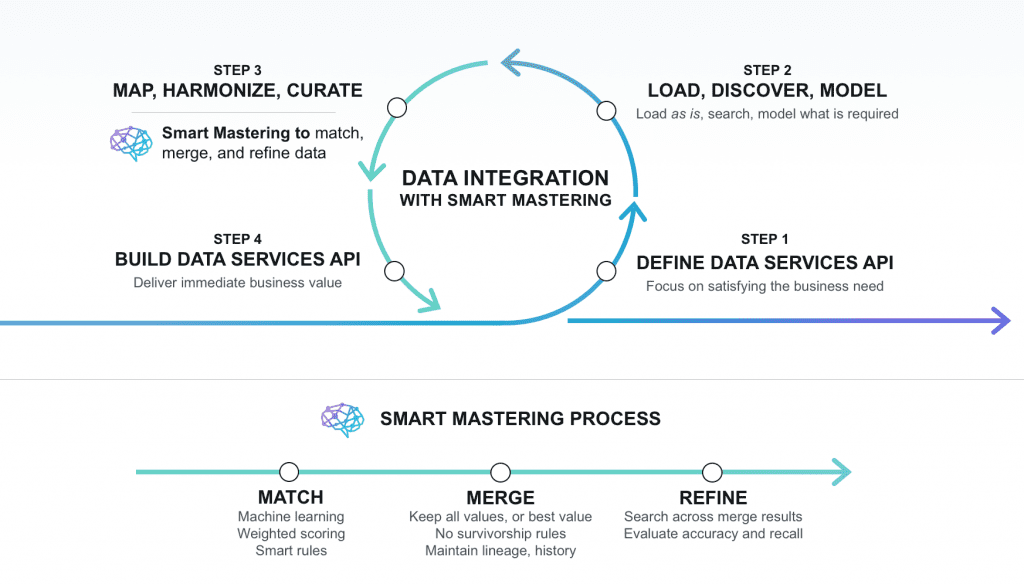
Figure 2: The Smart Mastering process as part of the overall data integration process.
As you can see, Smart Mastering is part of the curation process. The goal of the curation process is to define your entities and build a canonical model. Through an iterative process, incoming data is loaded and searched. A minimum amount of modeling is done to understand the data in the context of existing data, map it to a canonical model and harmonize it to make it consistently queryable. Smart Mastering occurs during the curation phase when similar records are matched, scored and merged. It is an iterative, flexible process that can be repeated and refined as necessary. The result is immediate business value, but with the flexibility to handle later changes.
Once engaged, the Smart Mastering process begins with matching. The feature relies on AI and fuzzy matching to find entities that are the same. To do this, it relies on MarkLogic’s sophisticated indexing capabilities. For Person entities, you can include thesaurus lookups for name/nickname variations or other synonymous values. For non-person entities, there are algorithms such as double metaphone, levenshtein distance, smart date matching and field weighting. Score backoff is included to reduce scores when some elements match but very important ones like date of birth or personal identification number do not (for example, to account for family members or twins who are distinct, not duplicates). Running these matches against batches of records creates a results list with confidence scores associated with the matches and potential matches.
When it is determined that two entities match to a high enough degree of certainty, the merging process kicks off. A third instance of the data is created that includes the data from the two source entities, along with a section at the top for the mastered data. For any values that were the same from both (or more) sources, a source count for each data element is included. The rules that determine which data to prioritize as the “master” (i.e., which data should be noted as being more trusted) go something like this:
- Profile source data and determine the level of trust of each source.
- Prioritize data that most recently changed.
- Prioritize data elements with more details. For example:
- With names, choose “Caroline” over “Carry,” “Robert” over “Bob,” “Michael Harris” over “M. Harris,” etc.
- With addresses, choose “1607 Chestnut Drive” over “1607 Chestnut Dr.”
- With postal codes, choose: “43219-1933” over “03219.”
- Ignore null and empty values of suspect records.
- Ignore ambiguous values (e.g., “123-45-6789” for social security number).
- Mark data with designations such as “inactive” or “inactive-merged” and “active master” to keep track.
There’s obviously a lot more under the covers, and the process (and the APIs used) is determined somewhat by the domain in which you’re working.
If you’re interested in understanding how MarkLogic’s Smart Mastering feature works and also want a deeper dive into some customer examples, I encourage you to check out the presentation given by Kasey Alderete and Damon Feldman at MarkLogic World 2018: Master Data in Minutes with Smart Mastering.
Use Cases for Smart Mastering
Smart Mastering is useful anytime you have disparate entity data that may have overlaps and require deduplication. Every organization can benefit from this capability.
Here are some examples of organizations that are already using MDM with MarkLogic:
- Large energy company – They had 80 separate systems of record with at least 10 different ways of referring to a single piece of equipment. The data was integrated and mastered in MarkLogic, and now the company’s analysts have a single unified view of their equipment.
- Large insurance company – They were faced with the multi-million-dollar challenge of publishing up-to-date, accurate information about providers that was represented differently across systems. The data was integrated and mastered in MarkLogic, and now the company’s analysts have a single unified view of their providers.
- Public state health agency – The had a mandate to collect all information related to a single citizen (healthcare eligibility, criminal records, tax filings). The data was integrated and mastered in MarkLogic, and now they have a single unified view of their citizens.
Smart Mastering for Improved GDPR Compliance
Smart Mastering also has benefits for handling regulatory compliance use cases, such as GDPR. These use cases have similar requirements to “360-view” initiatives and usually overlap.
A recent report from the analyst group, Ovum, highlights the need for proper MDM to address GDPR guidelines, saying, “Failure to associate a piece of data with an individual because it, for example, uses a nickname or a former address can run afoul of [GDPR] requirements to erase, rectify or produce data for the data subject to view.” Ovum’s report goes on, saying “MarkLogic’s architectural approach to mastering further bolsters compliance.”
They note how MarkLogic’s ability to keep all data available, maintain a full audit trail and apply granular security controls makes it particularly well-suited to address GDPR.
Next Steps
Interested in learning more about Smart Mastering? Here are some resources to start with. And, if you’re a developer, we encourage you to download the bits on GitHub and try it out!
- Watch the Smart Mastering Presentation – https://www.progress.com/resources/videos/master-data-in-minutes-with-smart-mastering
- Read the Analyst Perspective from Ovum – https://www.progress.com/resources/papers/smart-mastering-creates-single-view
- Download Smart Mastering Feature on GitHub – https://github.com/marklogic-community/smart-mastering-core

Matt Allen
Matt Allen is a VP of Product Marketing Manager responsible for marketing all the features and benefits of MarkLogic across all verticals. In this role, Matt interfaces with the product and engineering team and with sales and marketing to create content and events that educate and inspire adoption of the technology. Matt is based at MarkLogic headquarters in San Carlos, CA and in his free time he is an artist who specializes in large oil paintings.
