
当社は MarkLogic World において、両製品の最新リリースであるデータハブ 5.0 および MarkLogic 10 の概要を発表しました。この2製品のリリースは、エンタープライズ全体にわたる複雑なデータ統合をシンプルにするという当社のビジョンにおいて記念すべきマイルストーンとなります。
当社のフラッグシップ製品である MarkLogic データハブプラットフォームは、MarkLogic® マルチモデルデータベース上で稼働する MarkLogic データハブを含んだフルスタックサービスです。データの読み込みとキュレーション、およびセキュリティとガバナンスの適用などの目的に利用できるほか、分析および業務関連のユースケースに必要なすべてのデータにすばやくアクセスできる統合プラットフォームです。新機能を活用することで、これらの主要な分野すべてを劇的に改善し、さらにスマートかつシンプルで安全なデータハブを実現することが可能になります。
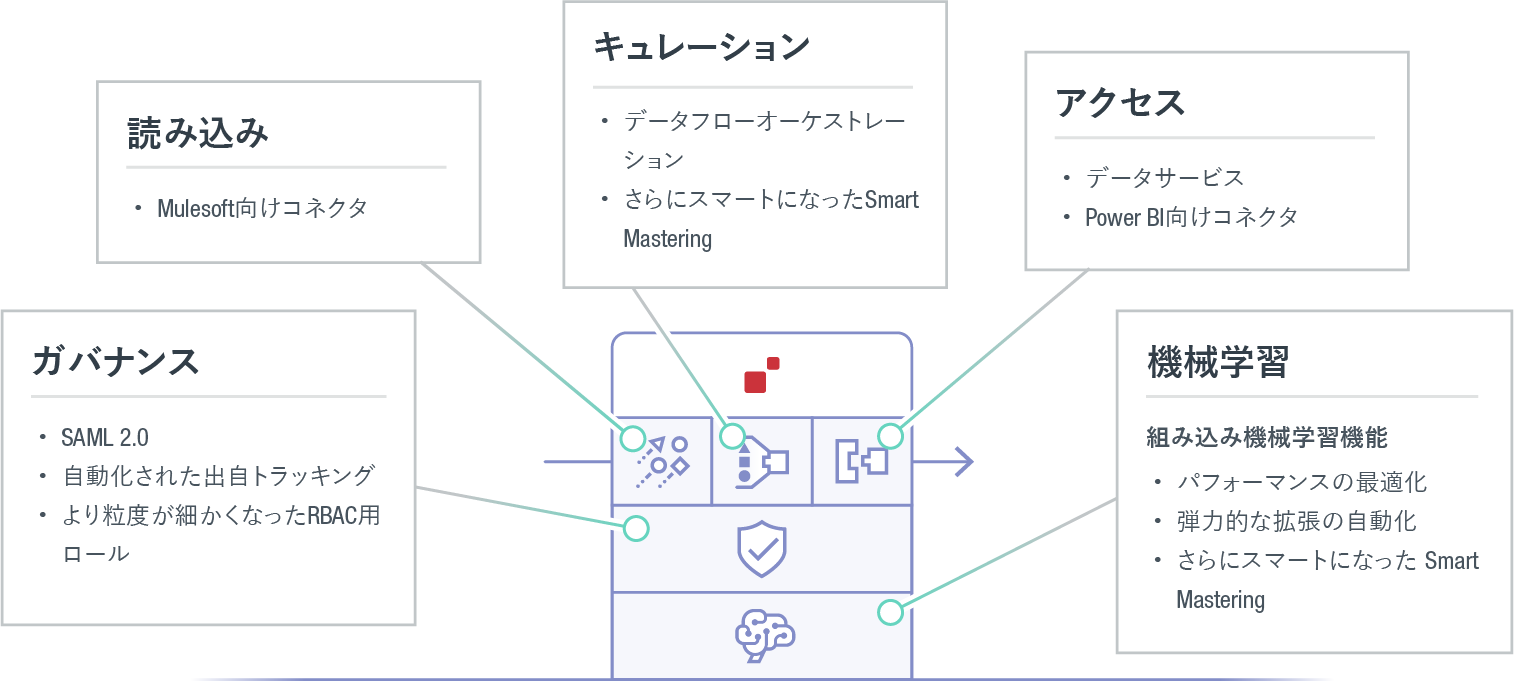
図1:MarkLogic データハブプラットフォームの機能分野ごとの製品に関する主な発表内容
新リリースには多数の新機能が盛り込まれているため、MarkLogic World 19 で行われた製品の基調講演での発表と同じく、新リリースの主なポイントを以下にまとめました。
MarkLogic 機械学習
分析、BI、機械学習機能のいずれを使用する場合でも、ベストな結果を引き出すには、すべてのデータにアクセスでき、それらが高品質な状態に保たれていなければなりません。機械学習からベストな結果を引き出せるようにすることは、データ統合とキュレーションの分野で MarkLogic を業界最高のソリューションに育て上げるという当社のモチベーションにおいて、大きな比重を占めています。以下で説明するように、当社はこの分野への投資を継続的に行っていますが、目指すゴールはそこにはなく、さらにその先の遙か遠くを見据えています。
当社が目指しているのは、機械学習をシステム内部で利用して、主要機能をさらにスマート化して、機能の自動化を推し進めることです。これが達成されれば、ディープラーニングやニューラルネットワークのエキスパートでなくても機械学習のさまざまな恩恵を受けることが可能になるはずです。
そしてもちろん、エキスパートにとっても大いにメリットが生まれるでしょう。今回新たに導入される組み込み機械学習機能により、必要な作業(モデルのトレーニングと実行の両方)をデータベース環境の中心で行えるようになりました。
当社は今後、組み込み機械学習機能を活用して以下のような自動化を推し進めることで、データ管理およびデータ統合のエクスペリエンスをさまざまな面からより強化していくことを計画しています。
- データベースの動作 – MarkLogic 内部で組み込み機械学習機能を利用してクエリの実行効率を高め、ワークロードのパターンに基づいて弾力的な拡張の調整を自動化することを計画しています。弾力的な拡張の調整が自動化されれば、例えば、インフラストラクチャのワークロードパターンのモデルを使用して、データとインデックスのリバランスを制御するルールの調整も自動化することが可能となります。
- データキュレーションの方法 – 組み込み機械学習機能を使用すると、データキュレーションにおけるさまざまなステップの複雑さが軽減され、より高度な自動化が可能になります。例えば、MarkLogic の Smart Mastering 機能においては、ルールベースのマスタリングプロセスを機械学習が補うことでレコードマスタリングの正確性が向上し、処理対象データが増加するにつれてモデルが継続的に改善されます。しかも、これらすべての処理において人間による作業は少なくなります。また、組み込み機械学習機能によって推奨されたマッピング、マスタリング、セキュリティ戦略をデータに適用することもできます。PIIの識別やテキストからのエンティティの抽出を機械学習で支援することによりモデルはさらに改善され、セキュリティもさらに高まります。
データサイエンティストのスピードアップとセキュリティの強化
データサイエンティストにとって大きなメリットの1つは、データベースの内部で機械学習を直接実行できることです。そのため、データキュレーションプロセスに直接関与してトレーニングデータセットを作成し、モデルの評価やチューニングを行い、それらのモデルを適用して結果を入手することができます。また、枝分かれしたデータのコピーを使用するのではなく、データベースの内側で機械学習が直接実行されるため、組織全体の作業効率とセキュリティが向上します。
MarkLogic の組み込み機械学習機能は MarkLogic 10 に標準で搭載されています。データベースカーネル内で安全かつ効率的にディープラーニングを実行するために必要な API もすべてあらかじめ用意されています。
NoSQL データベースのさらなるセキュリティ強化
MarkLogic は、市場で最も安全な NoSQL データベースです。MarkLogic はコモンクライテリアセキュリティ認証を取得している唯一の次世代データベースであり、業界最高レベルのきめ細かなセキュリティ制御が可能です。
MarkLogic の最新リリースでは、出自トラッキングが自動化され、SAML 2.0 が新たにサポートされ、ロールベースのアクセス制御(RBAC)機能も継続的に強化されているため、企業が求めるセキュリティを確保することができます。他の製品ではセキュリティに対する責任がスタックで引き継がれていくのに対し、MarkLogic はデータが存在する場所、つまりデータのすぐ側でデータセキュリティを確保します。
より粒度が細かくなったロール
各ユーザーがシステム内で表示できるコンテンツや実行できる操作はロールに基づいて制御されるため、それらのロールを簡単に作成して管理できることがきわめて重要になります。そのため、データハブ5.0では、基盤となるデータベースに以前から組み込まれていた制御設定を大幅に拡張した、粒度の細かいさまざまな制御設定を利用できます。新しい制御設定では、データハブ専用のロールと責任範囲が事前に設定されているため、ユーザーの権限やパーミッションを適正に管理することができます。これらの制御設定を使用し、データハブで開発を行えば、管理が容易になるだけでなく、セキュリティも向上します。また、当然のことながら、これらの制御設定は MarkLogic データハブサービスでも利用されるため、クラウドのセキュリティもさらに強化されます。
自動化された出自トラッキング
データの妥当性に関する規制当局からの質問に答えるには、それぞれのデータがどこから来たものであり(出自)、どのような道筋を辿って処理されたのか(リニアージュ)を把握しておく必要があります。以降、説明を簡略化するため、このような情報をすべて出自メタデータと呼びます。従来のツールが抱えていた問題は、このようなメタデータが複雑な ETL コードの中に紛れ込んでいて、それらがまったくトラッキングされていなかったり、高度な技術的知識を持つユーザーにしかアクセスできなかったりするために、出自メタデータが失われてしまっていたことでした。
柔軟なマルチモデル方式を採用している MarkLogic はすでに、出自メタデータを管理するためのプラットフォームとして各方面から高い評価を受けています。多くの銀行で取引データの追跡に MarkLogic が利用され、政府機関で諜報の管理に MarkLogic が利用されているのは、そのためです。
データハブ 5.0 は、出自トラッキングを自動化することで、さらに重要な一歩を踏み出しました。データハブでは、読み込み、マッピング、マスタリング処理に関連する出自情報が自動的にトラッキングされます。そのため、追加の処理を行わなくても、データの品質が改善されます。また、詳しい技術的知識を持たないユーザーでもこれらの情報に簡単にアクセスできるようになるため、開発者の手を借りなくても、ガバナンス情報を確認してビジネス上の問題に自ら答えを出せるようになります。
データハブでトラッキングされる出自メタデータの例を以下にご紹介します。
- そのデータはいつ作成されたのか?:キュレーションの対象となったすべてのデータのトランザクションIDとタイムスタンプがトラッキングされます。
- そのデータはどこで生成されたのか?:ハーモナイズされたエンティティがオーケストレーションフローのどこで作成されたのかがトラッキングされます。
- ソースデータはどのように変更されたか?:プロセス全体で、ソースデータがどのように変更されたかがトラッキングされます。
- どのユーザーがそのデータを変更したか?:ユーザーのロールとパーミッションに基づいて、どのユーザーがそのデータを変更したのかがトラッキングされます。
SAML 2.0 のサポート
MarkLogic 10 より、Security Assertion Markup Language 2.0(SAML 2.0)が新たにサポートされたことで、シングルサインオン(SSO)が可能になりましたこの機能強化は、ユーザー名とパスワードの取り扱いに関してさまざまなメリットをもたらします。たとえば、認証情報を入力したり、パスワードを覚えたり、パスワードを更新したり、脆弱なパスワードに対処したりする必要がなくなります。ほとんどの組織では Active Directory ドメインやイントラネットを通じてユーザーの身元がすでに確認されているため、そのログイン情報を再利用することで、安全に他のアプリケーションを使用できるというアイディアがこの機能強化のベースとなりました。MarkLogic は Ping Identity や One Login などのアイデンティティプロバイダとやり取りする際に SAML 2.0 を使用します。
また、SAML 2.0 をサポートするために、MarkLogic では、REST、Java API、Node.js API を介してアクセスできるブラウザベースの認証済みトークンが使用されます。
Thales HSM 向けの暗号化サポート
多くの大企業はすでに鍵管理技術への投資を行っていて、それらの資産を MarkLogic と組み合わせて利用したいと考えています。MarkLogic 9 でさまざまな鍵管理システムとやり取りするための機能が導入されたのに加え、MarkLogic 10 では、Thales の nCipher nShield Connect HSM(ハードウェア方式のセキュリティアプライアンス)も新たにサポートされ、Windows、Linux 両方のプラットフォームで、保存データの暗号化にこのアプライアンスが利用されます。
この新機能により、当社がお客様に提供する鍵管理の選択肢はさらに広がりました。もちろん、MarkLogic の内部キーストアを使用することも可能です。
Thales nCipher nShield Connect がサポートされるようになったことは、クラウドへの移行を進めている政府機関にとって特に興味深い朗報です。このような機関の多くは、Thales HSM でサポートされている PKCS #11 を使用する必要があるからです。PKCS #11 は世界中で最も幅広く採用されている暗号規格の1つです。この規格の仕様では、認証情報を保存および制御する暗号トークンの処理に、プラットフォームに依存しない API を使用することが規定されています。もちろん、その他の業界でも PKCS #11 と MarkLogic を組み合わせることにより、きわめて強固なセキュリティを実現することができます。
データフローオーケストレーションによるキュレーションの簡易化
データフローオーケストレーションとは、その名が示すように、読み込みから使用に至るまで、システム内でデータフローのオーケストレーションを行い、情報がスムーズに流れるようにすることを意味します。データハブ 5.0 では、カスタマイズ可能なローコード/ノーコード(LCNC)のデータオーケストレーションフローが追加され、エンドユーザーがデータソースを簡単にマッピングできるようになっているほか、マッチングの実行やデータフロープロセスのマージも簡単に行えます。
この新機能により、データアーキテクトやビジネスアナリストは、コードを1行も書かずに、事前構成済みの設定に基づいてデータハブをより簡単に利用することができます。
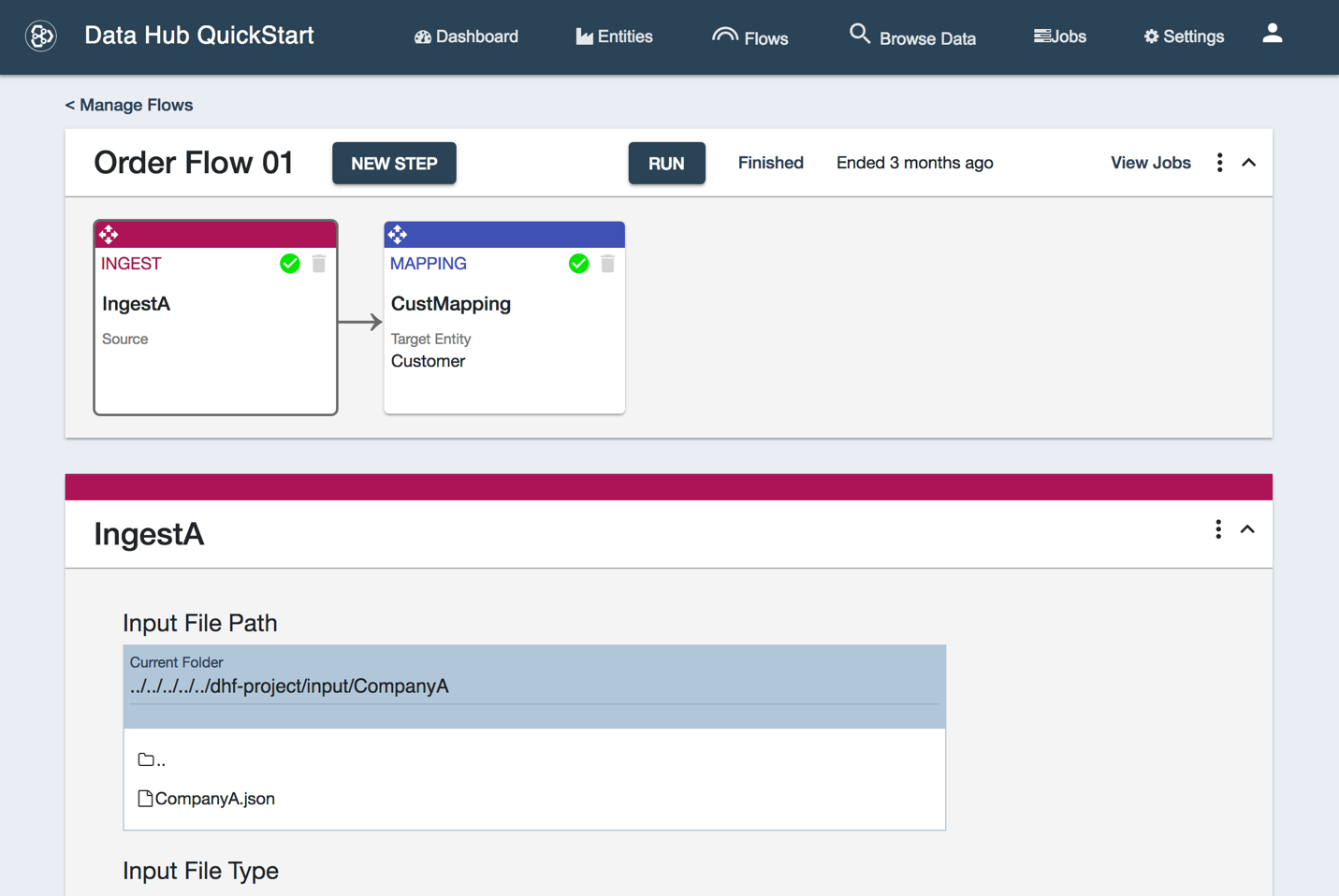
図2:データハブ 5.0 でのデータフローオーケストレーションのスナップショット
仕組みについて
データフローは、データハブのユーザーインターフェイスから、一連のステップとして設定することができます。ステップには次の4種類があります。
- 読み込み:追加のメタデータを使用してデータをラップできます。MarkLogic は重要なガバナンスデータを自動的に取得しますが、ビジネス上の説明、意味的な関連性、データのクオリティ、ソースシステムなどの情報に関連する追加のメタデータも追加しておくことをお勧めします。これらの作業は、このステップで行います。
- マッピング:ソースデータのフィールドをハーモナイズされたエンティティモデルのフィールドに関連付けることができます。例えば、ソースデータで「fname」というフィールドが使用されているものの、エンティティモデルでは「first name」が使用されている場合は、2つをマッピングすることでハーモナイズフローを実行できます。
- マスタリング:このステップを実行すると、すべてのレコードの中で一致する可能性があるものがないかがチェックされ、設定した条件に基づいてそれらがマージされます。データハブ 5.0 以降では、ユーザーインターフェイスに Smart Mastering が完全に統合され、UIからの設定が可能なため、カスタムコードを記述する必要はありません。
- カスタム:データフローを完全に制御したいと考えている上級ユーザーは、きめ細かい設定が可能なカスタムコードモジュールをいつでも実行できます。
フローを設定して実行すると、実行時刻やデータベースにコミットされたレコードの数など、各ジョブのステータスが表示されます。
Smart Mastering – MDM への最新鋭のアプローチ
データハブの Smart Mastering 機能は非常に強力なステップであり、これを使用することで MDM をデータハブから直接実行できます。
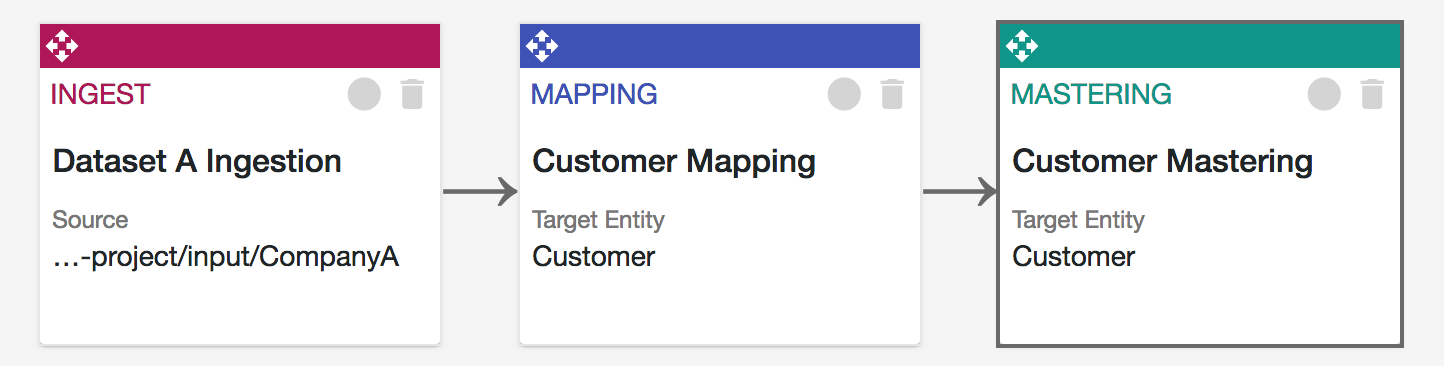
図3:データフローオーケストレーションプロセスにおける別ステップとしての Smart Mastering
マスタリングフローを作成する際の最初のステップは、マッチングオプションとしきい値の設定です。
マッチングオプションとは、2つ以上のレコードが一致しているかどうかを判断するためのルールです。マッチングしきい値では、一致する可能性があるレコードが見つかった場合にどう処理するかを指定します。例えば、しきい値を超えた場合に自動マージをトリガーしたり、通知を送信したりすることができます。
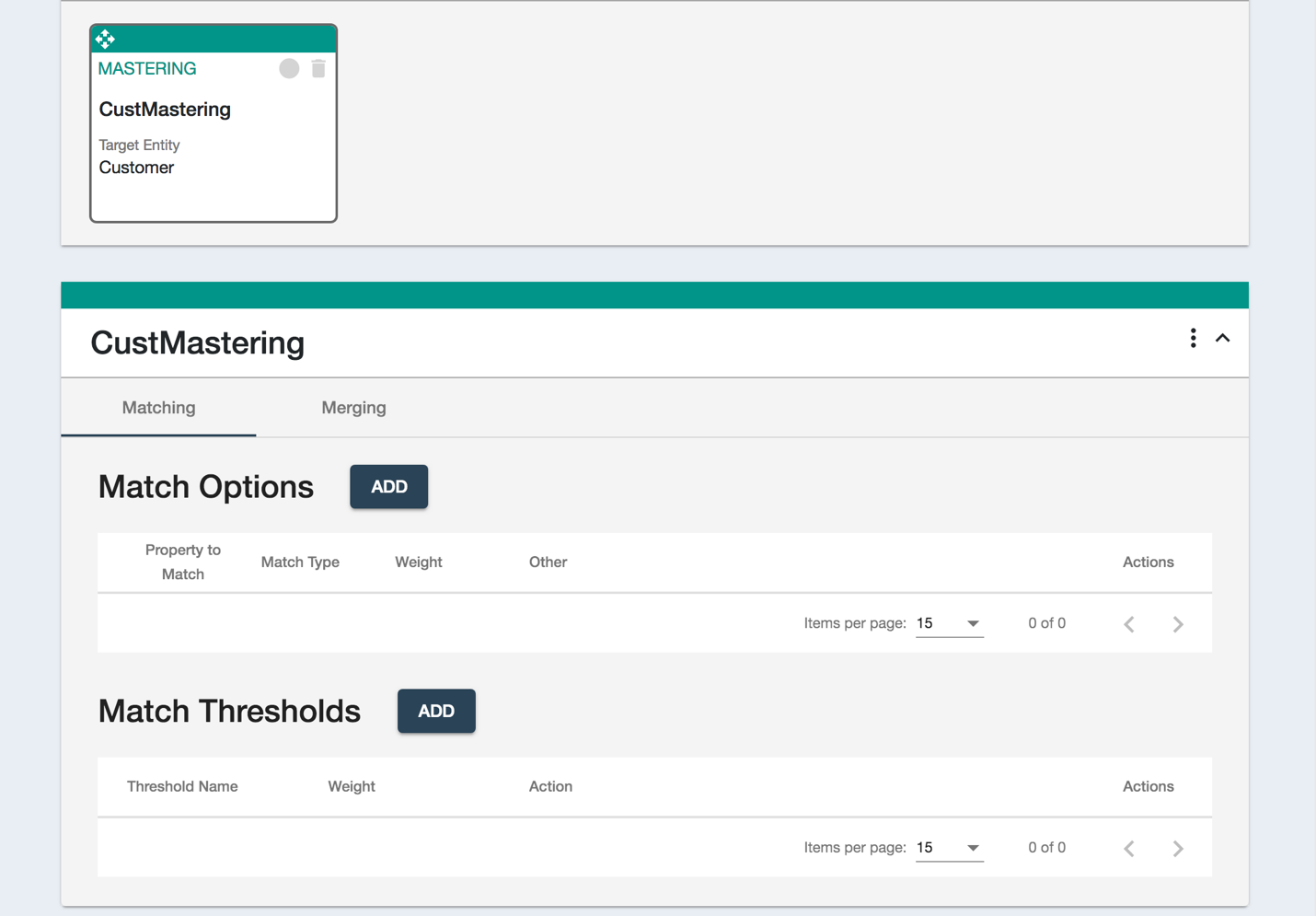
図4:マッチングオプションとしきい値の追加や管理はUIで簡単に実行可能
マッチングオプションを設定した後は、一致する複数のレコードをどのようにマージするかを決定するマージオプションを設定します。
データハブでは、マージが発生すると新しいレコードが作成されます。ただし、(他の MDM システムと違って)このプロセスによってデータが破壊されることはありません。データハブでは、古いレコードのみがアーカイブされるため、新しい情報が出現した場合はレコードのマージを簡単に解除できます。これは MarkLogic にしかない独特の機能です。
Smart Mastering について詳しくは、当社が未来に向けて最初の一歩を踏み出した際の発表資料をご覧ください。
データサービスによるアクセスの改善
MarkLogic のデータサービスは、MarkLogic を既存のエンタープライズ環境に統合するための、新しい便利な方法です。データサービスは、MarkLogic で管理されているデータに対する、パフォーマンスとセキュリティに優れた固定のインターフェースであるため、アプリケーションを利用するように使用できます。
データサービスの最大のメリットは、開発のスピードアップです。これを実現するため、データサービスでは、データの保存に関する詳細情報がカプセル化されており、ビジネスの言葉でアクセスできるようになっています。つまり、データサービスを利用すれば、ビジネスバリューと実装に関する懸念を切り離すことができます。
データサービスはプロセスの改善に役立つだけでなく、通信トラフィックを最小限に抑えられるため、REST や ODBC などの従来型インターフェイスに比べて、パフォーマンスを劇的に改善することができます。また、データサービスのモニタリングと管理には新しい Request Monitoring 機能を利用でき、パフォーマンスや安定性をきめ細かく制御できます。
Request Monitoring 機能
新しい Request Monitoring 機能を使用すると、リクエストの実行中にどの指標を収集するかなど、リクエストに関連する情報のロギングを設定できます。開発者は、サーバー、エンドポイント、またはデータサービスのレベルでモニタリングを有効にして、どのようなイベントや指標をログに記録するかをきめ細かく制御できます。このようにきめ細かい調整が可能なため、ロギングを過剰に使用している場合に発生しやすい「シグナルオーバーロード」の危険を冒さずに、アプリケーションの稼働状況を従来より詳しく把握することができます。また、開発者の場合は、指標のモニタリングと取得に加え、ユーザーエクスペリエンスや SLA に影響を及ぼす可能性があるリクエストをキャンセルすることもできます。
新しいコネクタ – MuleSoft および Power BI
当然のことながら、データハブを構築する際には、データハブと外部システムの間でデータをやり取り必要があります。MarkLogic は先日、ここまでに説明した機能に加え、MuleSoft 向け MarkLogic コネクタ(データ読み込み用)および Power BI 向け MarkLogic コネクタ(データアクセスおよび分析用)の追加を発表しました。
その名前が示唆するように、「データハブ」は通常、特定用途に特化したツールを含む大規模なエンタープライズアーキテクチャの「ハブ」となります。そのため MarkLogic では、業界標準を採用し、主要な業界ツール向けのコネクタを作成することで、大規模なアーキテクチャとシームレスに統合できるようにデータハブの構築を進めています。
Hadoop 向け MarkLogic コネクタ
MarkLogic は先日、MuleSoft との技術提携を発表しました。この提携の第1段階は、MuleSoft 公認の MuleSoft 向け MarkLogic コネクタのリリースです。
MuleSoft の Anypoint Platform は、オンプレミスとクラウドの両方にわたるアプリケーション、データ、およびデバイスで構成されるアプリケーションネットワークを作成する API-led Connectivity の分野において業界をリードするソリューションです。MuleSoft 向けの MarkLogic コネクタを利用すれば、Anypoint コネクタの豊かなエコシステムを活用してさまざまなソースから MarkLogic データハブにデータを読み込むことができます。
MuleSoft 向け MarkLogic コネクタは GitHub で公開されているオープンソースであり、ご興味をお持ちの場合は今すぐ試すことができます。
Power BI 向け MarkLogic コネクタ
Power BI は業界をリードする Microsoft のビジネスインテリジェンスツールであり、ガートナーのマジッククアドラントの「分析およびビジネスインテリジェンス」部門で12年連続「リーダー」の評価を獲得しています。
MarkLogic はこのたび、Power BI 向け MarkLogic コネクタのリリースを発表いたします。このコネクタは Power BI の DirectQuery 機能を利用して、データベースに SQL クエリを直接プッシュすることにより、MarkLogic データハブで管理されているデータへのアクセス、分析、さらには更新も可能なライブ接続を確立します。マルチモデルデータベースおよびドキュメントデータベースで DirectQuery を使用する製品は、MarkLogic が業界で初となります。
Power BI 向け MarkLogic コネクタは、当社と Microsoft のパートナーシップを物語るだけでなく、SQL と Power BI をこよなく愛するエンタープライズ開発者やビジネスアナリストのコミュニティを積極的にサポートしてきた成果でもあり、データにまつわる複雑な課題の解決に向けたイノベーションに取り組む姿勢を示すものでもあります。
次のステップ
これまでご紹介したように、MarkLogic データハブプラットフォームでは、すべての分野にわたって多数の新機能が追加されました。
- 組み込み機械学習機能
- セキュリティの強化:
- より粒度が細かくなったロール
- 自動化された出自トラッキング
- SAML 2.0
- サードパーティKMS向けの新しいオプション
- 従来よりシンプルになったキュレーション
- 新しいコネクタ:
- MuleSoft 向けコネクタ
- Power BI 向けコネクタ
しかし、上記は今回追加された新機能の一部にすぎません。
最近リニューアルされた開発者用サイトより、すべての機能のリリース時期に関する最新情報を入手できます。技術的な詳細につきましては、データハブのリリースノートをご覧ください。

Joe Pasqua
ジョー・パスクワは、エンジニアおよびリーダーとして30年を超える実績があります。彼自身、いくつもの技術革新に貢献していますが、その中には、Xerox社による世界初のパーソナルコンピュータ、初期Oracle社によるRDBMSの勃興、Adobe社によるDTP革命などがあります。さらに、小さなスタートアップ企業からフォーチュン500企業まで多くの会社でリーダーを務めてきました。
直近では、まったく新しい市場の実現を目指す Neustar Labs を創設し、そのための戦略、テクノロジー、サービスを提供しました。それ以前には、シマンテックやベリタスで、戦略担当 VP、グローバルリサーチ担当 VP、20 億ドル規模のデータセンター管理ビジネスの CTO など、責任者の職務を数多く担ってきました。
Joeの技術的な専門分野は、システムソフトウェア、知識表現、権利管理などです。10件を超える特許を持っており、それ以外に出願中の特許もあります。カリフォルニア州立工科大学サンルイスオビスポ校でコンピュータサイエンスと数学の学士号を同時に取得し、現在、同校のコンピュータサイエンス諮問委員会のメンバーを務めています。
