
リレーショナルからMarkLogicへ
本記事は、リレーショナルデータベースのバックグラウンドを持つユーザーに向けたブログシリーズの第3回です。MarkLogicによるデータの統合とアクセスにはどのような違いがあるかを理解するのに役立ちます。
要約:
- MarkLogicは多様で複雑な、変化し続けるデータ構造を簡単に管理できるため、ウォーターフォールアプローチでなく反復型のアジャイル開発ができます。事前にデータモデリングやETLの処理をしなくても、その後必要に応じてデータのモデリングやハーモナイゼーションができます。SQLベースのワークフローで必要とされる一般的なシュレッディングや正規化は不要で、データをそのまま保存してメタデータを追加し、データのハーモナイズとエンリッチを行ってアプリケーションで使用することができます。これにはデータのリネージを改善するというメリットもあります。
- MarkLogicはデータのSQLビューを提供しますが、これはMarkLogicがデータにアクセスして使用するレンズの1つにすぎません。
- 他のNoSQLデータベースと異なり、MarkLogicは真のマルチモデルデータベースとしてすべての要素を一つの実行可能ファイル内で処理します。また、MarkLogicは高速のクエリパフォーマンスを保証する機能を多数備えています
- MarkLogicデータハブプラットフォームにおける重複排除は、データ読み込みの標準プロセスの一部としてスマートマスタリング機能によって処理されます。
「MarkLogicを購入しました。購入後は何から始めればいいでしょうか」
例えばあなたが、テーブル、行列、外部キー、SQLの処理を熟知した長年のSQL開発者として、毎月数千のレポートを作成しているとしましょう。突然、MarkLogicを購入したと伝えられます。
事前にモデリングの必要はなく、「データをそのまま読み込める」というMarkLogicの告知を見たあなたは考えます。「これは魔法か?正確なスキーマを定義してテーブルにselectコマンドを実行することなく、どうやってレポート作成や分析ができるのだろう?」
あなたとチームはMarkLogicを基盤とする新しいシステムの構築にかかります。具体的には何をすればいいのでしょうか?
こうした不安を持たれるのはよく分かります。私も20年にわたってSQLデータベースを手がけ、それからMarkLogicに触れたからです。初めてMarkLogicに触れた時、私は実務に就くまでの1週間で慣れる必要がありました。それは少々衝撃的な経験でした。それまでに学んだ多くの習慣を捨て、新しい方法に慣れる必要がありました。ここではその違いにどう対処すればよいかをご紹介します。
概要 – MarkLogicとSQL
皆さんご存じのように、SQLデータベースのデータが格納されるテーブルは行と列で構成され、SQL select、insert、update、delete、その他のコマンドによってアクセスします。
MarkLogicは、テキスト検索、セマンティックトリプルベースのクエリ、地理情報クエリをサポートするドキュメントデータベースで、あらゆる形式の階層型データを処理できることが一番の特長です。
MarkLogicのドキュメントベースの構造はSQLベースのアプローチに比べて豊富で強力な機能を持ち、より高度な表現に対応できます。融通の効かない行列セットのデータベースに比べて、ドキュメントベースの階層型データベースは、複雑で多様に変化するデータ構造の処理がずっと簡単に行えます。
設計の違い
SQLの開発はウォーターフォール型のアプローチを取らざるを得ません。データにアクセスするにはモデリングとETLプロセスを実行し、データモデルに適合させる必要があります。「MDMの成果を上げるメタデータリポジトリの使い方」 で取り上げたように、これは多くの場合、プロジェクトの開始から最初のメリットの実現までに長い期間(時には数年)を要することを意味します。
対照的に、MarkLogicは高度な反復型の開発アプローチを取ることができます。データに何も処理を加えず、そのまま読み込んでアクセスができるため、必要な処理とデータ変換をするだけで成果物を定義して実装することができます。
もう1つの違いは、大規模なリレーショナルシステムは、モデリング、データ収集とアクセス、マスターデータ管理などのタスクが別々のグループで異なるテクノロジーを使用して行われることが多く、相互の連携が限定される場合がある点です。豊富な機能と柔軟性を備えたMarkLogicのテクノロジーは、これらのすべての機能を統合して同じプラットフォームで処理できる点が優れています。
ソースデータの処理
以上のことをふまえ、ワークフローで最初に異なる点は入手したデータの処理にあります。取得するデータのほとんどはリレーショナル型でなく自然に階層化されたデータで、複雑なXML形式のFpML や FpML/FIXデータ、JSON形式のマーケットデータ、Javaや.NETアプリケーションのオブジェクトベースのデータなどがあります。SQLベースのワークフローは、この複雑なデータをETLプロセスで細分化し(シュレッディング)、それぞれのファイルやオブジェクトを正規化して多くの別個のテーブルに格納できるようにする必要があります。
MarkLogicではこの作業の多くが不要になります。その代わり、(後述のように)データをそのまま変更なしで、あるいは変更を最小限にとどめて格納し、データをフル活用できるようにメタデータを追加します。
データをそのまま保存するのは主に2つの理由があります。
- データに変換やその他の処理をしなくても、全文検索などでデータを活用できます。ETLプロセスの構築を待たなければならないと、データを活かせるようになるまでに時間がかかります。
- データリネージが重視される今日、入手したデータをそのまま格納することで、最終的にデータをどのような形でエンドユーザーに提供するかがずっと理解しやすくなります。
エンティティと関係性
多くの場合、データは他のデータと関係性を持ち、実際に様々な形で関連付けが可能です。リレーショナルの用語では、レコード間の多対多、または1対多の関係で表されます。
1対多の関係には親子関係がありますが、子の親が1つだけである場合もあれば、子が親を持たない場合や、いくつかの異なる親と様々な関係を持つ1対多の関係もあります。
リレーショナルシステムでは、これらの様々な関係は同じように処理されます。データを正規化してテーブルに格納し、外部キーを使用してテーブルをリンクします。
これは優れたアプローチである場合もあります。しかし、データの表現を1つ作成するために複数のテーブルをまとめるという大量の作業が必要になります。
SQL – バニラファイナンススワップ
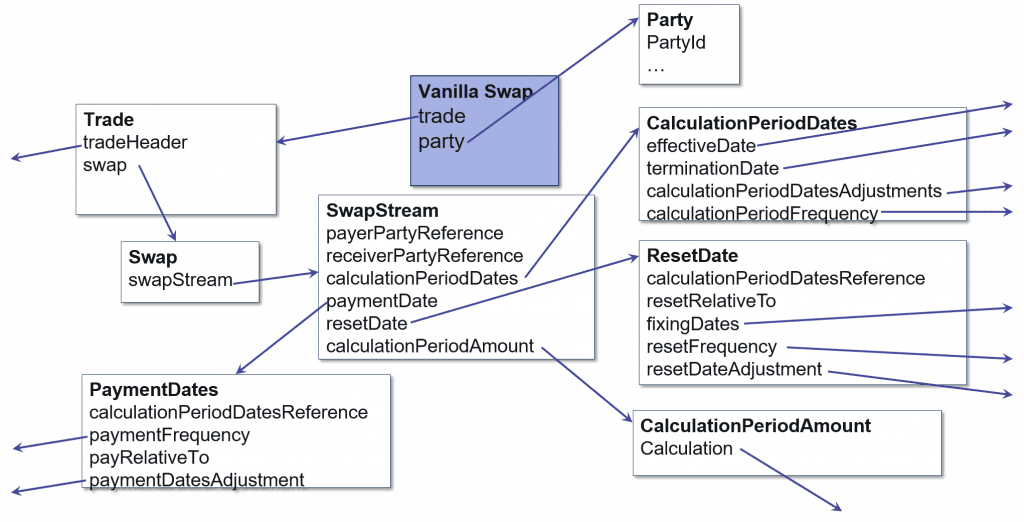
リレーショナルシステムの場合、上記のスワップ には多数のテーブルが必要になることが多く、1回のスワップの格納や集約のために大量のディスクIOが発生します。スワップへのアクセスが頻繁に必要となるアプリケーションでは、スワップを1つのユニットとして格納する方がずっと効率的です。
MarkLogic – バニラファイナンススワップ

このようにデータ構造を低レベルでモデリングすることで、必要な時間が少なくて済みます。データの保護やクエリの実行、ユーザーがデータにアクセスできるようにするために必要なモデリングは行いますが、データベースエンジンが全てのデータソースの全ての属性を正式にモデル化する必要はありません。
MarkLogicを使ってみる
背景を理解したところで、レポートの作成に使用するMarkLogicの機能と、エンドユーザーが必要とするその他のデータアクセスの提供について見てみましょう。
このリストが全てではありませんが、日常的に行う業務がどのようなものかを把握できるはずです。特に次の点を取り上げてみます。
- SQL
- データモデリング
- 検索とクエリ言語
- コレクション
- ディレクトリ
- 階層型データモデル
- セマンティック/トリプル
- フィールド
- 重複排除
SQL – MarkLogicは、ODBCドライバを介してSQLを使用することで選択したデータ属性を公開します。このためのテクノロジーはTemplate Driven Extraction (TDE)と呼ばれます。
TDEはデータの規則性とSQLビューへのマッピング方法を記述したテンプレートを作成して行われます。
企業のユーザーの大部分がリレーショナル形式のデータ利用を想定している可能性が高いことから、複雑なデータをSQLビューで公開する機能はMarkLogicをベースとするソリューションの重要な要素となります。
SQLはNoSQL/マルチモデルよりも制限が多いことに注意が必要です。MarkLogicは多様で複雑なデータ構造をサポートするため、リレーショナル環境よりも効率よくデータストアを構築でき、簡単に維持することができます。
多様なデータ構造のSQLビューは、データにアクセスして表示するためのレンズの1つです。
データモデリング – リレーショナルシステムとMarkLogicのデータモデリングには根本的な違いがあります。最も重要なのは、リレーショナル型のデータモデリングが用いるウォーターフォールアプローチは、データを読み込む前にテーブル内の全ての列を定義する必要があることです。MarkLogicは、データを読み込んでアクセスするにあたってモデリングの必要がありません。モデリングを行うときもビジネスニーズに応じて段階的にモデルを構築する形をとります。
もう1つの違いは、リレーショナル環境では複雑なオブジェクトを分解する必要があり、テーブルが多数に及ぶ可能性がある点です。MarkLogicでは複雑な階層型のデータ構造がサポートされるため、分野の専門家が望む形でデータを格納することができます。この点について詳しくはシリーズのパート2(データモデリング:リレーショナルからMarkLogicへ)で説明しています。
検索とクエリ言語 – MarkLogicでは、SQLビューとして公開されたデータにSQLの「Select」コマンドでクエリを実行できます。
データアクセスの方法はこれ以外に、テキストベースの検索のほか、地理情報クエリ、構造化クエリ、さらにセマンティックデータのSPARQL検索にも対応しています。
MarkLogicの優れた特長の1つは、テキスト検索、クエリやSPARQL検索をすべて1つに統合して実行でき、個々のデータレコードに様々なタイプのデータを格納できることです。
多くのNoSQLデータベースと異なり、MarkLogicは真のマルチモデルデータベース であり、すべてが1つの実行可能ファイル内で動作します。
他の製品は1つのモデルをベースとし、別製品を追加することで他のユースケースに対応しようとしますが、このアプローチでは、異なるデータアクセスモデルを緊密に統合することが困難です。
MarkLogicの機能を存分に活かすために非SQLクエリ言語を使用しなければならないと考えると、戸惑われるかもしれません。ユーザーにデータを提供するための正確なアプローチを決める前に、重要な点を理解しておく必要があります。エンドユーザーはSQLフレンドリーな形でデータを入手したいと考えていますが、多くのユーザーがそうするのは、他にデータを入手する方法がこれまでなかったからです。
多くの場合、エンドユーザーは実際にはオブジェクト指向や階層型のデータを必要としており、要件を満たすためにはSQLベースのシステムからデータを変換しなければなりません。これにはJPAなどの方法がとられることが多く、多大な労力がかかるうえ、保守が難しくなる可能性があります。MarkLogicでは、Javaや.NETなどのオブジェクト指向言語と高い互換性を持つデータを保存することができます。実際、Javaや.NETなどの環境では、XMLやJSONをオブジェクトにシリアル化(またはオブジェクトをXML/JSONに逆シリアル化)でき、JPAよりもはるかに軽量で保守が容易な1つのコマンドで実行することができます。
行列形式のデータを必要としているユーザーには、XQueryやJavaScriptルーチンの出力をcsvなどのフラットな形式で提供し、現在のワークフローと互換性の高い形でアクセスできるようにすることが可能です。
このようにして、エンドユーザーにデータを提供するための最適なアプローチを決めることに時間をかけ、今よりも豊富で便利なデータ提供の選択肢を用意できるようになります。
コレクション – ビジネスインテリジェンス(BI)ツールが大規模のデータセットを扱う場合でも迅速に答えを出せる理由の1つは、一般的な質問に対する答えを事前に演算しているからです。BIツールが行うこの処理にはマイナスの副作用があります。処理速度が大きく低下することでリアルタイムアクセスができず、データを一括して読み込まなければならないのです。
多数のクエリを高速に処理するためのMarkLogicの重要な機能が「コレクション」です。ドキュメントが追加された場合、またはそれ以降のある時点で、そのドキュメントは0個またはそれ以上のコレクションに関連付けられます。ドキュメントが特定のコレクションに属しているかどうかの判断には、必要に応じて複雑な基準を適用することができます。クエリの実行時でなく収集時にドキュメントをコレクションに割り当てることで、コレクションを含めたクエリの処理を大きく高速化できます。MarkLogicにコレクションに属する文書のすべてのURI(Uniform Resource Identifiers)のリストが維持され、collection = ? 形式のクエリを事前に処理することで、ほとんど時間をかけずに実行することができます。
MarkLogicでは、ユーザーは必要なだけの数のコレクションを維持できます。コレクションの使用は設計時に考えるべきものです。新しいコレクションを定義した場合には、コレクションに追加するかどうかを決めるため、既存のドキュメントをスキャンする必要があります。
MarkLogicシステムの適切な設計には、どのようなコレクションがクエリパフォーマンスを改善するかの判断が重要であるため、通常の継続的なワークフローとしてこの判断を行う必要があります。
ディレクトリ – ある意味でコレクションと同様のメリットを持つのがディレクトリです。SQLデータベースのレコードIDは通常、時間とともに増加する整数が使われています。
これは、リレーショナルデータベースでテーブルに定期的にレコードを挿入するとすぐにスペースが不足してブロックの分割が発生し、パフォーマンスが低下することが理由です。
MarkLogicは従来のデータベースとはかなり異なる動作をします。データは常にマシン間を移動し、ブロックサイズはリレーショナルよりも大きいので、ブロック分割はそれほど問題になりません。
このため、MarkLogicでは意味のない整数をドキュメントIDとして使用する制限はなく、より便利な識別子を使用することが可能です。特に、MarkLogicのURIはファイルシステムのディレクトリと似たディレクトリをベースとすることができます。多くの場合、ユーザーはシステムのすべてのドキュメントを評価することなく目的のドキュメントを見つけられます。例えば、「CounterPartyA」による「FXオプション」取引を探す場合、命名規則を使用することで、取引はTrades/FXOption/CounterPartyA/Trade20160901.jsonとして保存されます。
「CounterPartyA」の「FXオプション」取引を探すことが分かっていれば、MarkLogicでは適切なディレクトリに移動してその場所の限られた数のドキュメントセットを確認するだけで済み、データベース全体を検索する必要はありません。ドキュメントのディレクトリ構造をすべてのクエリで活かせるわけではありませんが、これを利用することで実行時間を何倍も高速化できます。
多くの場合、コレクションはディレクトリと同様の利点を持ちながら、より柔軟に使用することが可能です(ドキュメントは複数のコレクションに属することができますが、1つのディレクトリにしか属することができません)。コレクションはディレクトリよりも拡張性に優れている場合もあります。アクセスのニーズを分析して、ディレクトリを実装する価値があるか、メリットを判断するとよいでしょう。読み込み後にファイル名を変えることはできないため、これはデータをMarkLogicに初めて読み込む前に行う作業の1つとなります。
階層型データモデル/データの非正規化 – MarkLogicの特に重要な側面として、1つのドキュメント内の複雑なデータを処理できる階層型データベースであることが挙げられます。階層型にデータを格納することで、(パフォーマンスの大きな阻害要因となる)SQL方式を結合する必要性が大幅に減少します。上記のように、組織に送られるデータの多くはすでに階層型であり、SQLベースのアプローチではデータが行列に細断されます。多くの場合、少なくとも初期の段階では、そのままの形で読み込んだデータを格納するだけで十分です。
この他にも、データを分かりやすくし、クエリのパフォーマンスを向上させるためにデータを「非正規化」することができます。MarkLogicにおいて「非正規化」とは、リレーショナル環境とは意味が大きく異なることを理解することが重要です。 リレーショナル環境のデータの非正規化とは、クエリ処理を効率化するためのデータの複製を意味します。一般に、論理的に複数のデータ要素が同一のものでなければならない場合はデータの整合性に問題が生じるため、非正規化はネガティブなものです。
MarkLogicにおけるデータの非正規化は、子データを親のドキュメントに取り込むことを意味します。これによってデータの重複がなくなり、データの整合性が向上します。子を親と一緒に格納することでデータの理解が容易になるだけでなく、リレーショナルシステムで発生してはならない(それでも頻繁に起こる)「オーファン」(孤児)の可能性が排除されます。
パフォーマンスを最適化し、データの理解と保守を容易にするために、どのデータを階層形式で格納するかを決める時間をとり、場合によってはデータの集約をします。
重複排除 – MarkLogicのプロジェクトには、ほとんどの場合、別個に作成された重複するデータセットを集約する作業が伴います。このような状況では、同じ個人や組織が異なる識別子を持って(異なる綴り名前、異なる住所などの)わずかに違う形で異なるデータセットに存在することがよくあります。リレーショナルシステムでは、重複エントリを排除して個人や組織の情報を判別する作業はデータベースの外部で別のグループによって処理されます。MarkLogicデータハブプラットフォームでは、重複排除は標準でデータ取り込みの一部として行われ、データのハーモナイズが必要であれば簡単に行うことができます。データハブの重複を排除するテクノロジーは「スマートマスタリング」と呼ばれます。
重複排除の必要性はアプリケーションによって異なります。ベストエフォートのみが必要な場合もあれば、2つのレコードの誤ったリンクが大きな影響を与える場合もあります。重複排除にかける労力は、状況に応じて変更する必要があります。マッチングの可能性をそれぞれ人が判断する必要があるか?マッチングがあるか不明の場合、どれだけの時間をかけて検討するか?これらの問いに対して1つの最善の答えがあるわけではありません。
セマンティック/トリプル – MarkLogicでリレーショナルデータベースの外部キーに直接相当するのがセマンティックトリプルです。トリプルは外部キーと同様の機能を提供しますが、外部キーよりもはるかに強力です。トリプルはドキュメントを接続して関係性に意味を持たせるのに使用します。
ハイレベルでは、トリプルは次のような主語/述語/目的語の関係です。
<Swap><isA><FinancialInstrument> . <DerivativesSwap><isA><Derivative> . <DerivativesSwap><isA><Swap> . <Trade1><isA>< DerivativesSwap > . <Trade1><hasACouponPayment><PaymentA> . <PaymentA><hasAPaymentDate><2016-04-05> . <Trade1><hasCounterParty><CompanyA> . <CompanyA><hasARiskRating></risk/companyARating> .
トリプル内の主語と目的語はデータベース内のドキュメントを参照できますが、必ずしもそうする必要はありません。参照する場合、これらは外部キーとして機能します。SPARQL言語を使用すると、SQLのSelectと同じような機能を実行して別々のドキュメントのデータを結合できます。レガシーデータの外部キーに情報が既に存在するため、このようなトリプルを生成することは一般に難しいことではありません。
単純な外部キーに代わる機能のほかにも、リレーショナル方式のクエリを実行するためにトリプルとセマンティックを使用して同義語リストや階層を構築することがよくあります。例えば、異なるデータセットが識別子の異なる同じ金融商品を参照している場合に、トリプルを作成することですべてのバリアントが実際に同じものを参照していることを表し、すべての条件を一緒に検索することが可能です。同義語に対してトリプルを使用する際の重要な点は(以下で説明するフィールドとは異なり)、設計時でなく実行時に関係が定義されるため、関係を継続的に発展させて追加できることです。
階層を使用することで、必要に応じて情報を詳しく分析できます。例えば、 FinanicalInstrument->Swap->DerivativesSwapを使用して上記のような階層を定義した場合、最も狭義の用語(ここでは「デリバティブスワップ」)でドキュメントをインデックス付けして、より広い条件でクエリを実行できます。
MarkLogicの主な特長として、トリプルに対するセマンティッククエリを他のタイプのデータに対する検索やクエリと統合できることが挙げられます。例えば、SPARQLクエリの結果を、ベースとなるドキュメントにXML形式で保存された日付範囲でフィルタリングすることが可能です。
仕事を進める上で重要なのが、データベースのデータ間の関係を定義するトリプルの作成です。この作業の多くはレガシー外部キーで使用されている情報を再利用して行います。ただし、MarkLogicの機能をフル活用するには、データを確認してさらにトリプルを見つける必要があります。
フィールド – 同じ属性が別々のデータソースで異なる形で(あるドキュメントでは customer_id, 、別のドキュメントではcustID のように)定義されている場合、フィールドを作成することで異なる属性名を1つのグローバル識別子にリンクすることができます。フィールドをメモリ内の範囲インデックスに関連付けることで、フィールドに対するクエリを高速に実行するのも一般的な方法です。
トリプルを使用して同義語を定義するのとは異なり、フィールドは設計時のツールであり、極めて重要なデータ属性に限定する必要があります。
今後、フィールドやトリプルを使用してどのデータ属性を1つのユニットとして処理するかを決めるため、データを分析する時間を確保することになるでしょう。
整理
MarkLogicで行う通常業務レベルのワークフローを一通り紹介しましたが、ここでいったん整理してみましょう。MarkLogicの一般的な設計アプローチは、データをできるだけそのままの形で読み込みエンベロープパターンを使用して広くユーザーが利用できるようにする形をとります。
注目すべき重要な点は、広範なデータモデリングとETLを利用する必要があるリレーショナルシステムと異なり、データを読み込むとすぐに大きな価値が得られることです。MarkLogicのユニバーサルインデックスにより、読み込んだデータをすぐに検索してクエリを実行することができます。データベース管理者がデータの内容を理解しなくても、Googleのように検索を実行できます。データの内容を理解しているユーザーは、データの記述子(XML/JSON属性やcsvフィールド記述子)に対してクエリを実行できます。ユースケースの大部分は、この機能だけでほとんど処理できます。
この基本機能だけでなく、MarkLogicの機能を十分に活用するため、データをそのまま格納したエンベロープパターンとメタデータを使用してハーモナイズを行い、元のコンテンツをエンリッチする方法が一般的にとられます。データをそのまま読み込むフレームワークの背景にある主な要因は次のとおりです。
- メタデータを構築する間に、上述のようにデータを使用してアクセスが可能。
- データリネージの提供に関する要件の増加。
リレーショナルシステムでは、データがエンドユーザーに提供されるまでに多くのETLステップを経なければならないことがあります。特定のデータ値の出自について疑問が生じた場合、その値が元のソースデータの一部であるか、ETLステップの1つから得られたものであるかを判断することは困難です。
データをそのまま読み込み、変換/拡張されたメタデータを元のデータとともに格納することにより、データのリネージをずっと簡単にトラッキングできるようになります。
エンベロープパターンを使用して複数のデータセットを1つに統合
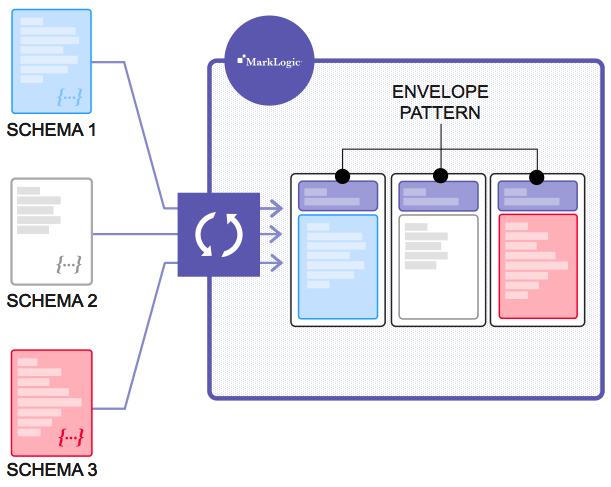
エンベロープのメタデータ部分に格納されるデータには、ユニットの正規化(元データには数百万単位のものや数千単位のものがある)、識別子、その他のデータの変換やエンリッチメントなどの項目が含まれます。
メタデータが定義されると、ユーザーは元のデータと標準の拡張済みメタデータの組み合わせに対してクエリを実行し、一貫した高度なデータビューを取得できます。
ハーモナイズされたレコード
<envelope xmlns="http://marklogic.com/entity-services"> <headers> <sm:sources xmlns:sm="http://marklogic.com/smart-mastering"> … </sm:sources></headers> <triples/> <instance> <MDM xmlns=""> <Person> <PersonType> <PersonName> … </PersonName> <id>208</id> <Address> <AddressType> <LocationState>MD</LocationState> … </AddressType> </Address> <PersonSSNIdentification> <PersonSSNIdentificationType> <IdentificationID>73777777</IdentificationID> </PersonSSNIdentificationType> </PersonSSNIdentification> </PersonType> </Person> </MDM> </instance> <attachments/></envelope>
エンベロープパターンの例として、債券の元のデータがフルテキストの債券名とクーポンのみである場合を考えてみます。これをユーザーが利用しやすい形にするために、債券発行者の識別子(AAPL)を正規化して、ムーディーズの格付けでデータをエンリッチすることができます。
こうすることで、債券関連のドキュメントがエンドユーザーにとってはるかに使いやすいものになります。
MarkLogicの設計哲学に戻ると、一般的に、エンベロープパターンの作業は成果物に焦点を当てて反復的に行う必要があります。ドキュメントを利用するためにメタデータを完全に構築する必要はありません。次の成果物に必要なメタデータに集中する必要があります。
データを読み込んで最初の成果物を提供した後で、ドキュメントを均一にアクセス可能にしてできる限り役立つものにするためのメタデータを構築するというのは、非常に時間のかかる作業です。
まとめ
MarkLogicにより、多様で複雑なデータサイロから最小限の労力で価値を得ることができます。価値を高めるには労力が必要ですが、この作業は、特定の成果物を作成するために必要なタスクのみに焦点を当てた開発スプリントごとに、段階的に行うことができます。各スプリントが完了すると、その結果をデータのすべてのユーザーが利用できるようになり、作成したデータベースは今後の開発の出発点になります。
ある意味、この作業はリレーショナルベースのシステムのものと似ていますが、ある意味では異なります。一般に、従来の技術を使うよりも、プロジェクトの遂行と維持に要する労力を大幅に削減することが可能です。
詳細はこちら
- 本シリーズの他の記事はこちらです。
- パート1 – 技術環境におけるMarkLogic
- パート2 – データモデリング – リレーショナルからMarkLogicへ
- パート4 – データ活用の最適なパートナー
- [ブログ]「そのまま読み込む(Load As Is)」ことの本当の意味 – Load As Is のパターン、JSONとXMLの検証および変換方法、開発を高速化する方法の解説
- [eBook] Building on Multi-Model Databases (O’Reilly)
- MarkLogic ソフトウェアのダウンロード

デイヴィッド・カーレット
デイヴィッド・カーレットは、大手投資銀行、ミューチュアルファンド、オンライン仲買業で、技術職および営業職として15年以上働いてきました。
クライアントによる、ハイパフォーマンスの最先端のデータベースシステムの設計や構築を支援しました。また、パフォーマンス、最適なスキーマ設計、セキュリティ、フェイルオーバー、メッセージング、マスターデータ管理などの問題について助言を提供しました。
