
リレーショナルデータベースからMarkLogicにデータを移行する際、MarkLogic Content Pump (MLCP)の利用時に、元データのCSVダンプや、元データを加工するためのコーディングが必要となります。Apache NiFiは、コンテンツをリレーショナルデータベースシステムからMarkLogicに直接移行するコーディング不要のアプローチを導入しています。ここでは、リレーショナルデータベースからMarkLogicにデータを移行する手順を説明します。
注:次の手順では、MarkLogic v9(またはそれ以降)がすでに実行されており、ローカルで利用可能であることを前提としています。さらに、Java 8をインストールして構成する必要があります。
Nifiのセットアップ
バイナリやソースコードをダウンロードして実行するにはこちらをご覧ください。また、quick guideも合わせてご覧ください。
MarkLogicのダウンロード先及び説明はこちらをご覧ください。
NiFiを実行した状態で、ブラウザーをhttp://localhost:8080/nifiにロードします。スクリプトの新規開始時に空白のページが表示されると驚くかもしれませんが、ロードには時間がかかります。

図1:Apacheのツールバー
NiFiインスタンスが実行されたので、プロセッサの設定を開始できます。利用可能なプロセッサの詳細については、Apache NiFiのドキュメントをご覧ください。
フローの定義
次の手順で基本的なフローを設定します:
- リレーショナルデータベースからレコードを取得
- 各行をJSONドキュメントに変換
- MarkLogicにデータを格納
NiFi Basics:プロセッサーを追加する方法
データフローキャンバスにプロセッサを追加するには、プロセッサアイコン ( ) を画面の上部からキャンバスまで下にドラッグ&ドロップします。
) を画面の上部からキャンバスまで下にドラッグ&ドロップします。
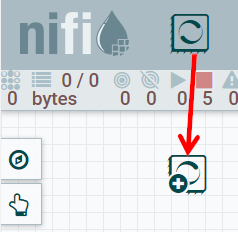
図1:プロセッサをデータフローキャンバスに追加する
これにより、追加するプロセッサを選択するためのダイアログボックスが生成されます(図2を参照)。また、右上の検索ボックスを使用して、表示されるプロセッサーの数を減らすことができます。
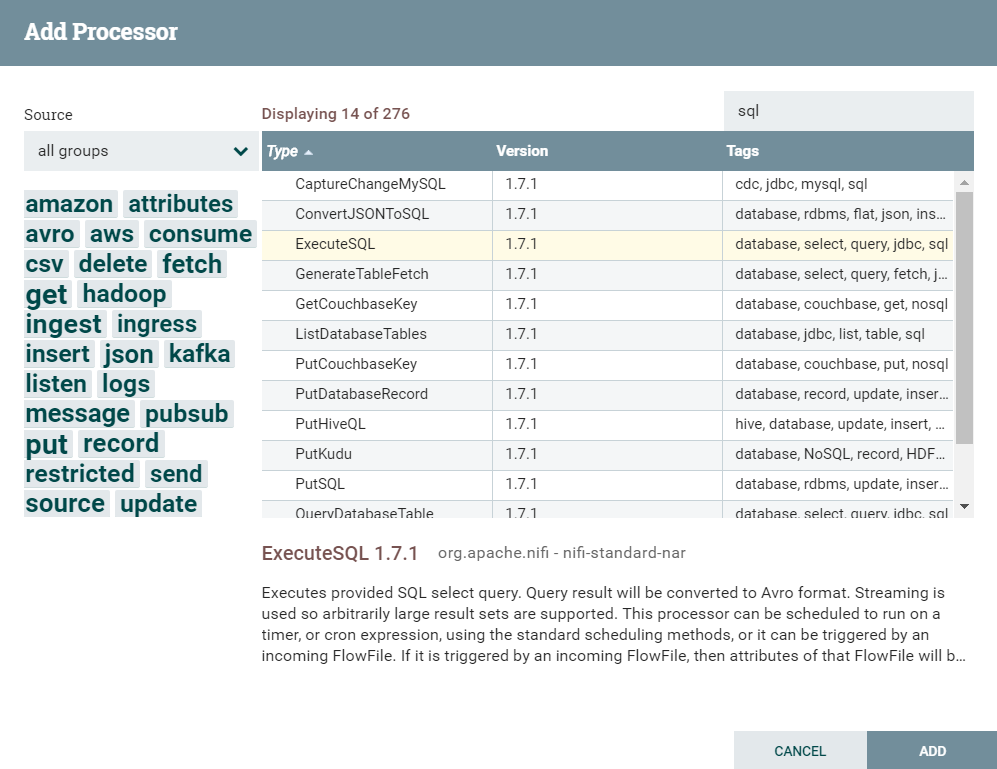
図2:プロセッサーの追加画面
フローステップ1:リレーショナルデータの取得
上の画像に示すように、リレーショナルデータベースからデータを取得するためのプロセッサオプションがいくつかあります。QueryDatabaseTable、およびGenerateTableFetchには、カラムの前回値を記憶するという概念があります。こちらはレコードが更新されないテーブルに有効です。例えば、監査ログなどの、一度処理されたデータが再度処理されない場合などです。
ExecuteSQLプロセッサを追加
データフローキャンバスにExecuteSQLプロセッサを追加します。このプロセッサでは、ユーザーが完全なSQLを提供する必要があり、必要に応じて関連するテーブルを結合する必要があります。ExecuteSQLはデータベースからレコードを取得し、Apache Avro形式でレコードを返します。
ExecuteSQLプロセッサの設定
プロセッサを右クリックして[Configure]を選択し、プロセッサを設定します。
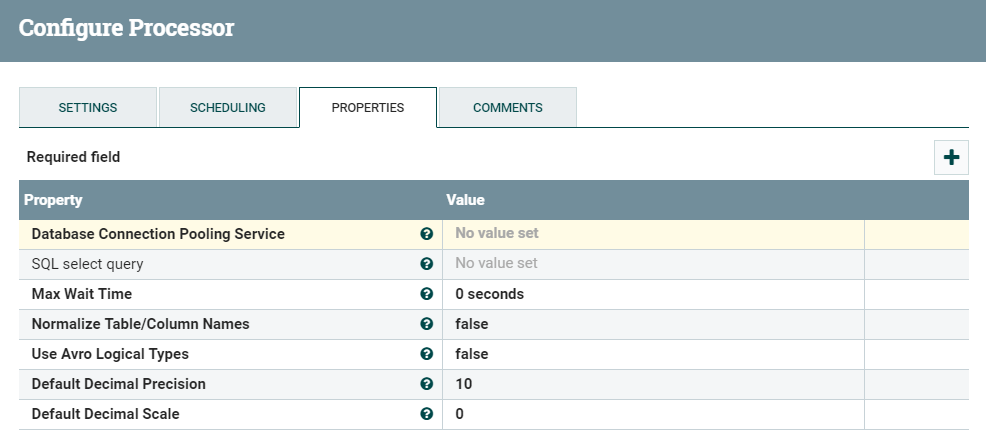
図3:ExecuteSQLプロセッサのプロパティ
「Database Connection Pooling Service」は、「Create new service…」を選択して作成および構成する必要があります。
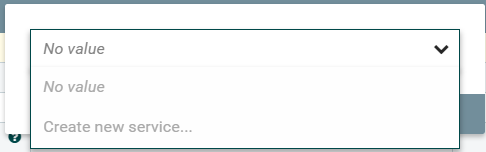
「Database Connection Pooling Service」のプロパティ値については、図4のスクリーンショットを参照してください。データベースの接続URL、ドライバークラス名、およびドライバーの場所を必ず指定してください。以下の例は、ローカルマシンで実行されているMySQLデータベース用です。
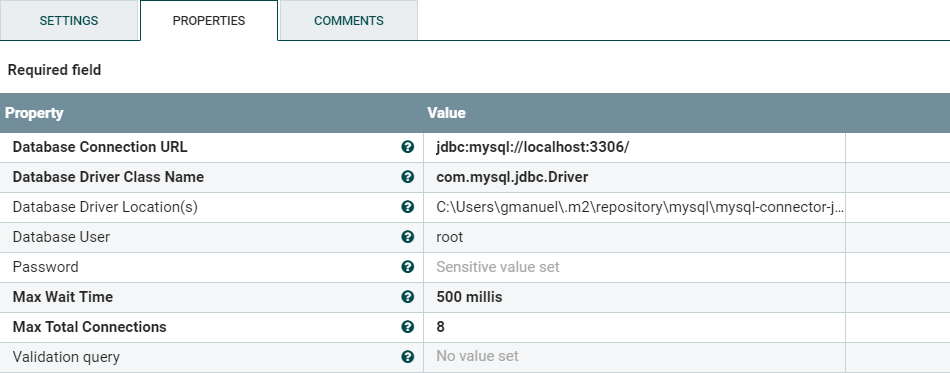
図4:ExecuteSQL Processorの「Database Connection Pooling Service」のプロパティ
重要:構成後にコネクションプールを有効にすることを忘れないでください。
「SQL select query」プロパティ値は、リレーショナルデータベースからデータを取得するために使用される実際のSQLです。select * from employeeのように単純な場合もあれば、5テーブルを結合するような複雑な場合もあります。
多数のレコードがある場合、または非常に長いトランザクション時間が予想される場合は、「Max Wait Time」プロパティを調整することができます。
スケジュールタブを確認して、必要なときにのみ実行されるようにしてください。デフォルトでは、最初の実行が完了した後、ほぼ即座に実行されます。プロセスを1回だけ実行する場合は、「Scheduling Strategy」を「Timer driven」にしたうえで、Run Scheduleを非常に大きい値にするか、固定CRON値を指定することを検討してください。
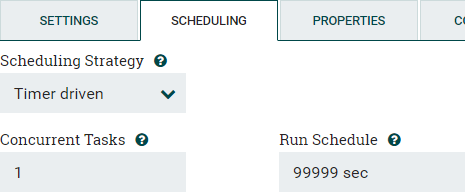
図5:プロセッサスケジューリングの構成
最後に、[SETTINGS]タブを確認し、失敗した場合に自動終了するようにします。
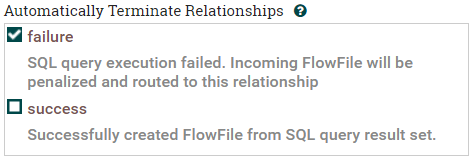
図6:[SETTINGS]で障害時に自動終了
フローステップ2:JSONドキュメントに変換
JSONドキュメントへの変換は2つのステップで実施します。
- AvroをJSONに変換
- 結果セット全体を個々の行/レコードに分割
AvroをJSONに変換
ConvertAvroToJSON Processorを追加し、次のように設定します。
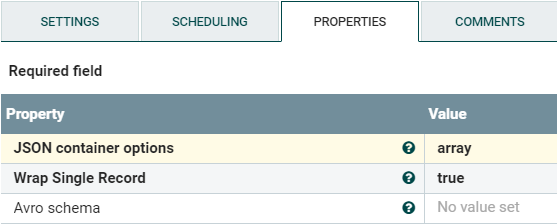
図7:ConvertAvroToJSONプロセッサのプロパティ
「Wrap Single Record」プロパティは配列を処理するために使用します。
- Falseに設定すると、レコードは配列として処理されません :
{"emp_id" : 1, "first_name" : "Ruth", "last_name" : "Shaw", ... } - Trueに設定すると、レコードは配列として処理されます : [
{"emp_id" : 1, "first_name" : "Ruth", "last_name" : "Shaw", ... }]
[SETTINGS]タブで、失敗時に自動終了します。(図6を参照)。
結果セット全体を個々の行/レコードに分割
次の設定でSplitJSONプロセッサを追加します。
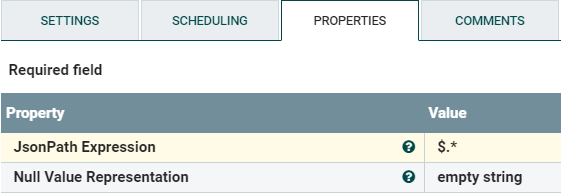
図8:SplitJSONプロセッサーのプロパティ
XPathに精通している場合、この記事はXPathをJsonPathに変換するのに役立ちます。
注:このJsonPathはMarkLogicの範囲外であり、XQuery/Serverside JavaScriptはそのままでは機能しません。
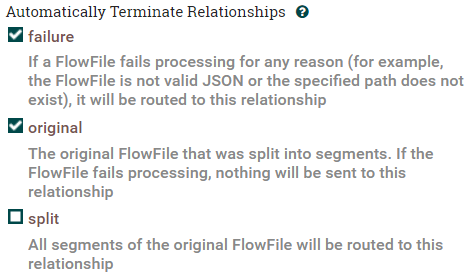
[SETTINGS]でfailureとoriginalを自動終了とする :
フローステップ3:MarkLogicにデータを取り込む
Apache NiFiは継続的に動作することを目的としており、最初のプロセッサは、停止または無効化されるまで、設定された頻度で実行されます。したがって、再実行中の一貫性のために、既存のプライマリキーを結果のドキュメントURIの一部として使用することをお勧めします。たとえば、IDが1の従業員のURIは/employee/1.jsonになります。これを行うために、主キーを抽出し、FlowFile属性の一部として保存します。
EvaluateJsonPath Processorを追加し、次のように設定します。
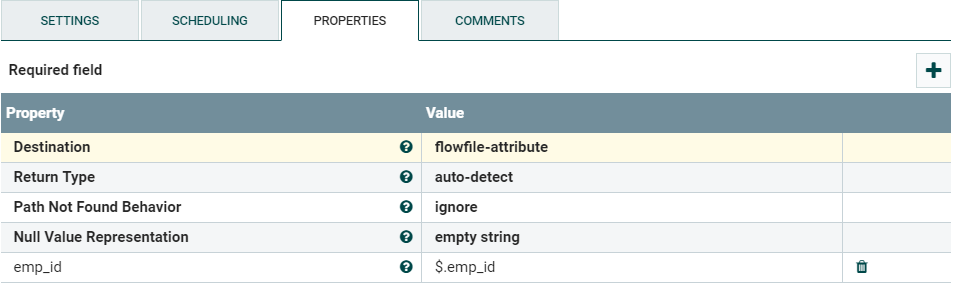
図9:EvaluateJsonPath Processorのプロパティ
「Destination」は、FlowFileのコンテンツを上書きする代わりに、抽出された主キー値をflowfile属性に格納します。emp_id プロパティが「plus」アイコンを使用して追加されます。このプロパティの値は、評価されるJsonPath式です。
「SETTINGS」で、障害および不一致で自動終了します。
最後のステップとして、PutMarkLogicプロセッサを使用してドキュメントをMarkLogicにプッシュします。これにより、MarkLogicのDMSDKがバックグラウンドで使用され、ドキュメントをバッチで記述できるようになり、スループットが向上し、待ち時間が短縮されます。
プロセッサを追加するときに「marklogic」を検索すると、2つのプロセッサが使用できます。
PutMarkLogicプロセッサを次のように設定します。
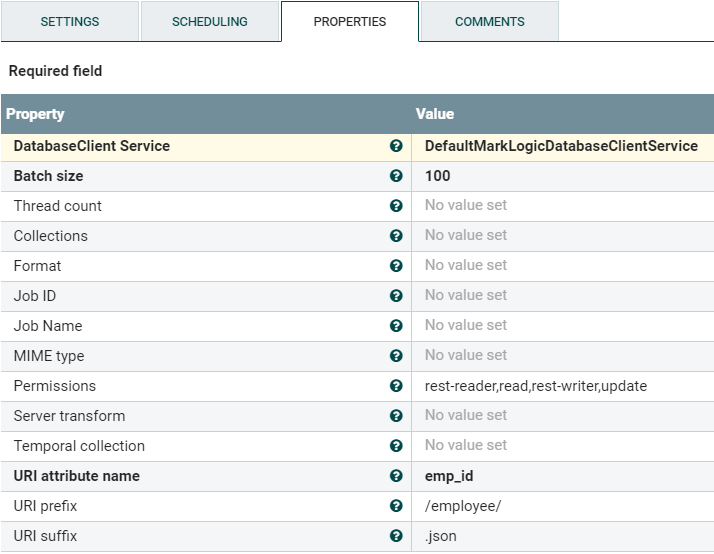
図10:PutMarkLogicプロセッサのプロパティ
「Database Connection Pooling Service」に類似した「DatabaseClient Service」プロパティ値を作成します。次のスクリーンショットを参考にしてください。
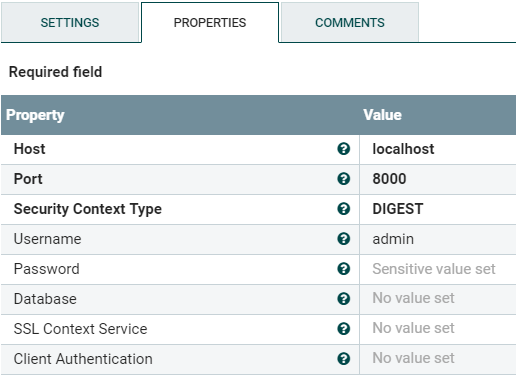
図11:PutMarkLogicプロセッサのDatabaseClient Serviceプロパティ
DatabaseClient Serviceのポートは、MarkLogic REST APIをサポートする必要があります。ドキュメントを特定のポートに構成されたコンテンツデータベースではなく特定のデータベースに書き込む場合は、「Database」値を変更することもできます。
セキュリティモデルの必要に応じて、PutMarkLogicプロセッサの「Permissions」プロパティを設定することもできます。
「URI属性名」プロパティ値はemp_id 以前のEvaluateJsonPath Processorから抽出されたプロパティであることに注意してください。
SETTINGSでは、成功と失敗の両方で自動終了します。
プロセッサを線でつなぐ
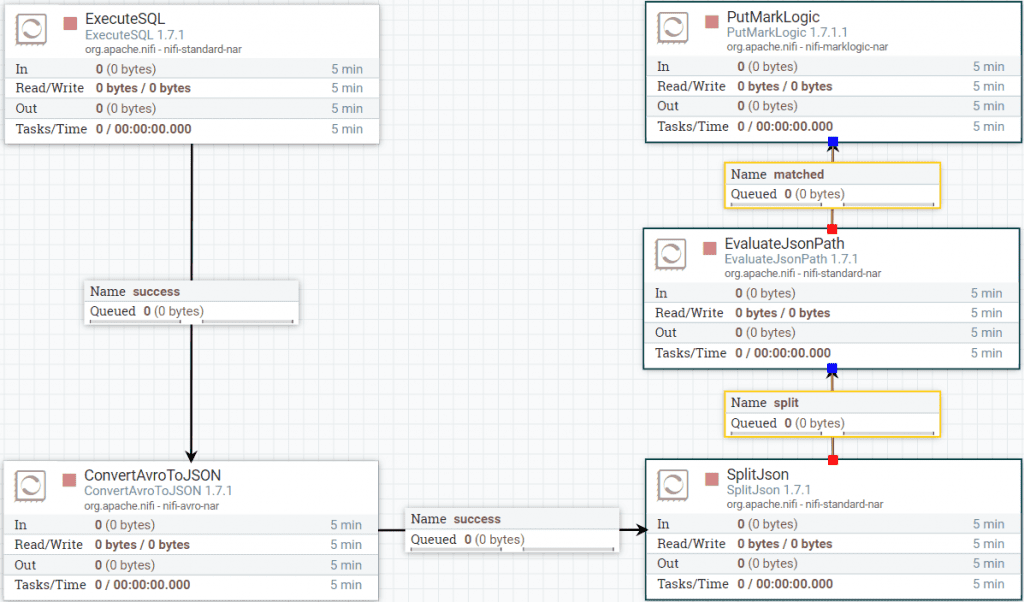
これで、すべてのプロセッサが配置されました。それらをすべて線でつなぎます。NiFiデータフローキャンバスは次のようになります。
図12:プロセッサのみのデータフローキャンバス
マウスをExecuteSQL Processorに合わせると、「接続」アイコン ( ) が現れます。このアイコンをクリックしてConvertAvroToJSON Processorに向かってドラッグし、そこにドロップして接続します。
) が現れます。このアイコンをクリックしてConvertAvroToJSON Processorに向かってドラッグし、そこにドロップして接続します。
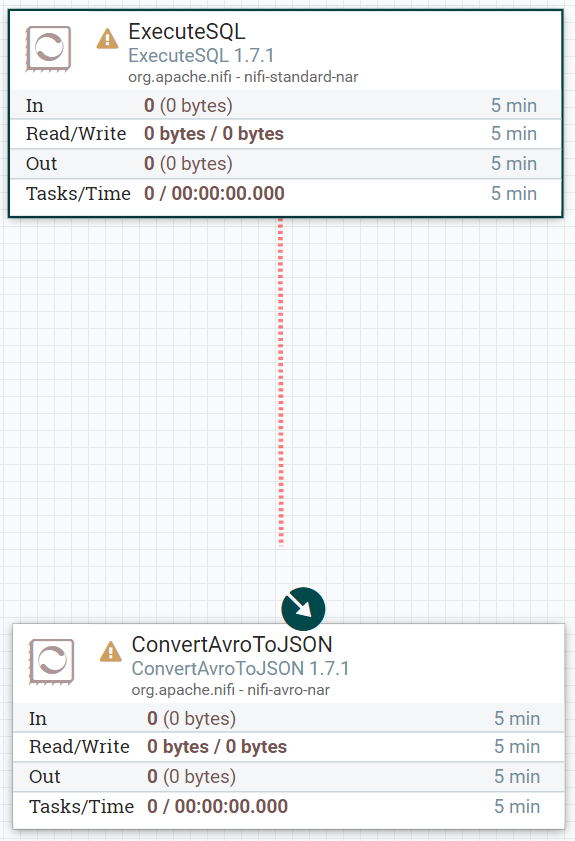
接続が正常に作成されると、接続設定用の画面が表示されます。関係を「success」として設定します。
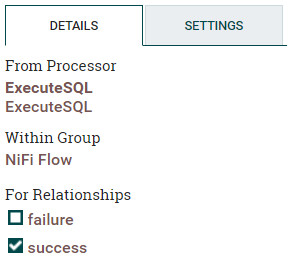
残りのプロセッサについても同じ設定を繰り返します。
- コネクタをConvertAvroToJSONからSplitJsonプロセッサにドラッグして、接続(success)を確立します。
- コネクタをSplitJsonからEvaluateJsonPathプロセッサにドラッグして接続(split)を確立します。
- コネクタをEvaluateJsonPathからPutMarkLogicプロセッサにドラッグして、接続(matched)を確立します。
これで、次のようなフローになります。
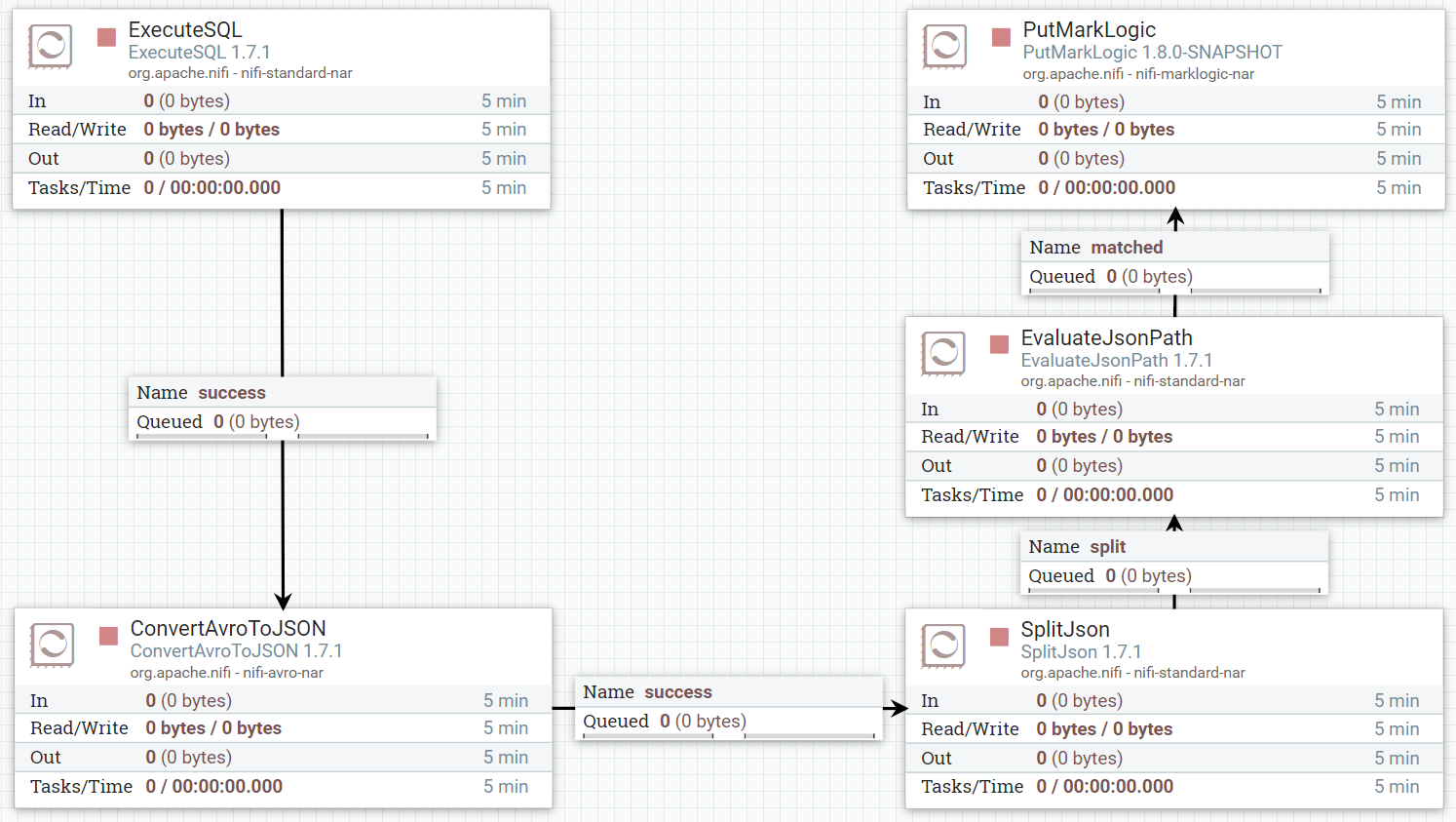
図13:プロセッサと接続を含むデータフローキャンバス
実行!
空白の領域を右クリックしてメニューを表示し、「Start」をクリックします。
注:すべてのプロセッサは、実行中は変更できません。再設定する必要がある場合、そのプロセッサを「Stop」する必要があります。
MarkLogicのクエリコンソール (http://localhost:8000) を使用して、リレーショナルデータがドキュメントに変換されたことを確認します。
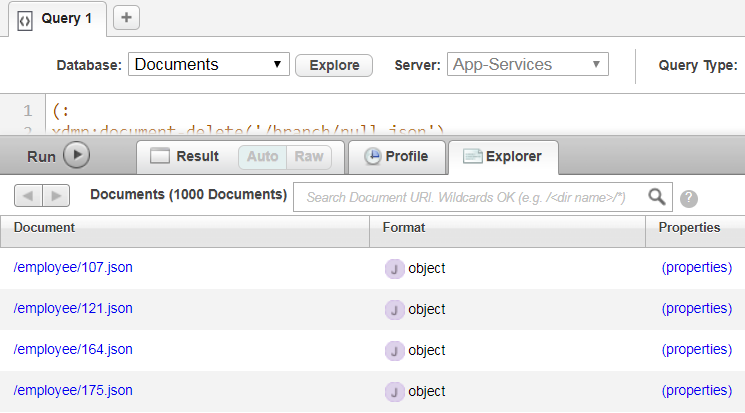
次の内容 :

図14:ドキュメント形式への変換結果(Query Console)
Figure 14: Relational rows converted to documents in Query Console
おめでとうございます!これで、リレーショナルデータベースからMarkLogicにデータが移行されました。
NiFiテンプレートの保存と再利用
プロセッサの配線は簡単に設定できますが、何度も繰り返すと、実行中にミスを簡単に引き起こす可能性があります。さらに、データソースはリレーショナルソース(REST呼び出し、Twitterフィード、CSVなど)だけに限定されない場合があります。作業を「保存」するために、コンポーネントを選択し、後で再利用できるNiFiテンプレートとして保存できます。
コネクタを含む、テンプレートとして保存するキャンバス上のコンポーネントを選択します。青色の境界線に注意してください。
左側に表示される操作パネル上の「Create Template」アイコン ( ) をクリックします。
) をクリックします。
テンプレートの名前と説明を入力して、「CREATE」をクリックします。
成功すると、次のようなプロンプトが表示されます。
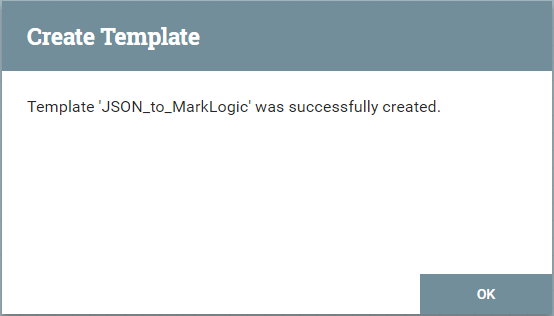
テンプレートアイコン ( ) をキャンバスまでドラッグし、次のプロンプトを表示します。
) をキャンバスまでドラッグし、次のプロンプトを表示します。
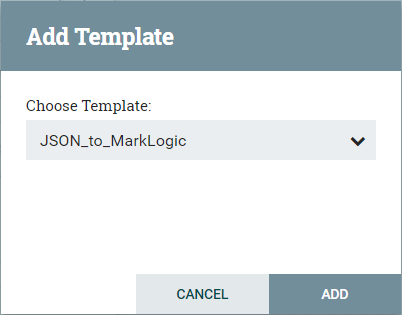
ドロップダウンを展開すると、「?」アイコンにカーソルを合わせて、テンプレートの説明を表示できます。

テンプレートを既存のキャンバスに追加すると、新しいプロセッサが既存のプロセッサの上に重なる場合があります。その場合は必要に応じて並べ替えます。
このテンプレートを追加した後、ソースがまだ指定されていないため、PutMarkLogicプロセッサとSplitJsonプロセッサに黄色の三角形の警告アイコンが表示される場合があります。テンプレートは、テンプレートによって作成された新しいプロセッサインスタンス用の新しい「MarkLogic DatabaseClient Service」を作成することに注意してください。プロセッサをダブルクリックして設定し、「DatabaseClient Service」プロパティの[Go To]アイコン(緑色の矢印)をクリックします。現在無効になっているDefaultMarkLogicDatabaseClientServiceの追加インスタンスがあることに注意してください。
この時点で2つのオプションがあります。
- このインスタンスを削除し、既存の有効なインスタンスを選択します。これは、同じMarkLogicインスタンスを同じCredintial情報と変換で使用する場合に推奨されます。
- この新しいインスタンスの名前を変更して有効にします。これは、別のインスタンスを使用する場合、および/または別の変換を使用する場合(DHFを使用している場合は別の取り込みフローなど)に推奨されます。
オプション1を選択した場合、PutMarkLogicプロセッサの新しいインスタンスを構成して、DefaultMarkLogicDatabaseClientServiceの元のインスタンスを使用します。
テンプレートの詳細については、Apache NiFi User Guideをご覧ください
Additional Reading
古川拓也
Oracle Databaseのコンサルタンタントを最初のキャリアとして、
KVS、Java、Digital Marketingなど様々なテクノロジーのコンサルティングを経験。
一瞬ビジネスコンサルティングよりになりかけたが、
MarkLogicの技術的な完成度や哲学に心酔しMarkLogicに入社。
MarkLogicを正しく効果的に使って頂けるように、
ベストプラクティスを広く浸透させることをミッションとしている。
