
クラウドネイティブなデータ統合体験
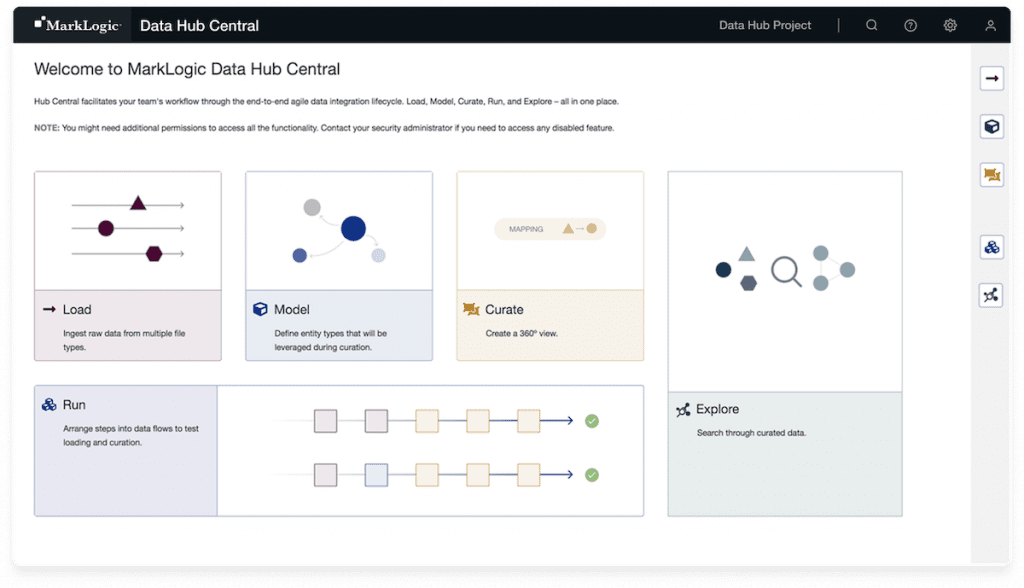
MarkLogic データハブセントラルをご紹介できることは、私たちにとって大きな喜びです。これは MarkLogic データハブサービス用のクラウドネイティブなユーザーインターフェイスであり、アジャイルなデータ統合を実現するものです。
データハブセントラルは、コラボレーションおよびセルフサービスを実現します。これにより、クラウド上で継続的にデータ統合を行い、目的に合った一貫性のあるデータアセットの作成、探索、共有ができます。これは、データ担当者たち(ビジネスアナリスト、データスチュワード、アーキテクト、データエンジニア)が作業を一か所で共有し、容易にデータハブを実装できるよう設計されています。コーディングは不要です。
データハブセントラルは、MarkLogic の反復的なモデルドリブンなデータ統合プロセスを、シンプルなユーザーインターフェイスから利用可能にしたものです。これによりアジャイル担当チームが、データハブサービス上にサーバーレスのクラウドデータハブを実装できます。複数用途向けの永続性のあるデータアセットの作成を目的とした、マルチ構造化データのハーモナイズ、マスタリング、エンリッチがシンプルになります。キュレーション済みデータアセット全体に対して、複数の観点から柔軟に調査・分析できます。また完全なセキュリティとガバナンスも備わっています。
データ担当者に10倍のアジリティを提供
データハブサービスは、AWS および Azure 上で提供される、データ統合用のフルマネージドのクラウドサービスです。トランザクショナル、オペレーショナル(業務用)、分析用にご利用いただけます。またコストは小さくかつ予測可能です。データハブセントラルはデータハブサービスの主要なユーザーインターフェイスであり、ここからデータハブプロジェクトの設定、テスト、デプロイができます。ソフトウェアを別途ダウンロードする必要はありません。これによりデータ統合のDevOpsが極めてシンプルになります。
この新しい機能により、データハブのワークロードをクラウドに実装する際に、データのインフラおよび実行活動がアジャイルになります。
上のデモが示すように、データ統合には複数の人間が関わっており、それぞれが何らかの役割を担っています。彼らはデータライフサイクルにおいて複数回やり取りします。データハブセントラルを使うことで、これらの関係者(データアーキテクト、システムアナリスト、ビジネスアナリスト)は、反復的にコラボレーションし、データハブの構築・テストにおいて、それぞれの専門スキルで貢献できます。
データハブセントラルによってシンプルな共有が可能になることで、データハブのさまざまな利用者のやり取りの調整が楽になります。これにより、エンティティモデルの定義、キュレーションサービス(データのハーモナイズやマスタリング)の設定、キュレーション済み(あるいは生データ)の確認・共有において、データを直接扱えるようになります。
データハブの実装における、段階的データキュレーションにより、データのサイロだけでなく業務部門のサイロも解消されます。これによりアジャイルが実践され、結果が得られるまでの時間が従来のETLの1/10に短縮されます。
データハブセントラルは、従来はIT部門に依頼していたデータニーズをセルフサービスで実現できます。たとえば、ビジネスアナリストは業務分析をセルフサービスで(自分自身だけで)行えます。解決すべき現在のビジネス課題の解決に必要なデータを直接入手できるのです。データセットは、一般的なBIツールで容易に保存、共有、再利用できます。その際、IT部門に依頼する必要はありません。
データ統合・アズ・ア・サービス
データハブサービスは、アジャイルなデータ統合を目的とするクラウドニュートラルなサービスです。データハブセントラルの目的は、データハブサービスにデータハブを実装する際に、すべての関係者がシームレスに参加できるようにする、ということです。
データハブ実装の重要なステップとして、データアーキテクトによるエンティティモデルの定義があります。データハブセントラルを使うことで、アーキテクトはダイナミックにエンティティモデルを定義できます。このエンティティモデルは、個々のユースケースではなく、組織における変化を反映したものとなります。また上流(ソース)のデータモデルを下流(利用者側)のデータモデルから隠します。この結果、ETL のロックインが起こりません。またダイナミックかつ耐久性のあるデータセットを作り出すことができます。
データハブは組織の中心に位置するデータアセットであり、ガバナンス、セキュリティ、その他のデータのライフサイクルポリシーを定義するのに最適です。このデータハブセントラルでは、データハブサービス上のデータハブに関する、こういったデータポリシーやその他のメタデータを、容易に一元的に定義・適用できます。
一方、何らかのデータハブを独自に構築しようとすると、データの管理と統合を実現するために、さまざまなクラウドサービス(ETL ツール、データベース、MDM など)を組み合わせる必要がでてきます。こうなると、TCO が増加するだけでなく、さまざまなクラウドサービス全体でデータおよびメタデータの整合性をどう確保するのかというガバナンスの課題も発生します。対照的に、データハブセントラルでは、データ統合ライフサイクルを通じてデータとメタデータを一緒にトラッキングするので、データハブサービス内でこれらすべてを管理・保護できます。
結果創出までの時間を短縮し、統合のリスクとコストを削減
データの統合・管理に対してアジャイルの原則を適用することで意思決定が早くなり、アクションが迅速になります。しかし適切なデータがあるだけでは十分ではありません。変化に適切に対応するには、データに意味を与えるコンテキストが必要です。つまり、データをキュレーションし、整理し、特定用途用に準備する必要があります。
データにコンテキストを与えるには、セマンティックが必要です。セマンティック(MarkLogic のグラフ機能)は、データハブサービスのユニークな機能です。セマンティックを使うと、エンティティ自体、エンティティ間の関係性、関連するメタデータの管理やクエリが楽になります。またこれはデータキュレーションにおいて大きなメリットがあります。データハブセントラルでは、エンドユーザーがセマンティックを活用できるので、「クラウドにおけるセマンティックによるデータ統合」というビジョンの実現に大きな一歩を踏み出すことができます。
簡単に言うと、データハブセントラルによってデータハブサービスの利用が楽にまたシンプルになります。一元化されたデータガバナンスおよびセキュリティポリシーが直感的に設定できるので、データ統合におけるリスクとコストを削減し、また結果を短期間で得ることができます。
データハブセントラルによって、データハブサービスは単なるデータ統合インフラであるだけでなく、セルフサービスでも利用できるようになります。データ担当者たちが自らビジネスバリューを創出できるのです。
