
過去数年間、私はMarkLogicでコンサルタントおよびプリセールスエンジニアとして数々のプロジェクトに携わる中で、一部のプロジェクトはスムーズに進むのに、他のプロジェクトはいかに難航するかということに驚かされてきました。遅延の主な理由は、古いRDBMSシステムが、高品質のドキュメントデータを生成できないことです。これらのプロジェクトを振り返ると、MarkLogicプロジェクトスピードと、重要な統合パターン(Load As Isの統合パターン)の使用に直接的な相関関係があることが分かります。
これまでHadoop、MapReduce、HBase、Javaなどのシステムでドキュメント変換ツールの構築を試みる多くのプロジェクトを見てきましたが、これらのフレームワークのほとんどは、構築、テスト、最適化に長い時間がかかりました。なぜならこれらは元々、JSONおよびXMLドキュメントを変換および検証する目的で設計されたものではなかったからです。MarkLogicを使用してこれらのドキュメントを変換および検証するには、適切なツールを適切なジョブに使用する必要があります。それでは、Load As Isパターンとは何か、そしてこのパターンがどのようにしてMarkLogicプロジェクトの進行を加速するのかを見ていきましょう。
Load As Isパターンとは?
ここでご紹介するのは、ドキュメントの作成中に、ドキュメントをオンザフライでクリーンアップする方法です。ここでは、ドキュメントストアで作業し、XMLとJSONの構造を理解していることを前提としています(必要な場合は、ここで復習できます)。
Load As Is 統合パターンは、MarkLogicを使用する上で鍵となるものであり、最も難しく感じる概念です。このパターンは、ソースデータ形式をほとんど変更することなく、外部データソースからMarkLogicに直接データを読み込むプロセスです。
単にデータをダンプする場所ではない
まず皆さんに決別していただきたいのは、データストアにデータをダンプすることです。一部のドキュメントデータベースではこの方法が採用されているようですが、MarkLogicは違います。MarkLogicは、スキーマ非依存(ただしスキーマは認識しています)のユニバーサルインデックスをオンザフライで作成します。そのため、データの読み込み時にユニバーサルインデックスが作成されます。また、ユニバーサルインデックスは単一のインデックスではなく数十のインデックスからなります。これをコントロールすることで、スピードを改善できます。ユニバーサルインデックスは、ドキュメント内のラベルとタグを使用して、事前のデータモデリング無しで、新しいデータにすばやくインデックスを付けます。ユニバーサルインデックスについては、後ほど詳しく説明します。
理解して受け入れるべきキーコンセプトは、全てのデータを事前にクリーンアップする必要はない、ということです。これは、データの構造やクリーニングが重要ではないということではなく、処理の順序を変えるということです。その利点は何でしょうか?それは、必要なデータのみを必要に応じてクリーニングすることで、リレーショナルシステムで構築作業を行っている同業者よりも、はるかに優れたアジリティを発揮できるようになる、ということです。それでは具体例を見ていきましょう。
Load As Isパターンを使用するタイミング
Load As Isパターンは、多くのMarkLogicプロジェクトの初期段階で使用されます。外部データソースからMarkLogicに新しいデータを読み込む必要がある場合は常に使用されます。これは多くの場合、新しいアプリケーションを構築したり、既存のアプリケーションに新しいデータを追加したりする際の最初のステップになります。Load As Isパターンは、新しいデータセットの構造と品質を素早く把握したい経験豊富なMarkLogicコンサルタント、データベース管理者、およびビジネスアナリストに広く使用されています。
Load As Isパターンと外部変換アンチパターンを図1に示します。

図1:ここでは、低コストのLoad As Isパターンと、サードパーティのデータ変換ツールを使用した高コストのアンチパターンを比較しています。これらの外部ツールは、MarkLogic Universal Indexでデータを分析することはできません。
Load As Isパターンは、通常、他のデータソースから新しいデータを読み込む際に使用します。たとえば、複雑なリレーショナルデータ、外部XMLまたはJSONドキュメントからのデータ、グラフ、CSVファイル、またはMicrosoftのドキュメントやスプレッドシートなどのデータです。
Load As Isパターンの利点
MarkLogicのカスタマーは、サードパーティのデータ変換ツールを使用してMarkLogicにデータを読み込む前にデータを適切なデータ形式に変換する他のパターンよりも、Load As Isパターンの方がコストが低く、アジリティが高いことに気付かれるはずです。Load As Isパターンは、データサイロを解消するための多くのデータハブアーキテクチャの最初のステージです。
ダイレクトなLoad As Isパターンを使用することで、他の間接的なアプローチに比べ、以下のような多くの利点があります。
- 高速データ分析とデータプロファイリング
- 継続的なコンテンツのエンリッチメント
- 統合されたドキュメント検証
- 統合されたデータ品質
- 自動化されたモデル生成とスキーマ推論
では、これらの5つの利点について詳しく見ていきましょう。
ユニバーサルインデックスによる高速データ分析
すでに見てきたように、データをMarkLogicに読み込むと、MarkLogicのユニバーサルインデックスシステムによって即座にインデックスが作成されます。このため、シンプルなクエリとデータプロファイリングツールを使用して各データ要素を素早く分析できます。たとえば、10,000個のランダムなPersonBirthDate要素が、結果を日付でソートする際に有効な日付構造としてキャストされているかどうかを簡単なクエリで判断できます。図2は、このプロセスをすばやく簡単に行えるMarkLogicデータアナライザーツールの画面です。
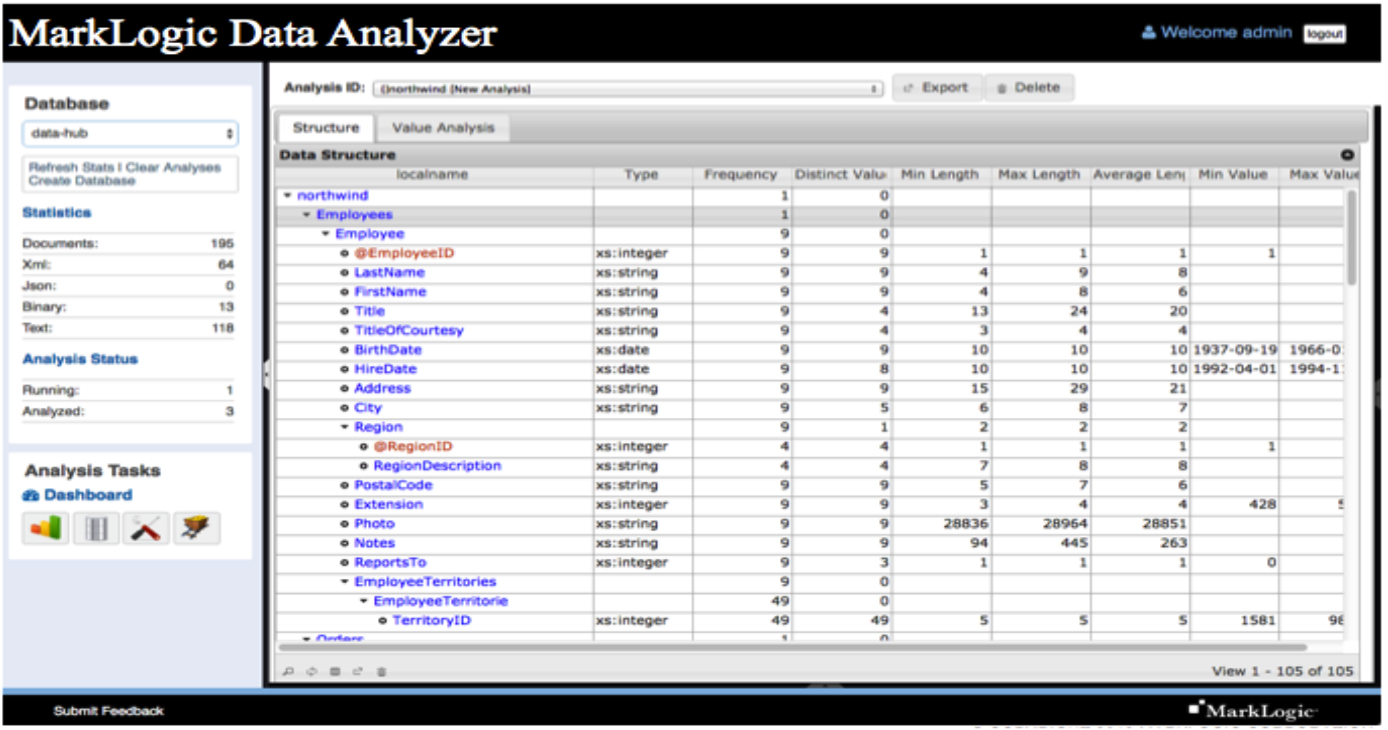
図2:MarkLogicデータアナライザーの画面。Universal Indexを使用することで、データを読み込んでから数分以内に、分析を実行できます。
MarkLogicデータアナライザーは、MarkLogicのコンサルティングサービスが構築しました。これにより、データサンプリングとデータ型推論を使用して、ドキュメント内の各データ要素に関する詳細なデータプロファイル情報を素早く自動的に生成できます。データプロファイルには、推測されたデータタイプ(文字列、整数、日付など)、列挙値(コード)、および形式の検証に使用できるパターンが表示されます。MarkLogicユニバーサルインデックスにより、MarkLogicへのロードから数分以内に、サンプリングデータまたは大規模なデータセット全体に対してデータプロファイリングを実行することができます。
MarkLogicデータアナライザーとその他のクエリツールは、ドキュメントを使用して個々のデータ要素を詳細に分析します。たとえば、<PersonFamilyName>などのデータ要素がある場合、データアナライザーは、データタイプ(文字列)とこの文字列の統計情報を提供します。統計プロファイルデータには、次のものが含まる可能性があります。
- 最小文字列長
- 最大文字列長
- 平均文字列長(平均、中間、モード)
- 文字列長の標準偏差
- 使用されている文字数(すべての文字、数字を除外)
- 空のデータ要素の頻度
このデータはなぜ重要なのでしょうか?このデータを、<PersonFamilyName>が必須フィールドである構造に読み込むとどうなるでしょう。姓の半分が空の場合、このデータは破損しているか、あまり役に立たない可能性があります。データがクリーンであるものと想定していて、プロジェクトがある程度進んでから、プロジェクトで使用したいデータの品質が不十分であることに気づくことはよくあります。MarkLogic Universal IndexとLoad As Is パターンは、破損した低品質のデータに対する最初の防波堤となります。
継続的なコンテンツのエンリッチメント
データがプロファイリングされると、MarkLogicに直接組み込まれた強力なトランザクションセーフデータ変換ツールのセットを使用して、データを継続的にエンリッチできます。これらの変換ツールは、ユニバーサルインデックスとキャッシュおよび分散クエリ処理の両方を使用して、ドキュメントをトランザクション、検索、分析が可能な構造に迅速に変換します。MarkLogic内のデータの継続的なコンテンツエンリッチメントも、経験豊富なMarkLogic統合チームが使用する重要な統合パターンの1つです。
名前が示すように、継続的なコンテンツエンリッチメントは1回限りの操作ではありません。新しい目的でデータが使用されるたびに、MarkLogicに出入りする情報の流れを中断することなく、新しいデータ要素によって継続的に更新できます。もし15分あれば、MarkLogicに保存されたドキュメントのコンテンツ一括再処理用に設計されたJavaツールであるCoRBのチュートリアルと、エンベロープパターンを使用したプログレッシブ変換についてのチュートリアルをご覧ください。
「コンテンツのエンリッチメント」パターンの図を図3に示します。

図3:コンテンツのエンリッチメントパターンは、エンタープライズ統合パターンのWebサイトから取得します。
コンテンツのエンリッチメントとは、数値コードを人間が読み取れる文字列に変換することです。例えば、女性の性別コードを1、男性の性別コードを2とする場合などです。RDBMS上で実行されるアプリケーションでなければ、参照データを使用してコードを数値から人間が読めるラベルに変換する方法を理解することはできません。

図4:コンテンツのエンリッチメントの前後のサンプルデータ
これらのラベルをエンリッチすることで、検索ツールの構築と使用が容易になります。例えば、ユーザーが医療提供者の検索ツールに「女性医師」と入力すると、ユニバーサルインデックスで、女性医師を男性医師よりも検索結果で上位にランク付けできます。エンリッチメントによって、元のソースコードが削除されることはありません。ラベルテキストが変更されたら、スクリプトが実行されラベルが更新されるだけです。
数値コードを調べて英語(またはその他の言語)の言語ラベルを追加することについても、MarkLogicは非常に優れています。通常、コードルックアップテーブルは小さいため、それほどメモリを消費しません。生のRDBMSデータから人が読めるドキュメントに変換する場合、通常だと数十回の検索が必要になる場合があります。MarkLogicでは、インメモリのキー/バリューマップを使用して、これらの検索を高速化します。
コンテンツのエンリッチメントのその他の例としては、米国の郵便の宛先規格の検証や、高速地理情報検索を目的とした経度や緯度などのジオコーディング要素の追加などがあります。これらの要素により、「自宅から10マイル以内にいるすべての女性医師を見つける」のようにクエリを組み合わせて使用することができます。
次のステップは、エンリッチメントの結果がデータ品質の一連のテストに合格できるかどうかを理解することです。これらのテストは、MarkLogicに読み込まれた生データを本番環境で使用する場合に不可欠です。
統合されたドキュメント検証
次に、「連続コンテンツエンリッチメントプロセスの結果として生成されたドキュメントが、一連の明確なビジネスルールへの準拠をどのように把握するのか」について説明します。これらのルールは、必要なすべてのデータ要素の存在、データ要素の順序、ドキュメントツリー構造内の各リーフ要素のデータ型など、特定のドキュメントが主要なデータ品質テストに合格するかどうかを理解するのに役立ちます。
ほとんどのリレーショナルデータベース、UNIXまたはHadoopファイル、または単純なファイルシステムとは異なり、MarkLogicでは、各データベースを独自の一意のスキーマルールデータベースで構成できます。MarkLogicスキーマデータベースは、ドキュメントの一貫性や検証などのタスクを実行するための複数のタイプのビジネスルールを格納する際に使用します。ドキュメント検証の図を図5に示します。

図5:ドキュメントの検証は、XMLインスタンスドキュメントの名前空間を適切なXMLスキーマにバインドすることによって実行します。
通常、ドキュメントがビジネス機能に必要な最低限の基準をクリアするまで、エンリッチメント変換サイクルが繰り返されます。次に、標準のXMLスキーマに対する検証が行われます。この処理の結果は、MarkLogicドキュメントに直接統合される特殊なメタデータプロパティに保存されます。XMLスキーマ図の例を図6に示します。
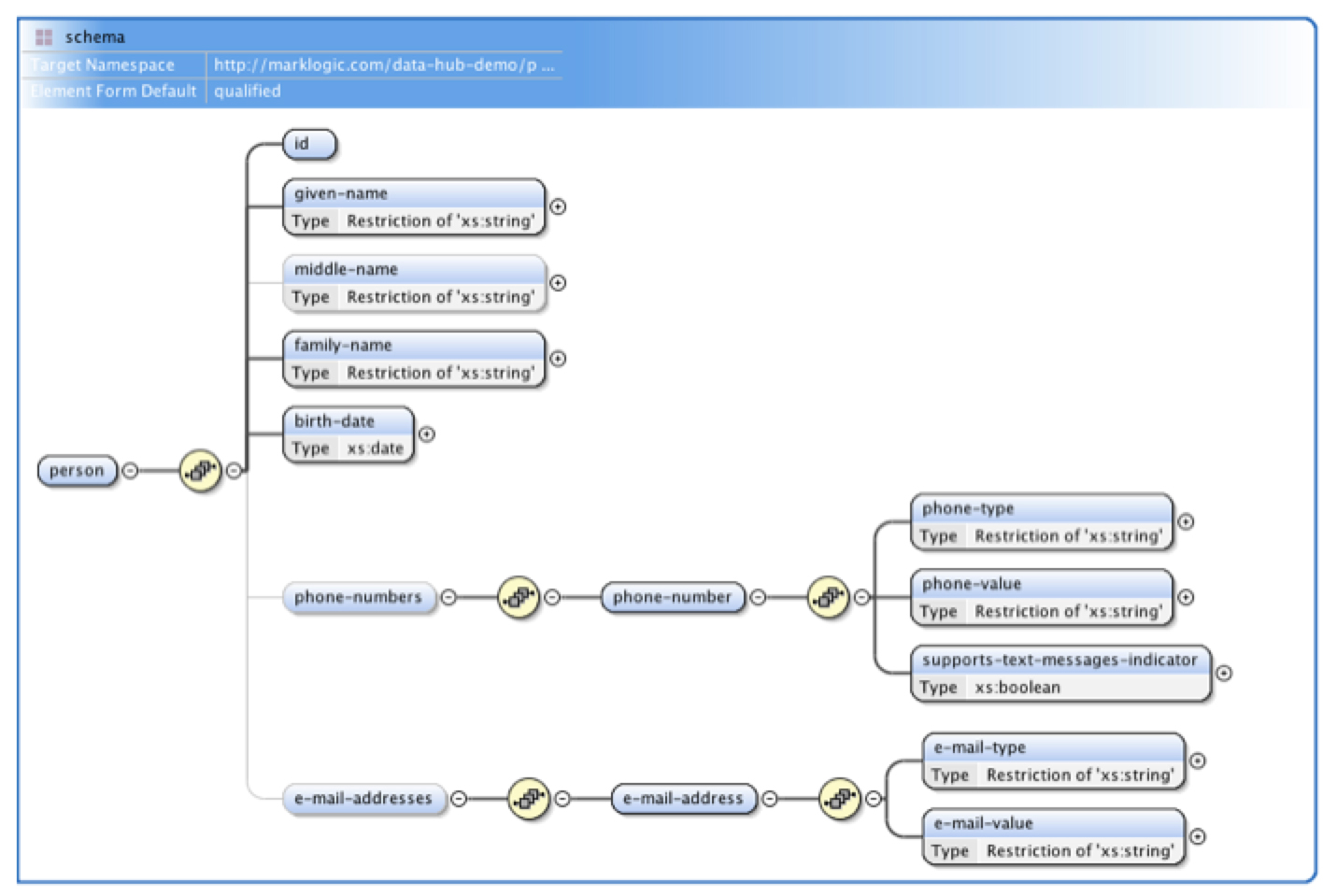
図6:oXygenXMLエディターを使用した一般的なXMLスキーマファイルのグラフィカルデザインビューのサンプルです。ライトグレーの線は、オプションのデータ要素であるミドルネーム、電話番号、メールアドレスを示します。
XMLスキーマ検証は、10年以上にわたってドキュメントストアのベストプラクティスとなっている成熟した技術です。XMLスキーマ検証を高速で動作させる方法は複雑ですが、グラフィカルエディタを使用すれば、プログラマーでなくても検証ルールを簡単に作成、表示できます。これらのルールはXMLスキーマファイル(.xsdファイル)でキャプチャされ、MarkLogic スキーマデータベース内に直接格納されます。
XMLドキュメントとXMLスキーマは、名前空間と呼ばれる文字列にそれぞれ関連付けることができます。ドキュメントとXMLスキーマの両方が同じ名前空間を参照するため、MarkLogicは各データ要素に適用するルールを正確に認識できます。これらのルールのバリエーションは、データ品質チェックで検出できる例外を素早くトリガーできます。
MarkLogicが提供するツールにより、単純なJSONドキュメントでも、複雑でありながら正確な検証が可能な名前空間を備えたリッチなXML形式にすばやく変換することができます。
XMLスキーマ検証は、データ品質チェックの管理を可能にするツールの1つにすぎません。ユニバーサルインデックスを活用するその他のクエリを作成して、注文の合計が明細の合計と等しいかどうかなどの複雑なビジネスルールを検証することもできます。
ここまで、これらのデータ品質テストツールについて詳しく説明してきました。これで、Load As Is パターンがデータの変換処理を加速する方法をご理解いただけたはずです。検証の結果、具体的なエラーが多数返される可能性がありますが、多くのデータ品質システムは、ドキュメント検証の結果をブール変数(DocumentValidIndicatorがTRUEかFALSEか)で表し、グレーの中間点がありません。次のセクションでは、MarkLogicを、こういった白か黒かのチェックよりもはるかに柔軟に使用する方法について説明します。
統合されたデータ品質指標
MarkLogicのユニバーサルインデックスおよび統合検証ツールの機能に慣れてきたら、次のような疑問が湧いてくるかもしれません。
- これらを全てまとめて、データの「本番稼働準備完了」の指示を出すタイミングを決定するにはどうすればよいか
- まだ100%有効ではない貴重なデータがあり、これらを検索結果に含めたい場合はどうすればよいか?
- データ品質に基づいて検索順位を変更したい場合はどうすればよいか?
素晴らしいことに、MarkLogicはこれらをすべて実行してくれます。
MarkLogicは、データ品質スコア(通常は1〜100の整数値)をすべてのドキュメントに関連付けることができます。そして、これらのスコアを使用して、ドキュメントに「検索準備完了」のタグを付けるかどうか、またはどのように検索結果の順序付けを行うかを決定します。各組織は、MarkLogicのドキュメントメタデータプロパティ構造を使用して、ドキュメント全体の品質スコアに寄与する1つ以上のデータ品質コンポーネントを関連付けることができます。Load As Isパターンは、強力なデータ品質指標への急速な進歩を実現するうえで不可欠なものなのです。
図7は、初期のデータ品質が50のドキュメントを挿入するXQueryコードの例を示しています。次は、エンリッチメント後にこのドキュメントのデータ品質を70にアップグレードできることを示しています。最後のクエリは、しきい値60を超えるすべてのドキュメントが検索結果にどのように表示されるかを示します。

図7:データ品質を設定および取得し、品質スコアが60を超えるノードのみを返すクエリのサンプル
自動化されたモデル生成とスキーマ推論
Load As Isパターンとドキュメントを即座に分析する機能により、クエリを記述して、生データの正確なドキュメントモデルを迅速に作成し、データを充実させ、XMLスキーマに対してドキュメントを検証できます。ただし、ユーザーがXMLスキーマを構築する時間も専門知識も持っていない場合もあります。こういった場合は、ラフカットデータから直接検証ルールを自動生成するデスクトップツールを使用できます。
データからルールを生成するプロセスは、「モデル生成」と呼ばれています。ソフトウェアは、データの多くの例を分析し、パターンと変動性を探すことができます。すでにXMLスキーマがある場合は、これらのツールによりサンプルXMLデータを生成することもできます。これらは、検証フレームワークの単体テストを構築するのに最適です。図8は、一般的な読み込み、モデル化、調整、およびテストの循環的な連続データ品質改善ワークフローのサンプルを示しています。

図8:ドキュメント分析、スキーマ生成、エンリッチメント、スコアリングを含むLoad As Isのサイクルの例。
MarkLogicは、oXygen XML Editorなどのドキュメント指向のデスクトップ統合開発環境でも動作するため、サンプルデータセットから直接XMLスキーマをすばやく生成できます。XMLスキーマ形式の経験は不要です。一般的なデータ取り込みワークフローは、生の「ステージング」データの初期検証と、変換後のデータエンリッチメントの結果検証の両方を提供します。ドキュメントが許容可能なスコアに達すると、インスタンスドキュメントを使用して、ドキュメントの完全なXMLスキーマモデルを自動的に生成できます。これらの高品質モデルは、「標準」モデルとも呼ばれます。これらの標準モデルは、直接クエリできます。たとえばXMLスキーマには、PersonGenderCodeなどの特定のデータ要素のすべての可能な値(列挙)のリストが含まれます。これらのモデルのクエリは、WebベースのGUIエディターの選択リストとして使用できます。その後、XMLスキーマを使用して、テンプレートスタイルの変換の基盤となる「テンプレート」を生成できます。
これらの5つのポイントは、MarkLogicでLoad As Isパターンを使用する利点のほんの一例です。現在も多くのMarkLogicプロジェクトが進行中であり、Load As Isパターンは、迅速で低コストのエンタープライズデータハブプロジェクトを実現するうえで、不可欠なものとなっています。現在進行中のプロジェクトでも、MarkLogicは、データサイロを解消し、お客さまの統合ビューを構築する上で最も費用対効果の高いシステムであり続けます。
