
「MarkLogic はデータプラットフォームだ」と言われています。これはどういう意味なのでしょうか。
データとメタデータ
これは「MarkLogic はデータおよびメタデータを管理する」ということです。それではメタデータとは何でしょうか。
メタデータとは、データの説明のことです。例えば、「name」というデータがあり、これは個人情報だとします。この場合、「name」が個人情報であることを示すメタデータを追加できます。メタデータは、データの出自やセキュリティなどを記述するのに非常に便利です。メタデータによってデータの使用に関するコンテキストを付与できます。結局のところ、メタデータもデータなのでクエリで扱うことができます。これにより、データ管理を強化できます。
ここで忘れてはならないのは、MarkLogic では非構造化ドキュメント(コンテンツや記事/投稿などのデータ)も管理できるということです。
それでは、MarkLogic ではデータとメタデータをどう管理するのでしょうか。
ユニバーサルインデックス、ドキュメントデータベース、検索エンジン、エンリッチメント
最初のステップとして、MarkLogic ではさまざまなシステム(CRM、PLM、SAP など)からデータを読み込みます。この際、データを「そのまま」読み込みます。
たとえば、Name 列、First name 列、また関連する行を含む Excel ファイルを読み込むと、MarkLogic は各行ごとに対応する XML(あるいは JSON)ドキュメントを1つずつ作成します。この際、Name: Doe; First Name: Joe などに加えて、ソース内の他の情報(出自、日付など)も含めることができます。
これはどのように実現できるのでしょうか。これは、MarkLogic のドキュメントデータベース機能で行われます。
それではすべてのドキュメントが MarkLogic に格納されたら、次に何をしたら良いのでしょうか。MarkLogic はユースケースドリブンなので、このデータで何をしたいのかをユーザーチームに聞く必要があります。
ここで素晴らしいのは、MarkLogic ではデータを読み込んだ時点で、データ、メタデータ、地理情報データ、テキスト、トリプル(後述します)に対してユニバーサルインデックスが作成されるということです。MarkLogic に標準装備されている検索エンジンとこれらのインデックスを一緒に使うことで、ユースケースに基づいてデータを可視化し、データの利用方法を定義できます。
さて、ここまで MarkLogic データプラットフォームの「読み込み」「インデックス」「ドキュメントデータベース」「検索エンジン」について説明してきました。これによりデータを使って何をしたいのかを指定できました。それでは次に進みます。
ハーモナイズおよび重複解消
次のステップでは、複数のソースに由来する、データ要素が異なる方法で定義されているデータを「ハーモナイズ」します(調和させます)。例えば、あるソースでは「name」として定義されていたものが別のソースでは「nom」(フランス語)だったりすることがあります。これらを関連付けることを「マッピング」と呼びます(これはマッピングの極めて単純な例ですが)。マッピングでは、いくつかの関数を使うことで形式を変更できます(日付、電話番号など)。
これは極めて単純なハーモナイズの例ですが、ユースケースよってはより完全(かつ複雑)なハーモナイズを行うこともあります。例えば、データをリファレンステーブルとリンクさせる(「製品A」とリファレンステーブル内の「0001」)、あるいは別ソースの値に応じて新しい値を定義することもできます。こういった関数を、JavaScript または XQuery でコーディングできます。
もう1つのステップとして、「重複解消」があります。例えば、John Doe という顧客が複数のソースに存在している場合、同一人物ではあるがそれぞれの顧客情報が若干異なっている場合や、あるいはそもそも全然違う人物である場合が考えられます。
ここで「スマートマスタリング」を利用できます。これによりこれらの顧客が同一人物かどうかを確認するルール(姓、名、誕生日、住所、個人IDなどを対象)を適用できます。その際、それぞれの判定対象に重み付けし、これらの顧客が「100%あるいは80%のレベルで同じ」といった判定をします。それらの合計点がある基準値を超えた場合、2つの顧客データを同一人物であるみなして1つに統合します。それ以下の場合は自動で統合せずに、目検でチェックするよう担当者にメッセージを送信します。
これにより、顧客の「ゴールデンレコード」が得られます。このゴールデンレコードには、これがどのように作られたのか、どのように変換されたのか、どのような出自なのかといった多くの情報が含まれています。これはメタデータによって実現されています。
論理的エンティティモデル、グラフデータベース、セキュリティモデル
「ゴールデンレコードを定義したい」というのは「エンティティ(「顧客」「製品」「契約」など)を一元的に把握したい」ということに他なりません。MarkLogic データプラットフォームは、自分で「エンティティ」を作り、それを関係づけられるという点で優れています。例えば、「顧客」エンティティを作成し、これを「契約」エンティティや「製品」エンティティに関連付けられます。
MarkLogic データプラットフォームには、関連付けに必要な「セマンティック機能」があります。つまり MarkLogic は「グラフデータベース」でもあるのです。これが強力かつ重要だとされるのは、 ビジネス的観点に基づいてモデルを論理的に公開できるからです。例えば、グラフ表現により、「顧客」から関連する「商品」を見つけたり、あるいは「商品」からそれを注文した「顧客」を見つけることができます。この表現は、前述のメタデータによるエンリッチと一緒に「ほぼ」利用可能なかたちでステージングデータベース上に公開されます。ここで「ほぼ」と言っているのはなぜでしょうか。このように複数のソースシステムからデータを統合する場合、このプロセスに起因する問題を管理する必要があります。ここで起因する問題とは、「どのようなセキュリティモデルを使うのか」「ここで必要なデータはどのような品質なのか」といったことです。実際には、これらはデータの利用方法によって変わってきます。
この問題に対応するため、MarkLogic データプラットフォームではデータセキュリティモデルを標準装備しています。ある特定のユーザーにはデータの閲覧や更新ができないようにしたい場合、ロールベースのアクセス制御を利用できます。データ自体にセキュリティを適用できるので、アプリケーション側にセキュリティを実装する必要がありません。また特定のデータ値の場合のみ、データを非表示にしたい場合もあるでしょう。これは属性ベースのアクセス制御で実現できます。この場合も、アプリケーション側にセキュリティを実装する必要はありません。すでにデータにセキュリティを適用してあるからです。
データの公開、リレーショナルデータモデル、REST API
モデルのキュレーションが終わったら、ユースケース用に整備済みのデータを公開できます。
ユースケースとしては、Machine-to-Machine のやり取り、Rest API 呼び出しによるデータの読み取りや更新/挿入(トランザクションアプリケーション)、情報の検索(対象としてデータ、メタデータ、地理情報、テキスト、セマンティックトリプルを組み合わせることが可能)、BIツール用の簡易的 SQL クエリなどが考えられます。
MarkLogic データプラットフォームでは、ドキュメント内のデータを、クエリによって行/列形式(=リレーショナルな表形式)で表示できるようインデックス付けすることもできます(TDE:Template Data Extraction 機能を利用)。
スケーラブルな一元化されたエンタープライズプラットフォーム「MarkLogic」で同一データを複数のユースケースで利用
「顧客」や「商品」といったエンティティでモデルを作り始めている場合、おそらくこのエンティティは複数のユースケースで利用されることになるでしょう。ここではデータをコンテキストにおいて捉えることが必要となります。例えば同一の顧客情報であっても、マーケティング部門に提示するものと営業部門に提示するものを変える必要があります。つまり新しいユースケースをカバーするために、より多くのデータを用意する必要がでてきます。そのため、より多くのデータおよびクエリを同一プラットフォームで扱うために、コモディティハードウェアによる水平拡張(スケーラビリティ)が重要となります。おそらく、データプラットフォームはますます重要になり、高可用性、災害対応、クラウド/オンプレミス/ハイブリッドのインフラが必要となるでしょう。
MarkLogic プラットフォームは、どのインフラにおいても提供される機能は同じです。いずれにおいても高可用性や災害対応の機能が標準装備されています。ここまで紹介してきた機能はすべて MarkLogic に標準装備されており、別途ツールを追加する必要はないため、MarkLogic を一元化されたデータプラットフォームと呼ぶことができるでしょう。
MarkLogic データプラットフォームと Semaphore の連携
次に、MarkLogic と一緒に利用される Semaphore という製品についてお話しします(Semaphore は MarkLogic なしで単体でも利用できます)。
MarkLogic で非構造化データを読み込んでいる場合、Semaphore が価値をもたらすことは明らかです。誤解がないように説明しておくと、Semaphore では構造化データも扱えます。しかし MarkLogic と一緒に使う場合は、非構造化データの方がより大きな価値が得られます。このため、Semaphore と MarkLogic を一緒に使用することで大きな価値が得られる業界として、契約や規制対応の管理が求められる製薬会社、製造業などがあります。また金融業界において、SRI(社会的責任投資)商品における ESG データに関して、MarkLogic 内の ESG の KPI と、Semaphore 内の非構造化データ(ESG の KPI のベースとなるもの)を一緒に活用するというユースケースもあります。
MarkLogic ユーザーにとっての Semaphore の価値
KMM(ナレッジモデル管理):Semaphore は、モデルを構築するモジュールである KMM によって構成されています(タクソノミー&オントロジー)。この KMM ツールは、セマンティックのコンセプトを熟知している人だけが使うことができます(製薬、航空宇宙、出版業界においてはセマンティックがよく知られています)。
分類とファクト抽出:分類(classification)エンジンは、文書から情報(日付、著者など)を抽出するだけでなく、いくつかのコンテンツ情報も抽出できます。例えば故障報告書に対して、分類エンジンは「このドキュメントは、xxによって作成され、日付はxxxxで、故障報告書である」ということを把握します。これが文書に対する最初の処理となります。
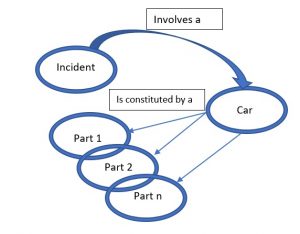
ここで、この故障報告書は自動車に関するものだとします。また以下のようにモデルが定義されているとします。下の図は、「故障」が「車」と、「車」が「部品」と関係していることを表現しています。
この故障報告書では、車両番号(VN)「XXXX」を特定できます。この情報はモデルに反映され、この車両番号の車を特定できます。また故障個所も特定できます。ここで SAP と連携して部品表(価格と説明)とPLM(部品の設計)を調べることができると、ブレーキに故障が発生しているというファクト抽出が可能となります。つまりこの故障にはブレーキが関わっていることが特定できるのです。

ステファン・マムーディ
ステファン・マムーディは、MarkLogicでヨーロッパのセールスチームを率いています。データに関連するビジネス上の複雑な問題を解決するために国際的な企業と協力した経験を多く積んでおり、お客さまにとって信頼できるアドバイザーおよびパートナーとなっています。
