How to Connect Matillion ETL to On-Premises Data
Add on-premises data to your cloud data warehouse
Establishing and maintaining a data warehouse is critical for enterprise organizations that want to use quality data to make informed business decisions. ETL tools such as Matillion ETL are often used to access data and pull it into a warehouse.
Matillion ETL is a cloud-native data integration platform designed to work with a wide range of cloud data sources, including Azure Synapse Analytics, Amazon Redshift, Google BigQuery, and Snowflake. It offers users an easy drag-and-drop interface to quickly and easily move data into data warehouses from various sources. While Matillion ETL supports many data sources, it doesn’t have an easy way to integrate on-premises data, requiring complicated VPN configurations to bridge the gap. However, Hybrid Data Pipeline from Progress DataDirect offers a solution to this challenge.
Hybrid Data Pipeline is a light-weight connectivity service that enables secure connectivity to cloud and on-premises data sources. Hybrid Data Pipeline also has the flexibility to work with a variety of data sources and platforms. In addition, rather than requiring complicated VPN setups or SSH tunnels, such as those in the Matillion use case, Hybrid Data Pipeline includes an on-premises agent that allows cloud platforms to securely access data behind a firewall.
This tutorial shows how to connect Matillion ETL to on-premises data using Hybrid Data Pipeline. Here is a high-level view of an integration: 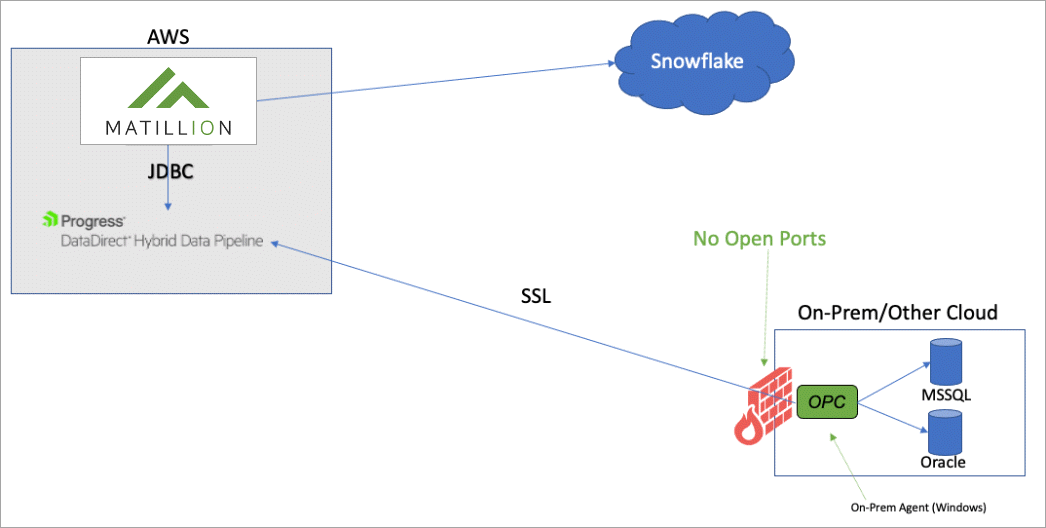
Prerequisites
The following items are required to complete the tutorial:
- The Hybrid Data Pipeline server installer or Docker image
- The On-Premises Connector installer
- The JDBC driver installer
- An active Matillion ETL environment
Download Hybrid Data Pipeline components
The following steps describe how to download Hybrid Data Pipeline components.
- Click the TRY NOW button.
- Provide the required information; then, click DOWNLOAD.
- From the download page, use the tabs to the right to download the Hybrid Data Pipeline server, the JDBC driver, and the On-Premises Connector.
Note: After each download, you may have to use your browser's back button to return to the download page and download the next component.
- Hybrid Data Pipeline: The server may be run on Linux 64-bit machines or as Docker container. Download the server installer or the Docker image based on your preference.
- On-Premises Connector: The On-Premises Connector is supported on Windows 64-bit machines. Download the On-Premises Connector. You will install this component on a Windows host machine that resides behind the same firewall as the data you wish to access.
- JDBC driver: The JDBC driver is supported on Windows and Linux. Download your preferred version. You will add this JDBC driver to your Matillion ETL environment.
Install Hybrid Data Pipeline
The following guides show a number of ways Hybrid Data Pipeline may be deployed.
Note: The Hybrid Data Pipeline server must be configured for SSL during deployment to use the On-Premises Connector to connect to on-premises data sources.
- The Hybrid Data Pipeline Trial Docker Deployment Getting Started: This guide shows you the quickest way to get Hybrid Data Pipeline up and running.
- The Hybrid Data Pipeline AWS Guide: This guide shows you how to install Hybrid Data Pipeline on an AWS EC2 Linux instance.
- The Hybrid Data Pipeline Deployment Guide: This guide shows you the full range of deployment configurations for Hybrid Data Pipeline.
Install the On-Premises Connector
Hybrid Data Pipeline uses the On-Premises Connector to enable connectivity to on-premises data. The On-Premises Connector must be installed on a Windows host on the same network in which the data resides. The On-Premises Connector may only be installed after the Hybrid Data Pipeline server has been installed. During installation of the Hybrid Data Pipeline server, four configuration and certificate files are generated. These files must be copied to the directory from which the On-Premises Connector installation program will be run. For step-by-step instructions on installing the On-Premises Connector, refer to Installing the On-Premises Connector in the Hybrid Data Pipeline Deployment Guide.
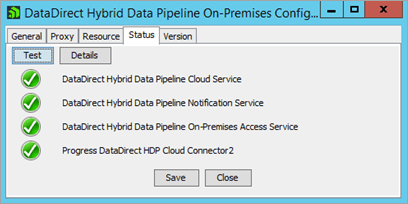
To confirm that the connection between the Hybrid Data Pipeline server and the On-Premises Connector is active, open the Configuration Tool program on the Windows host machine. Then, from the Status tab, click Test. All the tests should return green:
Create a Hybrid Data Pipeline data source
A Hybrid Data Pipeline data source defines the connection parameters to your on-premises data and enables you to access it. Take the following steps to create the data source.
- Open your web browser and enter the URL of the Hybrid Data Pipeline server. For example:
https://MyServer:8443/hdpui
- Sign in using the Hybrid Data Pipeline admin credentials you specified during installation.
- Navigate to the Data Sources view by clicking the data sources icon .
- Click + NEW DATA SOURCE to open the Data Stores page.
- From the list of data stores, click data store to which you want to connect.
- Provide required information in the fields provided under each of the tabs.
Important: From the Connector ID dropdown, select the On-Premises Connector.
- Click Save to create the data source definition.
- Click TEST to establish a connection with the data store.
Install the JDBC driver
You must install the JDBC driver on a machine where you can access the Matillion web interface. As with the On-Premises Connector, the JDBC driver may only be installed after the Hybrid Data Pipeline server has been installed. During installation of the Hybrid Data Pipeline server, four configuration and certificate files are generated. These files must be copied to the directory from which the JDBC driver installation program will be run. For step-by-step instructions on installing the driver, refer to Installing the JDBC Driver in the Hybrid Data Pipeline Deployment Guide.
Add the JDBC driver to Matillion ETL
Take the following steps to add the driver profile to Matillion ETL.
- Connect to your Matillion server using SSH.
- Update the jdbc-providers.properties file according to Adding a third-party JDBC driver in the Matillion ETL documentation. For example, the following JSON code sample defines the driver in a Matillion environment:
{ "name" : "Hybrid Data Pipeline", "driver" : "com.ddteck.jdbc.ddhybrid.DDHybridDriver", "url" : "jdbc:datadirect:DDhybrid://example.com:443", "fetchSize" : "500", "limit" : "top-n", "allowUpload" : "true" } - Restart Matillion ETL using the Admin menu.
- Open the Matillion ETL interface. Then, from the Admin dropdown, select Manage Database Drivers.
- Then, in the Create Jar Group window, select the Hybrid Data Pipeline JDBC driver. The name of the driver will be the you specified in the jdbc-providers.properties file update.
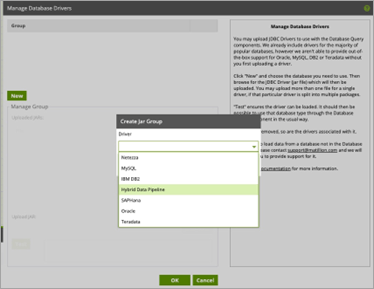
- From the Manage Group window, navigate to the directory where you installed the JDBC driver and select the driver jar file ddhybrid.jar. Then, click Test to verify that the driver has been loaded.
Note: The driver jar file will be located in the lib folder of the driver installation directory. For example:
C:\Program Files\Progress\DataDirect\Hybrid_Data_Pipeline_for_JDBC\lib
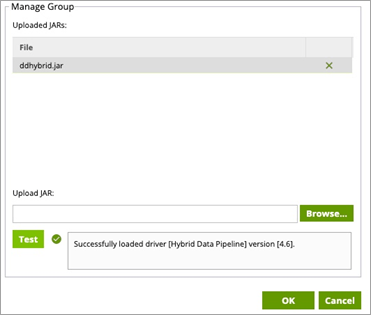
Result: You have successfully integrated the Hybrid Data Pipeline JDBC driver with Matillion ETL. You may now create database queries against Hybrid Data Pipeline data sources.
Create a database query to access your on-premises data
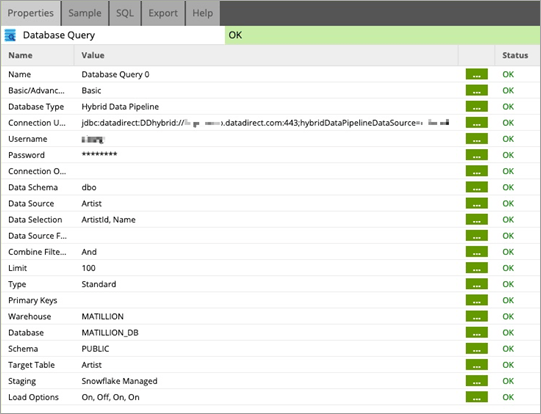
After adding the Hybrid Data Pipeline JDBC driver, you may proceed with a database query in Matillion ETL. The following screenshot captures the parameters of a query using a Hybrid Data Pipeline data source.
Note:
- The connection URL must define the path to the Hybrid Data Pipeline server and provide the name of the on-premises data source you created. For example:
jdbc:datadirect:DDhybrid://example.com:8443;hybridDataPipelineDataSource=MyHDPOnPremDataSource- The username and password parameters should be the username and password of your Hybrid Data Pipeline account.
More information
Thank you for taking the time to consider the Progress DataDirect solution for connecting Matillion ETL to your on-premises data. Please contact us for additional information. Click LEARN MORE for additional information about Hybrid Data Pipeline.