Connectivity for Big Data
Ensure Reliable, High Performance Big Data Operations
 In the years to come, many experts forecast a more than 50% annual growth rate for the 'digital universe'. Gone are the days of the terabyte, as the petabyte now lives at the top of the digital food chain. And if it hasn't already occurred, the zettabyte will soon dominate the data landscape.
In the years to come, many experts forecast a more than 50% annual growth rate for the 'digital universe'. Gone are the days of the terabyte, as the petabyte now lives at the top of the digital food chain. And if it hasn't already occurred, the zettabyte will soon dominate the data landscape.The age of Big Data is upon us – and it is here to stay. As data volume, velocity, variability and variety increase, so do the stresses on today's software infrastructures when they can no longer make sense of data deluge.
Recently Apache Hadoop has made a splash in the marketplace. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using a simple programming model. Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis.
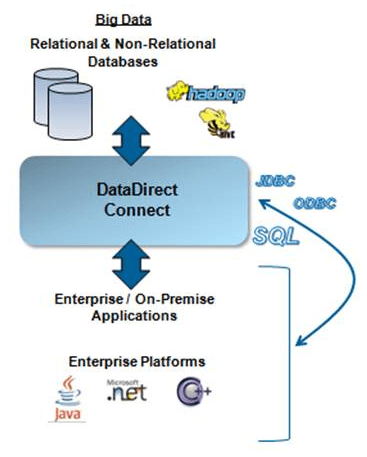
The DataDirect driver for Apache Hive is the only fully-compliant ODBC driver supporting multiple Hadoop distributions out-of-the-box.
The DataDirect Hadoop Hive drivers support the following distributions:
- Apache Hadoop Hive
- Amazon EMR Hive
- Cloudera CDH Hive
- Hortonwork Hive
- MapR Hive
- Pivotal HD Hive
- Data Warehousing
- Data Migration
- Data Replication
- Disaster Recovery
- Cloud Data Publication
Read our Big Data FAQs.
In a well-written, well-tuned application, over 90% 0f data access time is spent in middleware. And data connectivity middleware plays a critical role in how the application client, network and database resources are utilized.
In any bulk load use case scenario, database connectivity is the cornerstone of performance. Over the years, technology vendors made great strides in database optimization as well as the performance of processors and other hardware-based server components. As a result, the performance bottleneck moved to the database middleware – the software drivers that provide connectivity between applications and databases.
Bulk Load – Moving Big Data
As enterprise organizations tackle the challenges of assimilating Big Data within existing data infrastructures, high-performance, scalable and reliable data connectivity is an imperative. Moreover, only when IT organizations employ next-generation data connectivity technologies – such as Progress DataDirect Connect ADO.NET data providers – do they:
- Guarantee the availability of any size data from any source
- Easily move Apache Hive Big Data into any data source
- Manage 'single-driver' connectivity to a wide array of enterprise databases and platforms
- Deliver the best possible bulk load performance, scalability and reliability
- Deploy with no application code changes or database vendor tools
- Reduce the time, cost and risk of making new data sets available to enterprise users

SOLUTIONS
BIG DATA TIPS & TRICKS
BIG DATA WHITE PAPER
»Enterprise Big Data: Here to Stay and Requiring Superior Data Access