
この投稿では、ETL に必要なコストと時間を大幅に削減する方法について取り上げ、MarkLogic がこれにどのように取り組んでいるのかをご紹介します。実際には、MarkLogic の目標は「ETL なんていらない」ということではありません。ここでの目標はデータを「そのまま」読み込み、検索、ハーモナイズ、エンリッチに関して最新のアプローチを取ることです。私たちはこれを「E-L-T アプローチ」(抽出 [Extract]、読み込み [Load]、変換 [Transform] )と呼んでいます。MarkLogic のお客さまは、通常このアプローチを取りますが、それはこの方がより早くアジャイルだからです。つまり、何年もかけずに、数週間または数か月で実稼働を開始できるのです。
話を先に進める前に基本的な話をしておきましょう。まず最初に、従来のデータ統合で必要なプロセスである、抽出、変換、読み込みについて説明します。
- 抽出 – ソースデータベースからデータを取り出すプロセス。このステップには通常、データの抽出だけでなく、抽出が想定どおりに実行されたかを検証することも含まれます。
- 変換 – データのスキーマを他のデータソースと同一になるように変更し、ターゲットデータベースに読み込む前にターゲットスキーマをマッチングさせるプロセス。これには、日付形式の更新のような単純な再フォーマット化や読み込む列の選択などがあります。集計、分解、翻訳、エンコードなどが必要となることもよくあります。
- 読み込み – データを永続的なターゲットデータベースに読み込むプロセス。これには、データ読み込みのタイミングと頻度や、既存データの上書きや拡張に関する戦略的な意思決定が含まれます。
ETL はシンプルな3ステップのプロセスに見えますが、実際にはコストも時間も非常にかかります。
ETL ソフトウェアは値段が高い
ETL プロセスの管理性を高めるために、さまざまなツールが出回っています。ETL ソフトウェアのベンダーには、Informatica(PowerCenter、PowerExchange、Data Services、その他15製品)、IBM(Infosphere 製品スイート)、SAP(Data Services、Process Orchestration、Hana Cloud Integration など)、Oracle(Data Integrator、GoldenGate、Data Service Integrator など)、SAS(Data Management、Federation Server、SAS/ACCESS、Data Loader for Hadoop、Event Stream Processing)、オープンソースの Talend(Open Studio、Data Fabric など)などがあります。言うまでもなく、ETL 市場に参入しようとしているベンダーはたくさんいます。個人的には、同じベンダーが同じお客さんに売ろうとしている ETL ツールの多さには驚くばかりです。
毎年、データ統合のため ETL ソフトウェアに費やされる総額は35億ドルに上ります(ガートナー「Forecast: Enterprise Software Markets, Worldwide, 2013-2020, 1Q16 Update」2016年3月17日)。これらのツールはすべて、オペレーショナルデータベースまたはデータウェアハウスへのデータ移動を準備するものです。しかしプロジェクトの時間と資金のうち、ETL が占める割合は異常に大きくなっています。実際、データウェアハウスプロジェクトの総コストの60~80パーセントを、ETL ソフトウェアおよびプロセスが占める場合もあります(TDWI『Evaluating ETL and Data Integration Platforms』)。
ETL には多くの時間とマンパワーが必要
ツールの購入にはお金がかかりますが、それだけでは終わりません。ETL ツールとデータベースをつなぎ、使用・管理するには多くの作業が必要です。ツールの設定後にも、データソースをまとめたり、すべてのデータモデリングを行ったり、プロセス全体で発生する変更を管理したりするために、さらに多くの作業が発生します。ある情報によれば、Fortune 500 企業における典型的な大規模データ統合プロジェクトは、完了するまで(プロジェクトのキックオフからアプリケーションの本番稼働まで)に2~5年もかかるそうです。世界全体では、ETL およびそれに付随するデータ統合作業の合計コストは年間約6000億ドル近くに上ります(MuleSoft による概算)。私にはこの数字は大き過ぎるように思えますが、いずれにせよ、ETL は非常にお金がかかる問題だという点に異論はないでしょう。
ETL にかかるコストと時間を削減
MarkLogic では、データ統合問題解決へのアプローチが異なります。では具体的にはどのように違うのでしょうか?
第一に MarkLogic では同一データベース内で複数のスキーマを扱えます。つまり、データをそのまま読み込むことができ、事前に定義された1つの「スーパースキーマ」に一致させる必要はありません。これにより作業が加速し、リレーショナルデータベースの場合に発生する、変更や新規データソースの追加の際の面倒なやり直しの多くを回避できます。
第二に MarkLogic 内部で、データのハーモナイズとエンリッチが可能です。つまり、MarkLogic にデータを直接読み込んだ後で、トランザクショナルデータベースに備わった信頼性を維持しながら、あらゆる変換作業(ETL の「T」)を行うことができます。また、他のツールの購入や保守も不要です。
では、どの程度コストと時間を節約できるのでしょうか?
典型的な MarkLogic のデータ統合プロジェクトは、リレーショナルデータベースと ETL ツールによる従来のデータ統合に比べて、最大4倍も早くなります。このスピードは、さまざまな業界において複数の大型プロジェクトで実証されています。優れているのはスピードだけではありません。実際のところ、結果的に得られるデータの質も向上しています。この点については後ほど詳しく取り上げますが、まずは、従来のデータ統合手法を見ていきましょう。
リレーショナルデータベースと ETL の課題
サイロに分断されたデータを統合する場合、ほとんどの組織では多数のリレーショナルデータベースを対象とし、全てのリレーショナルデータベースのデータを別の1つのリレーショナルデータベースに効率的に移動しようとします。
データ統合を行いたい理由としては、以下のようなものが一般的です。
- レガシーデータを必要とする新規アプリケーションの開発
- 分析用データウェアハウスでデータの360度統合ビュー(全体像)を得る
- 新規のマスターデータ管理(MDM)システムを構築する
- 社内または社外で、業務システム間でデータを移行する
- ガバナンス、監査、その他のモニタリング用
- M&A
- データを破棄せずにずっと保存していたい
プロジェクトの対象、データソースのタイプ、使用されるツールに応じて、データ統合プロセスの各シナリオは若干異なります。どのような使用パターンであっても、一般的なプロセスには常に ETL が大量に存在し、多種多様なデータを単一のスキーマに適合するように均一化します。このプロセスは、通常は以下のようになります。
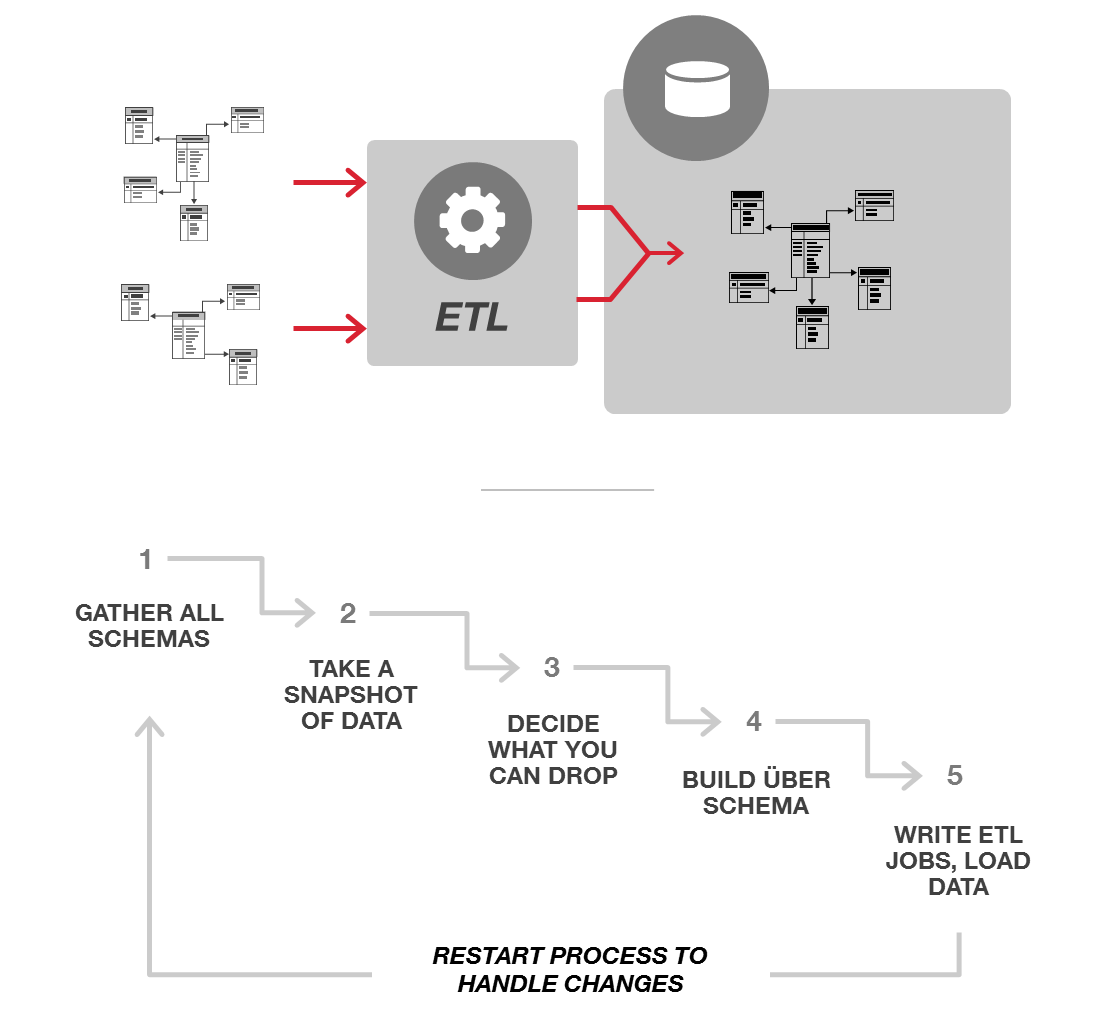
1. すべてのスキーマを集める
まず、どのようなデータがあり、それらがどのような構成になっているのかを把握する必要があります。このためには、スーパーセットへのデータの格納方法を示すすべてのスキーマを集める必要があります。ふつうはこの情報はデータベースの中にはありません。通常、スキーマは ER図で表現されます。この図は多くの場合、印刷して壁に貼られたり、フォルダ内のどこかに保存されています。さまざまな組織のコンサルティングを行ってきた私の経験からいうと、一番古くからいる DBA がそのファイルを持っていることが多いようです。
2. スキーマを分析する
すべてのスキーマを手に入れたら、その意味、機能、共通点を把握する必要があります。これらをちゃんと理解するには、データ(場合によってはコード)を確認する必要がある場合もあります。例えば、顧客というエンティティがある場合、データベース内の「顧客」とは何か、またそれがビジネスとどのように関連しているかを明確に把握するために、さまざまなテーブルのさまざまな行を確認する必要があります。
3. 何を使用しないかを決める
すべてのスキーマを統合しすべてのデータを格納しようとしても、なかなかうまくいきません。そのため通常は、それほど重要でないデータを特定し、現在のプロジェクトで本当に必要なデータだけを扱うようにします。例えば、あるデータ統合プロジェクトにスキーマが30個含まれている場合、一部の「優先度の低い」データを扱わないことで30回もモデリングしなくても良いようにするのが自然です。例えば、データを組み合わせて使うアプリケーションでは、その過程で扱った初期モデル内のトランザクションステータスは不要でしょう。あるいは配送先住所がなくても問題ないかもしれません。また、顧客あたり電話番号は1つだけにすれば、モデルはシンプルになります。
4. スーパースキーマを作成する
次に「すべてを支配する1つのスキーマ」を作成する必要があります。これは、あらゆる異なるソースシステムからのデータのうち、利用すると決めたものすべてに対応できるスキーマです。新しいスキーマの考案に加えて、型付きのフィールド内の不正なデータのような例外すべての処理方法、各データ要素のソースに関するメタデータの持ち方、新しいスキーマに合わせるための変換などについて決定する必要もあります。また、時間の経過に伴うデータやスキーマの変更を捕捉したい場合は、それらすべてのバージョン管理の方法も決めなくてはなりません。
5. ETL ジョブをプログラミングしてデータを読み込む
この段階まで無事進んだら、やっとデータを移動できます。必要な変換がすべて完了していることを確認してから、変換済みのデータをすべて新しいデータベースに一括で読み込みます。
6. 変更があった場合、このプロセスを再度実行する
新しいデータソースが追加されたり、スキーマに影響を与える別の変更が処理中にあった場合は、最初に戻ってステップ1から再度実行しなければなりません。幸運にも新しいデータソースを既存のスーパースキーマに適合させることができれば別ですが、通常は、新しいデータソースによって、新しい多対多の関係や、変更を必要とする異なるデータ概念が発生します(また、下流の既存のアプリケーションにも影響を与えます)。例えば、1人当たりの住所は1つだけであるはずなのに住所がたくさん出てきたり、1つのテーブル内に VARCHAR がたくさんあるのに遭遇した経験があるはずです。
「ETL」に対する MarkLogic のアプローチ
MarkLogic のデータ統合プロセスは、もっとシンプルでスピーディです。
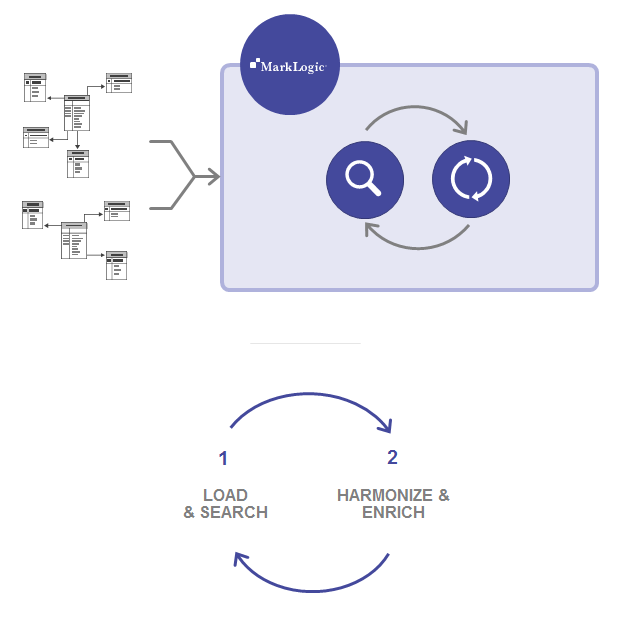
1. データをそのまま読み込む
最初のデータソースをいくつか MarkLogic にそのまま読み込んだら、MarkLogic の強力なビルトインの検索機能(「何でもクエリできる」ユニバーサルインデックス)を利用して、すぐにデータを理解できます。すべてを支配する1つのスキーマを作成する必要はありません。他のデータはたとえスキーマが違っていたとしても、継続して読み込めます。MarkLogic は同一データベース内で複数のスキーマを容易に処理することができます。またすべてのデータがすぐに検索対象となります。
2. データをハーモナイズする
これは ETL の「T」に似ていますが、従来の ETL とは2つの重要な点で異なっています。まず、どのデータも破棄する必要がありません。次に、すべてのデータを変換する必要はありません。例えば、あるスキーマでは「Postal Code」、他のスキーマでは「Zip」となっていた場合、すべて「Zip」でクエリできるように、データ内のこれらの要素のみを変換できます。しかしハーモナイズの場合には、「Postal Code」となっていた元のデータを破棄する必要はありません。MarkLogic がこれをどう行うのかについて、以下で詳しく説明します。
3. データをエンリッチする
データのハーモナイズに加えて、エンリッチにより、ビジネスのコンテキストと意味を追加できます。サイロからの生データを新しいデータや拡張データで拡張することで、新しいアプリケーション、機能、分析を実現できます。例えば、住所を含むレコードがある場合、GPS 座標を追加するだけでそのデータをエンリッチできます(このようなスキーマ変更は、MarkLogic のドキュメントモデルではまったく問題ありません)。
4. さらにデータを読み込む
MarkLogic のデータ統合は反復的であり、「ビッグバン」のように一度ですべて終わる訳ではありません。ここではデータを継続して読み込み、必要に応じてデータモデルを進化させます。
このやり方では、必要なことは MarkLogic 内ですべて実行できるため、データ統合のためにETLツールが必要ないことを知ったお客さまからは、ご好評いただいています。これによってプロセスがシンプルになり、多くのコストを節約できます。
またプロセスがかなり高速になり、約4倍もスピードアップします。多くの Fortune 500 企業において MarkLogic と従来のリレーショナルデータベース + ETL のアプローチを直接比較してみると、大規模な MarkLogic プロジェクトは通常6か月で完了し、一方従来のアプローチでは2年かかっています。以下の図を見ると、一般的にどの部分の時間が短縮されるのかがわかります。
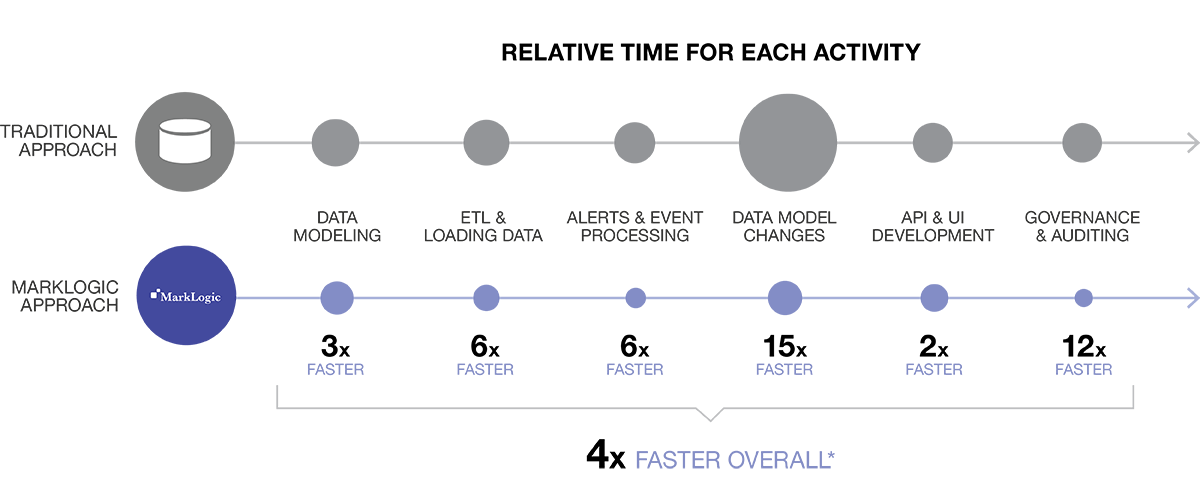
* Fortune 500 企業での実際の比較データと、あらゆる業界のその他の顧客企業におけるプロジェクトの平均時間に基づく
プロジェクトのスケジュールが短縮されるだけでなく、結果の質も大幅に良くなります。別のサイロをさらに作り出すのではなく、スキーマに依存せずにすべてのデータを管理し、意味のあるビジネスコンセプトを介してすべてのデータを互いに関連付けます。また、信頼性の高いトランザクショナルな方法でデータを格納します(ほかの NoSQL データベースとは異なり、MarkLogic は100% ACID 準拠のマルチドキュメントトランザクションを実行できます)。
MarkLogic を使用すると、終わりのない ETL サイクルに頼ることなく、「ビジネスの遂行(run the business)」と「ビジネスの観察(observe the business)」の両方を行えます。データは成長し続けます。サイロ間でのデータ移動に時間とエネルギーを費やすのはもうやめましょう。サイロ間のデータの移動自体には価値はないため、これは少なければ少ないほどよいのです。
詳細な手順
次に、このプロセスの各ステップについてもう少し掘り下げます。サイロデータの統合の際に、MarkLogic がこれをどのように実現するのかを理解していきましょう。
ステップ1 – データをそのまま読み込む
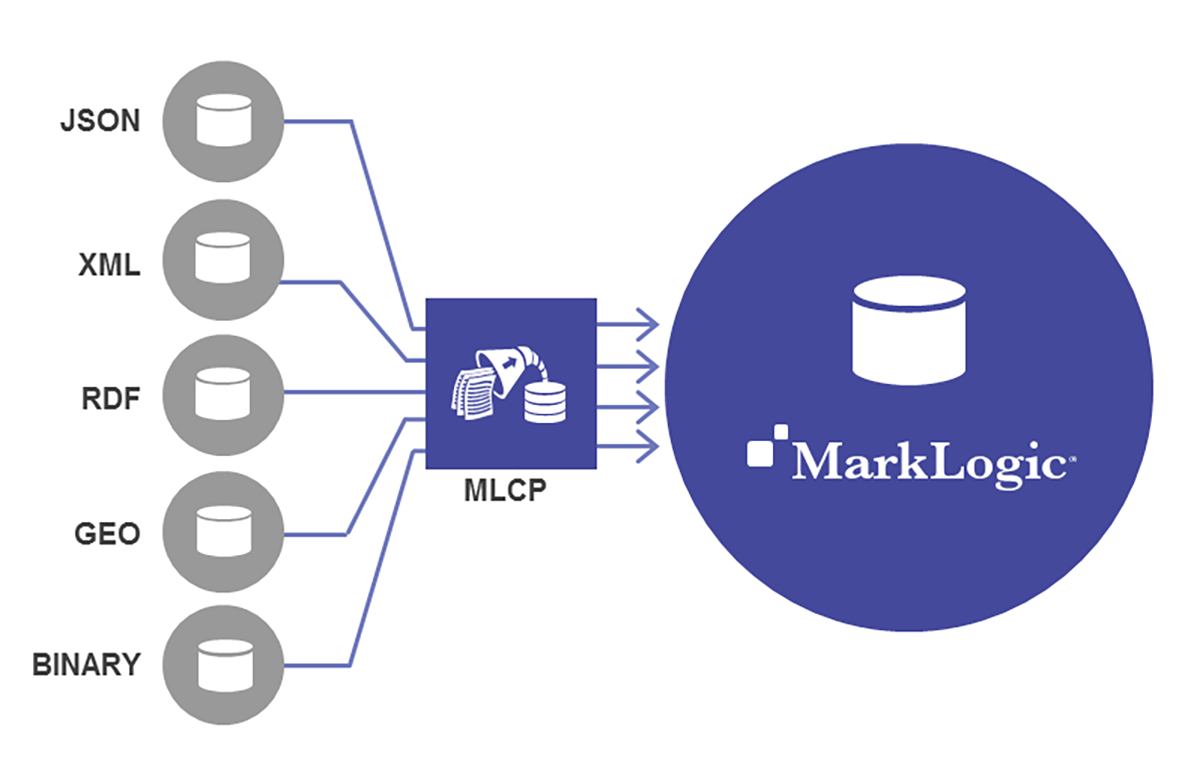
MarkLogic はスキーマに依存しません。柔軟なデータモデルを使って、データを JSON および XML ドキュメント(および RDF トリプル)として保存します(本稿ではドキュメントのみについて説明します)。ドキュメントは柔軟であり、データ構造は階層型です。固定的な行および列はありません。MarkLogic はさまざまな形式のドキュメントを受け入れて管理できます。つまり、MarkLogic は同一データベース内で複数のスキーマを扱うことができ、データを「そのまま」読み込めます。つまり、以下のようになります。
- スーパースキーマを作成し、すべてのデータをデータベースへの読み込み前にこれに合わせて変換する必要はありません
- 一部のデータは今すぐ読み込み、残りは後で読み込むことができます。全部いっぺんに無理して読み込む必要はありません
- データ読み込み前の準備や変換のための ETL ツールは不要です
一般的に、データは mlcp(MarkLogic Content Pump)というツールで一括読み込みされることが多いです。mlcp は効率的で強力なツールであり、読み込み時に変換もできます。しかし MarkLogic にデータを入れてから、ハーモナイズ用にデータを変換することもできます(詳細は MarkLogic University の短いオンデマンドチュートリアルビデオをご覧ください)。mlcp 以外では、REST API、Java Client API、Node.js Client API、ネイティブの Java / .NET コネクタなどでデータを読み込めます。
データは読み込まれた後、すぐに検索の対象となります。これは MarkLogic の「何でもクエリ可能な」ユニバーサルインデックスがすぐに付けられるからです。これは Google 的な検索です。つまり、キーワードで検索して、そのキーワードが含まれるドキュメントが返されます。
データ統合において、ビルトインの検索機能は非常に重要です。例えば前述の例において、読み込まれた顧客レコードドキュメントに、郵便番号が含まれていたとします。しかし、郵便番号が「Zip Code」となっているレコードと、「Postal Code」となっているレコードがあります。MarkLogic では「94111」と検索し、この郵便番号のレコードをすべて見つけられます。リレーショナルのデータ統合プロジェクトでば、読み込む前にすべてのレコードをハーモナイズする必要があります。そうしなければ、Zip Code で検索しても実は同じ郵便番号である他のデータを取得できません。将来実際にクエリで使うかどうかわからなくても、とりあえずすべてのソーススキーマのすべてのエンティティのすべての属性をハーモナイズする必要があり、これには長い時間がかかります。しかしこのようにハーモナイズしなければ、利用できないのです。
「そのまま(アズイズで)読み込む」フェーズの詳細については、ブログ「What Load As Is Really Means」をご覧ください。
ステップ2 – データをハーモナイズする
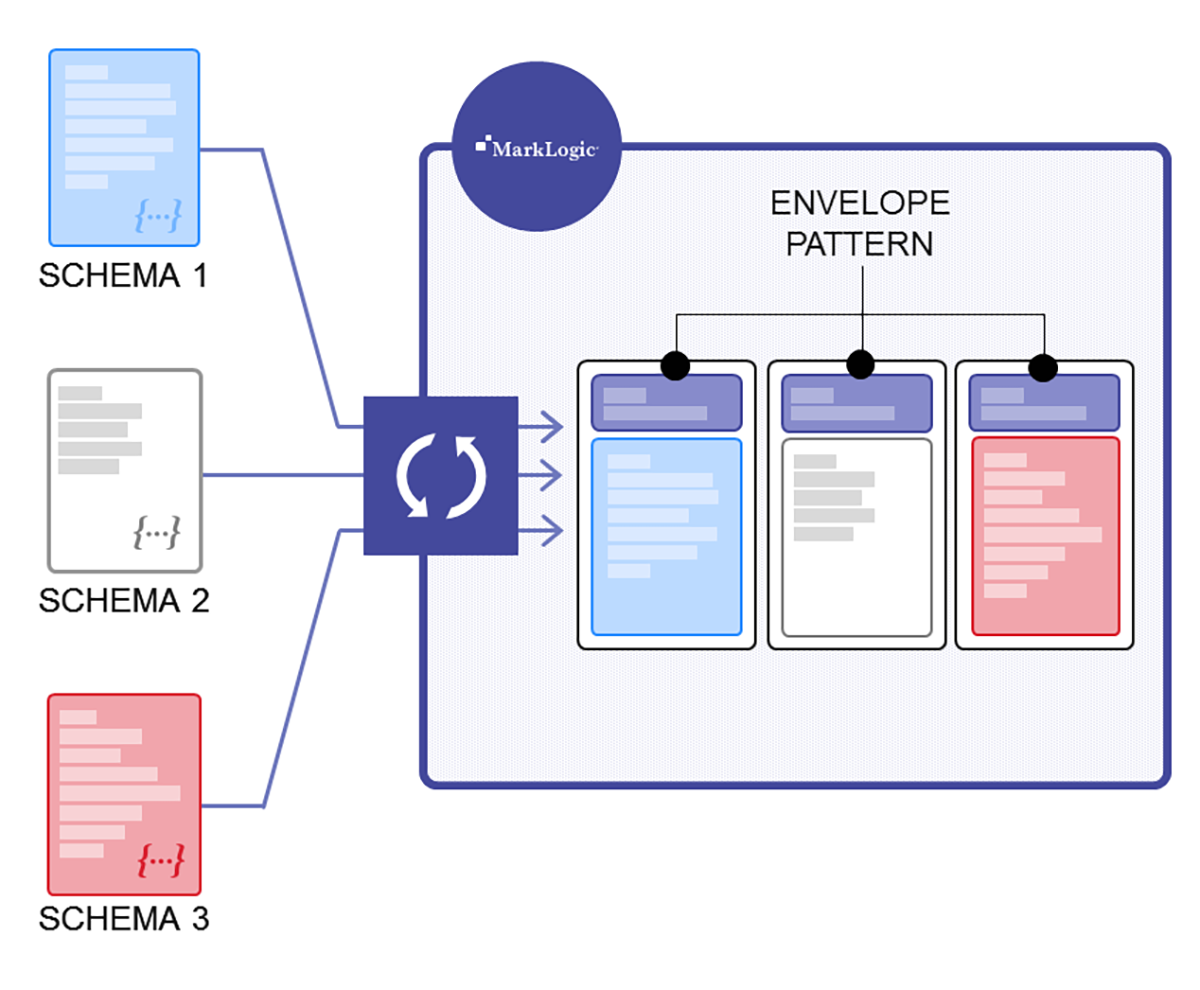
データを読み込んでどのようなデータなのかを確認したら、次は「一貫性のあるクエリを実行するうえで、実際にハーモナイズの必要があるのはデータのどの部分か」ということを考えます。それがいかに奇抜なものであったにせよ、慣用的な表現(=ネイティブ/生)のデータをそのまま取り込み、これに基づいてクリーンで基準となる(カノニカルな)表現を作成します。
例えば、アプリケーションで郵便番号を使うのであれば、これをハーモナイズすることは大事でしょう。一方、個々人の好きなサッカーチームのリストのレコードは、そのままにしておくことができます。MarkLogic のインデックスを使えば、サッカーチームに関するクエリも実行できますが、その際に、すべてのデータソース対するクエリにおける一貫性はそれほど重要ではないでしょう。
ハーモナイズの対象を決めたら、エンベロープパターンを利用することで、進化するカノニカルモデル(合意したデータ定義を保持するシンプルなデザインパターン)を作成できます。エンベロープパターンは、データ統合における MarkLogic のベストプラクティスで、一貫性のあるクエリの対象としたいカノニカルな要素のみを含むエンベロープを作成します。つまり「Zip」が必要ならば、この要素をエンベロープに入れます。また後から「City」、「State」、「Favorite NFL Team」などを簡単に追加できます。
以下に、エンベロープパターンの例を示します。それぞれの JSON ドキュメントでは、元のソースデータが新しいルート(プロパティ「source」)として追加されています。
// Document 1:
{ "envelope" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
// Document 2:
{ "envelope" : { "Zip" : [ 94111 , 94070 ] } ,
"source" : { "Customer_ID" : 2001 ,
"Given_Name" : "Karen" ,
"Family_Name" : "Bender" ,
"Shipping_Address" : {
"Street" : "324 Some Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Postal" : "94111" ,
"Country" : "USA" } ,
"Billing_Address" : {
"Street" : "847 Another Ave" ,
"City" : "San Carlos" ,
"State" : "CA" ,
"Postal" : "94070" ,
"Country" : "USA" } ,
"Phone" : [
{ "Type" : "Home" , "Number" : "415-555-6789" } ,
{ "Type" : "Mobile" , "Number" : "415-555-6789" } ] }
}
この例の場合、「Zip」でハーモナイズすることが重要です。なぜなら、ここで作ろうとしているアプリケーションは、各地域の顧客数と購入品目を表示し、さらに製品カテゴリ、タイプ、製品説明を確認できるものだからです。地域は郵便番号で定義されているため、「Zip」を使ってクエリに一貫性があるようにする必要があります。
MarkLogic では、エンベロープを非常に簡単に追加できます。それがいかに簡単かを示すために、エンベロープを JSON プロパティとして追加する更新クエリを紹介します。
declareUpdate (); //get all documents from the “transform” collection
var docs = fn.collection(“transform”);
for (var doc of docs) {
var transformed = {}; //add a property as an empty object to add further data the original document
transformed.envelope = {}; //save the original document in a new property called “source”
transformed.source = doc;
xdmp.nodeReplace(doc, transformed);
}
エンベロープパターンを使用することで、カノニカルなデータモデルをアジャイルに一から作成できます。このモデルは、このデータを使用するあらゆるアプリケーションとサービスのすべての要件を満たすことができます。各アプリケーションは、このモデルの一部分だけを利用します。また、各レコードには一貫性のあるカノニカルなフォームが含まれているため、上流システムのソーススキーマを把握しなくても、誰でも簡単に MarkLogic からのデータを利用できます。
ステップ3 – データをエンリッチする
では、単にデータの変換やハーモナイズをするだけでなく、データの価値を高めたい場合はどうすればよいでしょうか。ここで役立つのがデータのエンリッチです。このステップは必須ではありませんが非常に有用であり、重要な情報を関連データに直接結び付けます。ほかのデータベースでは通常、こうした情報は存在しないか、見つけるのが困難です。
以下の例では、データソース、読み込んだ日、データのリネージの情報が、「metadata」としてドキュメントに追加されています。
{ "metadata" : {
"Source" : "Finance" ,
"Date" : "2016-04-17" ,
"Lineage" : "v01 transform" } ,
"canonical" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
例えば、地理情報(座標)などの重要な情報を追加したい場合もあります。このようなスキーマ変更はリレーショナルデータベースでは非常に難しいですが、ドキュメントモデルでは信じられないほど簡単です。
{ "metadata" : {
"Source" : "Finance" ,
"Date" : "2016-04-17" ,
"Lineage" : "v01 transform"
"location" : "37.52 -122.25", } ,
"canonical" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
もう1つのステップ(オプション) – セマンティックの追加
ここまでドキュメントモデルの長所について説明してきましたが、MarkLogicはそれだけではありません。セマンティックトリプルを加えた場合、上述のような単純な変換に加えて、MarkLogic のマルチモデル機能を活用していろいろなことができます。例えば、トリプルをメタデータとして追加しドキュメント同士を関連付けることで、データ内のさまざまな関係に基づいた結合とクエリが簡単にできます。例えば、顧客 1001 が発注 8001 を行い、発注 8001 には製品 7001 が含まれているとします。トリプルを使うと、顧客 1001 が製品 7001 を発注したと推論できます。これらは、有意義な関係性を示す3つのシンプルなファクトであり、トリプルとしてモデリングするのが自然です。また、MarkLogic ではデータとクエリを組み合わせて一緒に扱えるので、ドキュメントとトリプルの両方を対象としたクエリができます。この機能は、他のエンタープライズデータベースにはない独特なものです。
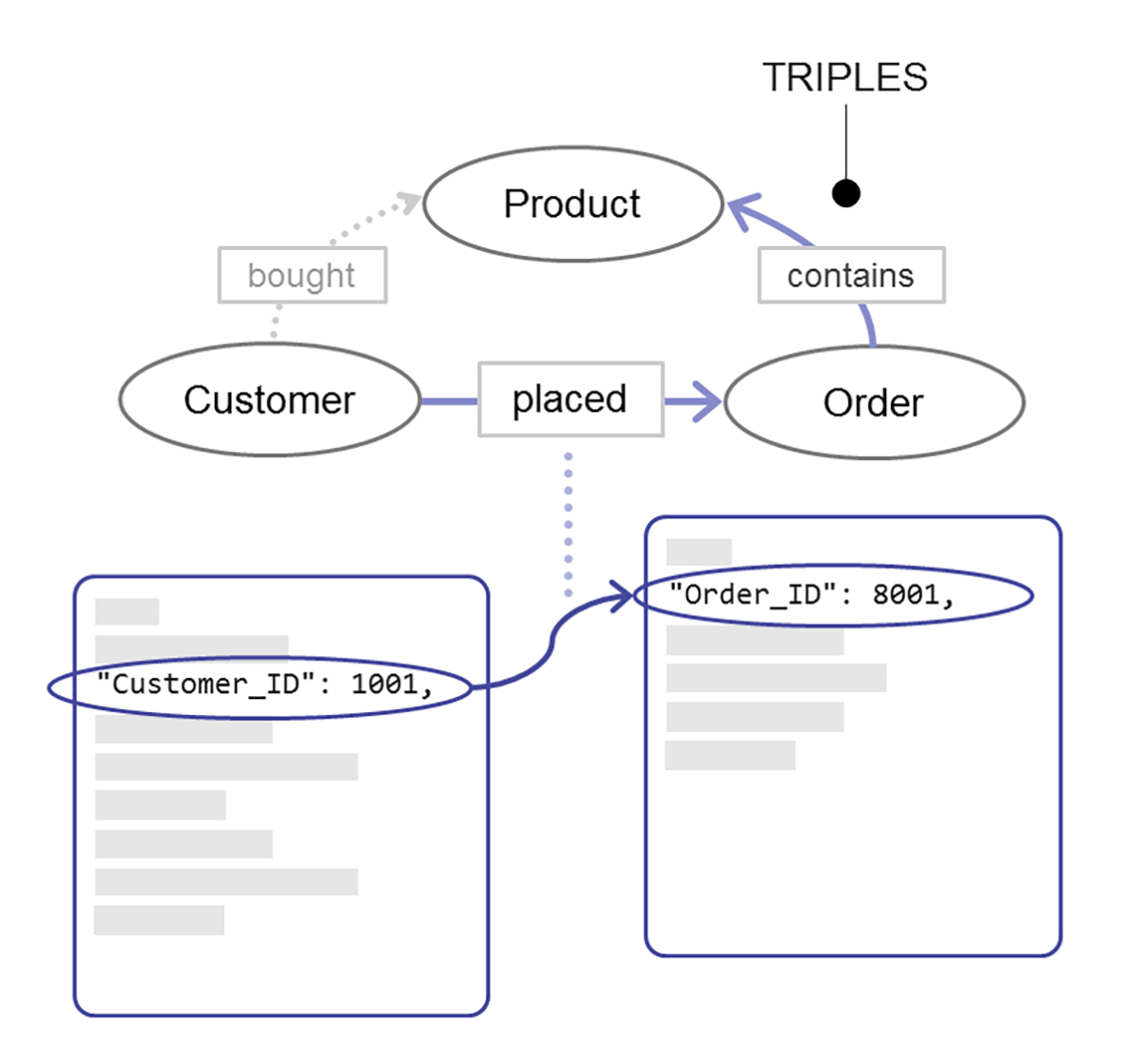
リレーショナルデータベースでは、実はリレーション(関係性)は非常に弱いです。セマンティックを使用すれば、意味のあるグラフを活用できます。データ統合におけるセマンティックの活用については他にもいろいろ話したいことがありますが、別の投稿で取り上げているのでこのへんでやめておきます。
ハーモナイズ方法(セマンティックなど)の詳細については、MarkLogic University の新しいオンデマンドトレーニングコース「Progressive Transformation Using Semantics」をお勧めします。
ステップ4 – さらにデータを読み込む
事前に定義した1つのスキーマに従ってすべてのデータを読み込むのではなく、MarkLogic では、使用中のカノニカルなスキーマに一致しなくても、新しいデータソースを継続的に読み込んでいけます。
このように新しいデータソースをすべてそのまま読み込み、その後、継続的に進化し続けるエンベロープ部分に、その新しいデータのどの部分を取り込むのかを判断します。ソーススキーマにカノニカルスキーマに対応するものがない場合(たとえば、郵便番号がないなど)、エンベロープには何も入れません。何か新しいものをカノニカルモデルに加えたい場合は、単にそれを追加するだけです。その際にデータベース全体を再構築する必要はありません。なぜなら、新しいスキーマの統合によるカノニカルモデルの変更は、既存のデータ、データを使用するアプリケーション、サービスに一切影響しないためです。
MarkLogic がもたらす最終的な成果
MarkLogic の大きな利点の1つは、データ統合プロセスを最大4倍もスピードアップできることです。プロジェクトを6か月で(2年ではなく)完了できることは極めて重要です。浮いた時間でいろいろなことができるでしょう。MarkLogic のアジャイルなプロセスは、リレーショナルデータベースと従来の ETL の組み合わせよりも優れていてかつ高速であり、オペレーショナルデータハブ構築の際のサイロからのデータの取り込み、MarkLogic 内での変換を簡単に行えます。MarkLogic の「ELT」(=そのまま読み込んでハーモナイズ)アプローチが従来の ETL よりも優れていて簡単である理由を、以下にまとめました。
- ソースデータをそのまま読み込み、検索できる
- リネージ、出自、その他のメタデータを保持できる
- 必要なものだけをハーモナイズできる
- 再読み込みせずにモデルを後から更新できる
- 新しいスキーマが既存のデータ/アプリケーションに影響しない
MarkLogic のアプローチのもう1つの大きな利点として、データガバナンスに強いことがあります。データガバナンスが重要なのは、往々にして、データ統合が必要なアプリケーションは1つだけではないためです。最初は1つでしか利用されないかもしれませんが、より大きな目標は、サイロが生み出されるサイクルを完全に断ち切り、データを一元化、統合し、さまざまな方法で利用できるようにすることです。ここで避けたいのは、1つの方法でしか利用できない新しいサイロを作り出すことなのです。
サイロのサイクルを断ち切るためには、新しいデータハブのデータガバナンスについて考慮する必要があります。これには、セキュリティ、プライバシー、ライフサイクル、データ保持、コンプライアンスなど、このデータを使用するアプリケーションとは独立して存在する、データに関するポリシー規則が含まれます。
まず、リネージと出自はデータガバナンスにおいてどのような役割を果たすのでしょうか。MarkLogic では、各属性がどこから来たか、いつ抽出されたか、どのような変換が実行されていたか、また変換前の状態を把握できます。ETL 処理によって何かが損なわれることはありません。MarkLogic はスキーマに依存しないので、ソースデータ、カノニカル(変換された)データ、メタデータすべてを同じレコードに含めることができ、そのすべてに対してクエリを実行できます。このアプローチでは、組織内でのデータ移動や変換プログラムのバグ修正の時間が減るので、アプリケーション構築やデータからの真の価値創出に使える時間が増えます。一元化された統合ハブにデータをまとめトラッキングすることにより、セキュリティ、プライバシー、コンプライアンスに関しても利点が得られます。
次のステップ
このトピックには学習すべき点が数多くあります。今回の投稿では、MarkLogic がデータ統合に最適である理由を少し詳しく見てきました。さらに詳しく知りたい場合は、以下のリソースをお勧めします。
- Escape the Matrix★ – エンジニアリング担当 SVP の David Gorbet(デイヴィッド・ゴーベット)による聞きごたえのある基調講演です。MarkLogic のアプローチが従来の ETL とどう違うのか、詳細を掘り下げています。特定のモデリングの例を挙げ、セマンティックについて説明しています。
- Progressive Transformation オンデマンドチュートリアル – MarkLogic University による16分の概要チュートリアルです。段階的な変換の実行方法を取り上げています。実際に使用するクエリの紹介など、かなり詳しく説明しています。
- Decimating Data Silos With Multi-Model Databases – マルチモデルアプローチの詳細を説明します。また、オペレーショナルデータハブを構築する際の MarkLogic のさまざまなアプローチの長所と短所についても取り上げます。

マット・アレン
マット・アレンはプロダクトマーケティングマネージャー担当副社長で、業種を問わずMarkLogicのすべての機能とメリットのマーケティングを担当しています。具体的には、製品・エンジニアリングチームとセールス・マーケティングチームを連携し、MarkLogicの技術について説明し、その導入メリットを伝えるコンテンツやイベントの制作に携わっています。カリフォルニア州サンカルロスにあるMarkLogic本社に勤務しています。仕事以外では、大型の油絵を描く画家でもあります。
