
私たちは今、データベース業界における世代交代の真っ只中にいます。しかし、変化することは難しく、常に抵抗に遭うものです。この市場においては、40年以上にわたってリレーショナルデータベースの人気が最も高く、世界中の極めて重要なシステムで利用されています。
そして、「NoSQL」が登場しました。後から登場したこれらのNoSQLデータベースは、いろいろなことができると主張していますが、どうやってそれを実現するのでしょうか。MarkLogicは大規模なデータ統合プロジェクトのスピードを4倍にすると主張しています。また、構造化データだけでなくあらゆるデータを扱うことが可能で、変化にもより迅速に適応でき、拡張も簡単になると言っています。
こういった主張に対して疑義を唱えることは簡単です。疑念は、通常以下の2種類に分けられます。
- 「リレーショナルデータベースに問題がある」ということに対する疑い
- 「NoSQLが本当に問題を解決できる」ということに対する疑い
ここでは2部構成で、これらの疑いに反論し、リレーショナルデータベースの問題点について理解が深まるようにしたいと思います。まず最初に、リレーショナルデータベースに問題があるという主張に対する疑いから始めましょう。
「リレーショナルデータベースに問題がある」ということに対する疑い
これまでの一連のブログで、リレーショナルデータベースは変化に対応するようには作られていないこと(「relational databases are not designed for change」)、また拡張、多様なデータ、複数の処理、現代的なアプリケーション開発向けには設計されていないことを説明してきました。このブログに対するコメントとして、多くの方々からたくさんの素晴らしい質問をいただきました。そこで、個々の質問に答える代わりに、寄せられた一般的な反論にお答えするため、このブログを書くことにしました。理解が深まる(あるいは議論がより健全なものとなる)ためにいくつかの回答を準備しました。
プロジェクトがはかどらない、あるいは終わらない本当の原因は、読み込み前にデータを1つのスキーマにモデリングしなくてはならないからです。もちろんこのスキーマは変更できますが、いずれにせよ、このスーパースキーマに閉じ込められてしまうことには変わりありません。新規データソースの追加や、予想もモデリングもしていなかったクエリを利用したい場合、これが極めて大きな問題となります。
確かに段階的な変更(表の追加や列のデータ型の変更など)は比較的簡単かもしれません。1列変更するのに1億円かかると言ったのは確かに大げさでした(私たちの大口顧客の一社においては、実際にそのようなことが起こっていますが)。
しかし他のもっと複雑な変更の場合はどうでしょうか。
複雑な変更の例としては、根本的な「顧客特性」があります。ここでは個々のデータが時間とともにどのように変化していくのかを扱います。例えば、顧客、注文、店舗に関するデータが先月どうなっていたか、また現在どうなっているかについて一緒にクエリしたいとします。リレーショナルデータベースの場合、これらの情報は複数のサイロ内に複数の表として分散している可能性があります。また異なる時点を反映した複数のバージョンが存在する可能性もあります。リレーショナルデータベースでは、概念データモデリングの変更によって、データベースやミドルウェア、アプリケーションスタック内のものが壊れてしまうことが多々あります。つまり変更に対応し、複雑なクエリを実行することは不可能です。
しかも変更はたった一回で済む訳ではありません。データは常に変わり続けますし、データの新規追加や削除のたびに変更を施さなければなりません。このような環境において、静的なリレーショナルデータベースを使って一元的で統合された概念/物理モデルを構築することは不可能です。また、セントラルオペレーショナルデータハブを業務に使っている場合、このデータベースをちょっと止めるという訳にはいきません。これは「飛行中の飛行機の左右の翼を入れ替える」くらいの離れ業ですが、これにはかなりお金がかかるというだけでなく、実質上不可能です。
こういったことは、あらゆる用途や組織において常に大問題となるわけではないかもしれません。しかし私たちがお手伝いしてきた多くの企業にとっては、間違いなく大問題となっています。この手の問題の解決には、通常、2~5年、また数億円かかります。例えば、ある大手銀行のお客様は規制に対応しなければなりませんでした。フロントオフィスの取引システムが数十種類あり、使われているデータモデルはすべて異り、またよく変更されていました。彼らは2年間にわたってオラクルでスーパースキーマを構築しようとしましたが、結局諦めました。その後、MarkLogicを使って6か月で新規システムを稼働させました。これは「細かいことは後回し」にしたための選択ではありません。
このシステムは今や銀行業務の基盤となっています。この銀行がMarkLogicを選んだのは、データモデリングを反復的かつ柔軟に行いたかったからです。またデータを1つのアプリケーションだけではなく、多数のアプリケーションで使いたかったからです
この例は何も特別なものではありません。リレーショナルよりもプロジェクトの完了が4倍速くなるということはよくあるのです。あるフォーチュン500の保険会社の場合、データモデリングはリレーショナルよりも15倍速くなりました。
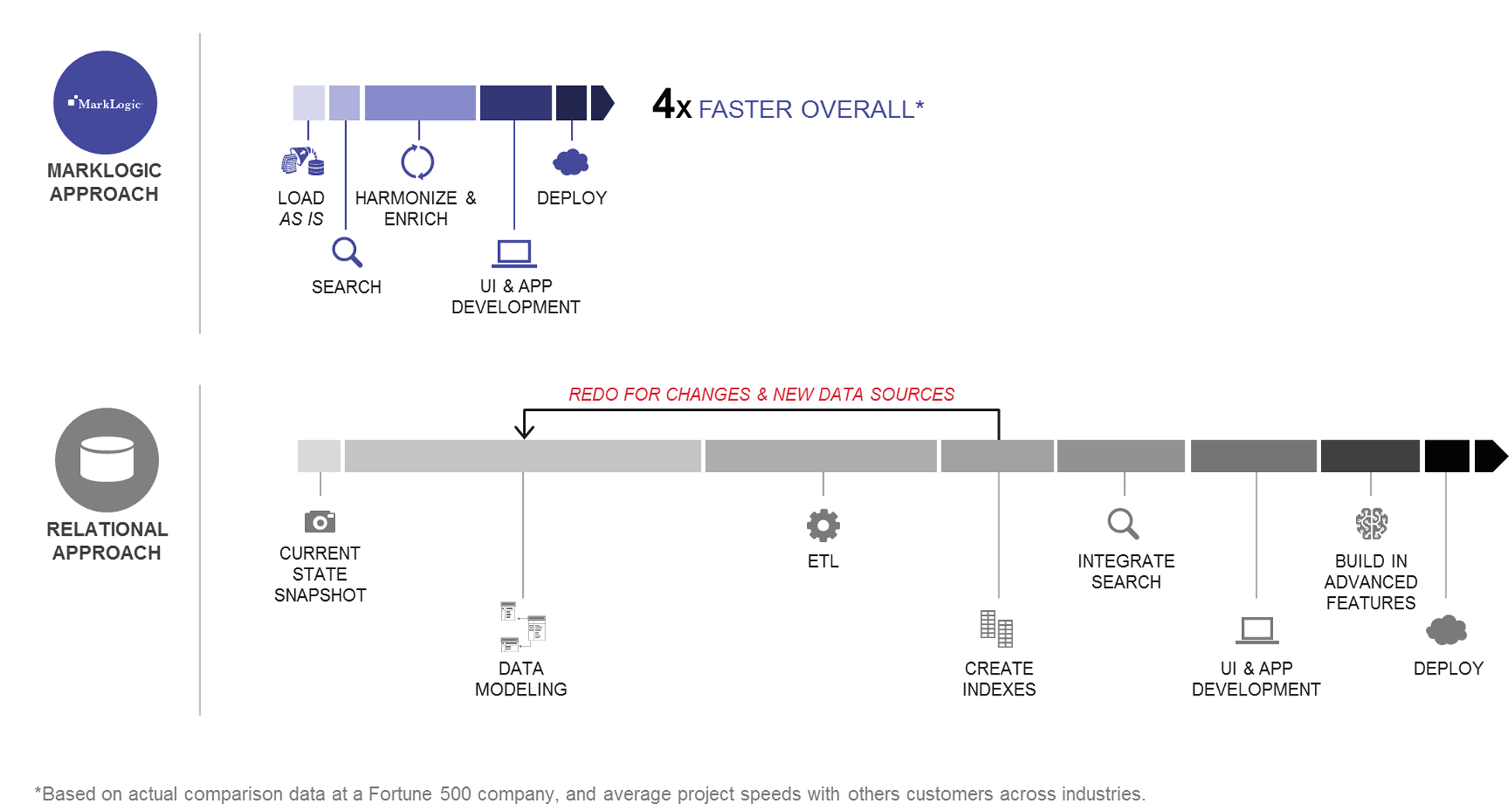
シングルアプリケーション用データベースの時代は終わりました。MarkLogicのプロダクトマネージャ、ジャスティン・マケイグは「アプリケーションは儚(はかな)い、しかしデータは永遠だ」と言っています。
これと同じ状況が、データ統合が大きなチャレンジであるあらゆる業界で繰り返されています。もし時間があったら、エトナのマイク・フィリオンによるプレゼンテーションをご覧ください。リレーショナルによるデータモデリングの問題について詳細に説明しています。話の流れはいつも同じで、リレーショナルによるデータモデリングには時間がかかり過ぎたため、MarkLogicを使ってプロジェクトを終わらせた、というものになります。これは、データモデリングが柔軟なため、間違った開発のリスクを避け将来の変更にも対応できるプラットフォームとなります。
この件に関して興味がある方は、MarkLogicによってデータモデルが楽にかつ速くなることについてのブログ(ETLについて取り上げたもの)をご覧ください。
リレーショナルデータベースは、構造化データを行や列として格納するように作られています。JSONやXMLのようなドキュメント用ではありません。しかし「リレーショナルベンダーがJSON対応を開始」というデータベース関連のニュースを耳にしたことがあるかもしれません。
リレーショナルデータベース会社が言う「JSON対応」というのは、実際には、JSONドキュメント用に指定された列にJSONドキュメントを入れることができる、ということです。XML対応のリレーショナルデータベースも、同じことです。
リレーショナルデータベースの列にJSONドキュメントを入れたところで、これがドキュメントデータベースになる訳ではありません。このようなやり方では、JSONはただのBLOBとなり、ドキュメントモデルの持つ価値が失われます。このドキュメントには完全にインデックスが付けられている訳ではなく、本物のドキュメントデータベースのように検索/更新/エンリッチはできません。そもそもドキュメントデータベースの長所であるリッチさや柔軟性がすべて失われます。またこの場合、リレーショナルデータベースの価値も失われてしまいます。表や列に関する統計量やインデックス機能、さまざまなスキャンなどがなくなります。できるのは極めて単純な操作だけです。
もしもリレーショナルデータベースがドキュメントデータベースと同様にJSONやXMLのデータを格納できるのであれば、MarkLogic、MongoDB、Couchbaseなどはそもそも存在していなかったでしょう。オラクルもBerkeleyDBのためにスリーピーキャットを買収して、自社でNoSQLデータベースを開発することもなかったでしょうし、IBMがクラウダント(CouchDBドキュメントデータベース)を買収することも、MicrosoftがDocumentDBを開発することもなかったでしょう。
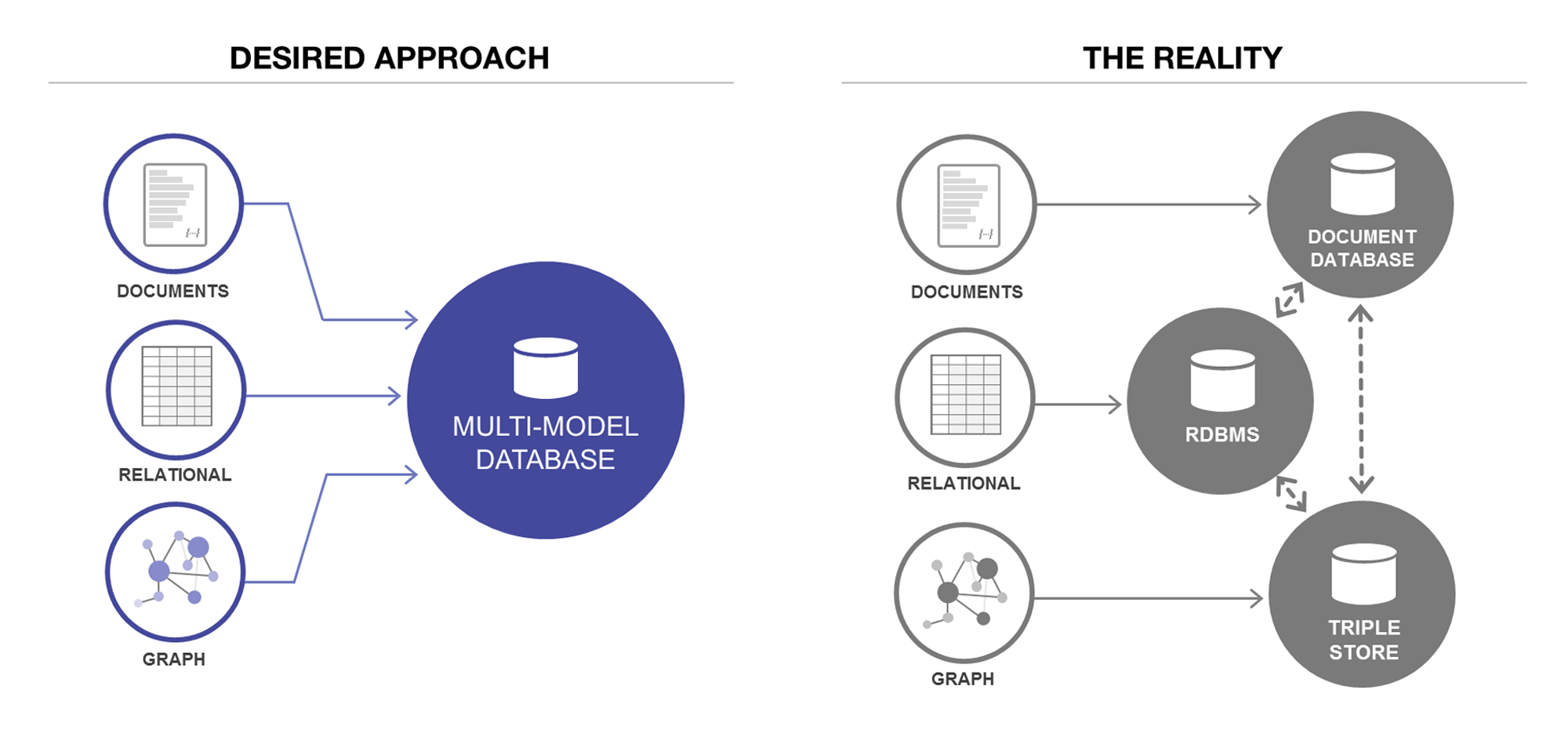
それではRDF用のグラフに対応しているリレーショナルデータベースはどうでしょうか。単純な構造のRDFの格納に関しては、リレーショナルデータベースは素晴らしいツールのように思えます。主語/述語/目的語のそれぞれに列を使えばいいのですから。しかし残念なことに、このやり方だとトリプルクエリに対して繰り返し何百回もジョインを行わなくてはなりません。例えば数十億行あるテーブル内のインデックス3つに対して更新をかけた場合、パフォーマンスはかなりひどくなります。このため、オラクルはトリプルインデックス用に別の製品を準備しているのです。
以上のような理由で、実際にはリレーショナルデータベースはあらゆるデータを格納するようにはできてない、と言って間違いないでしょう。確かに、お金と時間に余裕があればすべてを格納できるでしょうが、実際にはそんなことをやっている人はいません。他の種類のデータを格納するには、専用に作られたツールを選んだ方が楽だし、またより優れた結果が得られるでしょう。この考え方は今、「ポリグロット・パーシステンス」と呼ばれています。これによって、現在マルチモデルデータベースの採用が拡大しているのです。
以前他のブログで、リレーショナルデータベースは拡張するように作られていない、と書いたことがあります。これと同じことを言うアナリストやユーザーはたくさんいるでしょう。元オラクルDBAのロバート・シューマッハーはこの件について、「financial analyst conference in 2015」でのプレゼンテーションでうまくまとめています。
リレーショナルデータベースは拡張できない、ということではありません。しかし元々拡張するようには作られておらず、その後いろいろと改善を試みても、リレーショナルデータベースは依然として大規模拡張には向いていない、ということです。
『Infoworld』に投稿された「 How do I freaking scale Oracle?」という記事の中で、20年以上オラクルを使ってきた開発者がオラクルの拡張方法について述べています。以下のものが必要となります。
- 開発者によって設計された適切なシャーディングアルゴリズム
- フォールトトレランス。サーバー/格納/データセンター停止(=「災害」)用
- サーバー/CPUコア/ディスクへのロードバランス
これをすべて行うには、もっと製品を買わなくてはなりません。例えば一つの製品、「Oracle RAC」は共有ディスクアーキテクチャで、ロードバランスならびに高可用性の問題に対処します。しかし、ストレージが単一障害点となるという問題は依然として解決されません。これを解決するには、ストレージレプリケーションや仮想化を行うための他の製品が必要です(それぞれ「SRDF」「VPLEX」)。また拡張用の製品としてGoldenGateなどがあります。またそれによく似たトランザクションレプリケーション用のData Guardがあります。
最後に、分散されたノードに対してデータのパーティション(シャード)を行う必要があります。オラクルのパーティションでは、表やインデックスをより小さなもの(パーティション)に分割できます。分割されたものには新しく名前が付けられ、ストレージの性質も異なります。これは、NoSQLデータベースにおいてシャードキーに基づいてノードにデータを分割していく方法とあまり変わりません。しかしオラクルではデータの分割(パーティション)方法は複数あります。TimesTenあるいはそれほど知られていないCoherenceという製品は、インメモリキャッシュを使ってデータベースの負担を減らします。
これは複雑に聞こえるかもしれませんが、実際のところ複雑なのです。
オラクルは自らの製品が拡張性に欠けていることを認識しているため、オラクルデータベース12c(リリース2)で自動シャーディングを導入しました。オラクルの広報担当アンドリュー・メンデルスゾーンによると、自動シャーディングは「クラウド規模まで到達したあらゆるデータベースにとって本当に重要なコンポーネントです。…これによって極めて信頼性が高く、極めて拡張性のあるインフラが実現します(『フォーブス』、「Oracle’s Latest Database: Right Technology, Right Time」2016年9月20日)。
「スケールアウト」クラブへようこそ。MarkLogicには自動シャーディングが何年も前からありました。このように、リレーショナルベンダーが私たちの製品の長所の方に寄って来るを見るのは喜ばしいことです。こういった状況により、オラクルならびに他のリレーショナルベンダーはNoSQLをお手本にしているのです。J.P.モルガンのCTOはあるインタビューの中で「リレーショナルで無理なことはわかっていました。MarkLogicは水平拡張をもたらしてくれました。巨大なインフラのリプレースを行う必要ははなく、単に1つずつ追加していけばいいのです」と言っています。
次の記事では、NoSQLがどのように課題を解決するか、そして本当にそんなことが可能なのかとしばしば持たれる疑念について、2回に分けて説明しています。ここをクリックしてお読みください。
このトピックに関してわからないことがある方には、以下がお勧めです。

マット・アレン
マット・アレンはプロダクトマーケティングマネージャー担当副社長で、業種を問わずMarkLogicのすべての機能とメリットのマーケティングを担当しています。具体的には、製品・エンジニアリングチームとセールス・マーケティングチームを連携し、MarkLogicの技術について説明し、その導入メリットを伝えるコンテンツやイベントの制作に携わっています。カリフォルニア州サンカルロスにあるMarkLogic本社に勤務しています。仕事以外では、大型の油絵を描く画家でもあります。
