
(このブログは2017年に掲載されたものの日本語訳です。登場する人々の肩書は当時のものです)この記事は、2回シリーズの第2回めで、NoSQLに対して人々が抱く一般的な疑念を取り上げています。前回の記事では、リレーショナルデータベースに問題がないと思っている人からよく聞く疑念を取り上げました。この記事では、NoSQLに対する疑念を取り上げていきます。
この記事を読んでくださっている方は、リレーショナルへの全幅の信頼が若干揺らいではいるものの、まだNoSQLを完全に信じるところまでには至っていないのではないでしょうか。私たちが言うように、エンタープライズNoSQLが本当にリレーショナルに比べて「より上手く、より早く、より少ないコストでプロジェクトを遂行できる」かどうか、まだ大きな疑問があるかと思います。
疑いを持っている方の意見:「NoSQLは、細部への対処を後回しにしているだけです。まだスキーマは必要なはずです」
私たちの回答:「NoSQLは、細部にちゃんと対処しています。これをもっとアジャイルにやっているのです」
MarkLogicでは、データを「そのまま」(as is)読み込むことができると言っています。これはほとんどの人にとって衝撃です。同時に、この部分はよく誤解されます。例えば私たちが「データに構造は全然必要ないと言っている」と思われることがよくあります。もちろん、そんなことは全くありません。
データ構造の定義にスキーマが必要な場合も絶対にあります。トランザクショナルなアプリケーションを作っていて、顧客レコードを更新する必要がある場合、データの共通構造が必要です。とはいえ、どんな場合でも構造が必要なわけではありません。ここで求められるのは、必要なときにスキーマを定義できる機能です。また、必要なスキーマは1つではないこともありえます。例えば、複数のソースから取り込んだ複数のデータセットがある場合、複数のスキーマが必要になるでしょう。MarkLogicでは複数のスキーマを扱えます。一方、リレーショナルデータベースは、扱えるスキーマは1つです。そしてこの点こそが、ドキュメントモデルが上手くいく根本的な理由なのです。
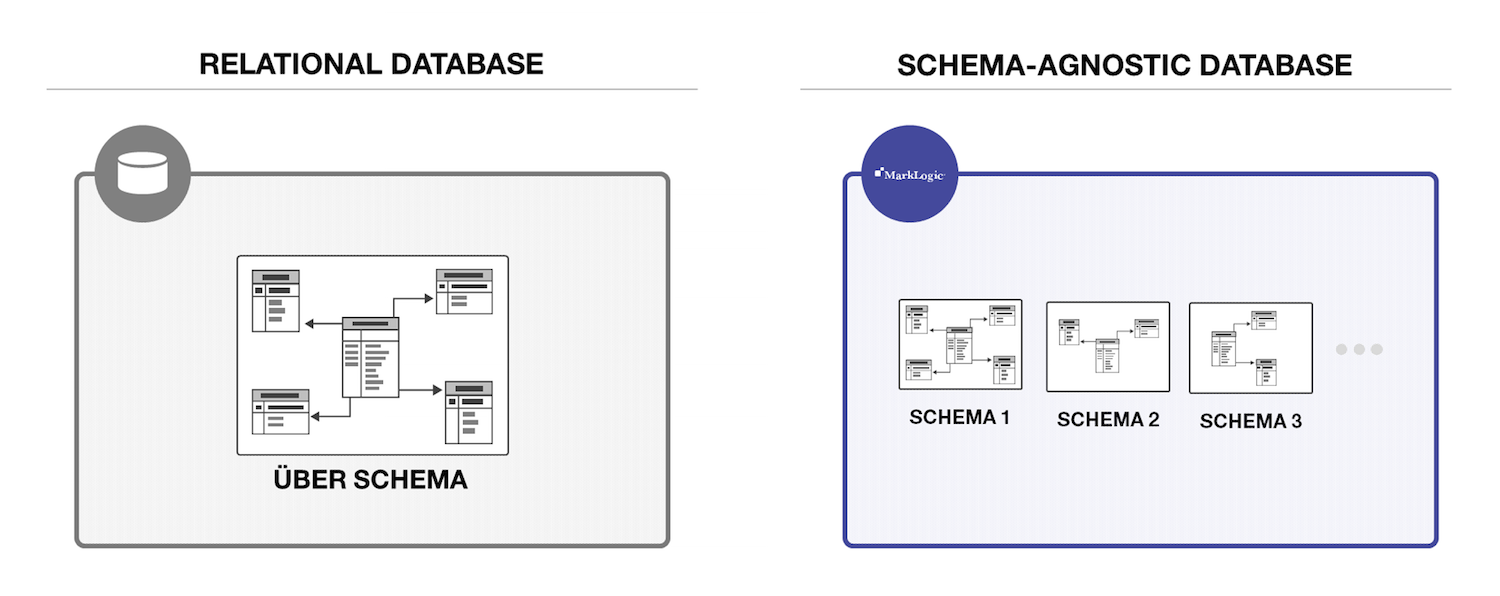
私のブログ『ETLなんかいらない』では、サイロに分断されたデータを統合する際に、複数スキーマを処理するMarkLogicの機能を活用する方法について詳しく説明しています。
別の記事では、ダン・マクリアリー氏がMarkLogicの「そのまま読み込む」機能について、かなり詳細に説明しています。この2つの記事でわかるのは、MarkLogicのデータモデリングおよび変更処理はアジャイルだということです。これは「アジャイルソフトウェア開発」と同様に、細部への対応を後回しにするのではなく、「適切なタイミングで細部に対応できる」システムを構築するということです。
プロジェクトの初期段階で、将来の新規データソースを予測することはできません。こういった新しいデータソースは、すでにデータベースに入っているデータとは全くスキーマが異なり、見た目もゴチャゴチャしているかもしれません。NoSQLデータベースでは、そういったデータをハーモナイズするための作業が必要です。とはいえ、事前にすべてのモデリングを行ったり、ETLスクリプトをすべて書き直したり、ソースデータを変換する際にどのデータを対象から除外するかを決める必要がないため、リスクを抑えて迅速に作業を進めることができます。
疑いを持っている方の意見:「NoSQLも遅かれ早かれ社内の手続きによって、スピードが遅くなるでしょう」
私たちの回答:「実際のところ、MarkLogicは他のデータベースと同様の手順を踏まなければなりません」
この疑念は、「リレーショナルデータベースに変更を加えるのはそれほど大変ではありません」という反論の次に来ることが多いです。つまり、変更を加えることは確かに困難であることが明らかになった場合、その原因は技術的というよりも「人・プロセス」の問題だということになってくるわけです。
その理由は、40年の歴史を持つリレーショナルデータベースには「経営陣によるオーバーヘッド」があるというものです。つまり、経営陣がリレーショナルデータベースをよく理解していて目を光らせているために、社内プロセスに時間がかかるということです。ここで、「新しいNoSQLデータベースによって状況が改善されている」といったところで、それは経営たちの「まだ管理下にないため(好き勝手できる)」と言われてしまうのです。しかし最終的には、NoSQLも他のミッションクリティカルなテクノロジーと同様の監督・管理の下に置かれるようになるでしょう。そうなれば、この点に関してはNoSQLでもリレーショナルと同じくらい時間がかかるようになります。
大規模な組織では、テクノロジーだけでなくさまざまな要素が絡み合っているのは事実です。人とプロセスも非常に重要ですが「社内プロセスがまだNoSQLに対応しきれていない」というのは、少なくともMarkLogicでは正しくありません。
MarkLogicは、ほぼすべてのケースで他のデータベースと同様の評価/テスト/承認/管理/規制監督を受けています。ミッションクリティカルではないユースケースやプロトタイプ用の他のオープンソースデータベースではは、違うかもしれません。しかし重要なユースケースでは、そういったものが必要となるのは確かです。
ミッションクリティカルな業務にMarkLogicを活用している事例
- KPMG KPMGは、主に規制/税務/報告のコンプライアンス用の顧客オンボーディングアプリケーションを、MarkLogic上に構築しています。このアプリケーションは、複雑な手作業をインテリジェントに自動化し、完全にトラッキング可能で監査可能なデータワークフローを実現します。
- ドイツ銀行 MarkLogicは、ドイツ銀行のオペレーショナル取引データのグローバルトレードストアとして、オラクルをリプレースしました。30以上の取引システムを統合した最初の本番システムは、安全で一貫性のある取引を維持しながら、わずか6か月で立ち上げられました。
- 米国戦闘司令部 MarkLogicは、米国防総省のさまざまなプログラムや人々が利用するますます多様化するデータセットのための、司令部全体の知識・情報共有システムのデータレイヤーとして、オラクルをリプレースしました。
MarkLogicでプロジェクトが早く進むのは、経営陣による監督や厳密な社内プロセスの対象にまだなっていないからではなく、組織のアジャイル化をリレーショナルよりも促進するためです。前述のように、リレーショナルデータベースでは、すべてのデータを前もってモデル化する必要があるため、データモデリングの決定にはウォーターフォール型の「ビッグバン(=一度に全部やってしまう)」アプローチが必要です。
MarkLogicの柔軟なデータモデルでは、プロセスを反復的に行うので、事前に単一のスキーマを決める必要はありません。
それではこの場合でも、組織がスキーマの変更を理解・評価する必要があるのでしょうか。それは間違いなくその通りです。変更にかかる時間が短くなるからといって、規制や監督のない特別な承認プロセスが適用されるわけではありません。
疑いを持っている方の意見:「NoSQLデータベースは、シンプルなアプリケーションにしか使えません」
私たちの回答:「おそらく、他のNoSQLデータベースはそうでしょう。しかし、MarkLogicは違います」
オラクルのデータベース・サーバー・テクノロジー担当EVPであるアンディ・メンデルソン氏は、eWeekのインタビューで、次のように述べています。「これはとても単純な話です。NoSQL製品は、非常にシンプルなアプリケーションに適しています。データをキーに指定して、値を返すのですが、それはJSONドキュメントであったり、人々が望む他のものであったりします。リレーショナルSQLデータベースは、ビジネスレポートの作成やトランザクション処理といった、より複雑なワークロードを得意にしています」。
これはちょっと上から目線のコメントですが、部分的には事実なのでここで取り上げる価値があります。実際のところ、webアプリケーションやオンラインゲームのセッション情報の管理や、ソーシャルアプリやIoTからのデータフィード管理といった、比較的シンプルなユースケース用のNoSQLデータベースも多々あります。シンプルなキーバリューストアさえあれば良いということも多いです。つまり、メンデルソン氏が言及しているシンプルなドキュメントストア(キーバリューストアなど)だけで十分なのです。ドキュメントデータベースの中には、ドキュメントIDをキーにしてドキュメントのそれ以外の部分を値として扱うものもあります。この場合、ドキュメント全体にインデックスを付ける必要はありませんし、トランザクションの一貫性/整合性も不要です。またセキュリティもいりません。シンプルなもので十分なのです。
しかし、すべてのドキュメントデータベースが全部そうだということではありません。少なくとも、MarkLogicは違います。つまり、メンデルソン氏のコメントはMarkLogicに関しては全く当たっていません。
MarkLogicは、単純なキーバリューストアよりもはるかに優れており、他のドキュメントストアよりも多くの機能を備えています。これは主に、MarkLogicにはインデックスとトランザクションに加えて、その他の多数のエンタープライズ機能が備わっているためです。
MarkLogicでは、ユニバーサルインデックスを使用してJSONやXMLドキュメント全体にインデックスを付けるため、ドキュメント内のあらゆるものを検索したり、非常に複雑なクエリを実行したりできます。顧客レコードの場合、IDで検索できるだけでなく、顧客の郵便番号や名字などでも検索できます。
また、MarkLogicはACIDトランザクションを備えているため、複数ドキュメントの分散トランザクションなどの非常に複雑でハイパフォーマンスなトランザクション用に多くの組織で採用されています。MarkLogicには、数十万人のユーザーに対して毎秒数千件ものトランザクションを処理している事例がたくさんあります。さらに、MarkLogicにはエンタープライズグレードのHA/DRが備わっているだけでなく、複数のセキュリティ認証も受けています。
言うまでもなく、MarkLogicは「ビジネスレポートの作成やトランザクション処理といった、より複雑なワークロード」を処理できます。MarkLogicは、他のドキュメントデータベースとは違って、ミッションクリティカルなアプリケーションで活用できるのです。例えば、ある大手銀行は、他のオープンソースのドキュメントデータベースとMarkLogicを使用しています。このオープンソースのドキュメントデータベースのライセンスは200本ありますが(うち有償ライセンスは13本)、本番アプリケーションで使われているものは1つもありません。
MarkLogicは、エンタープライズアプリケーション用に設計されたドキュメントストアであるだけでなく、RDFトリプル(セマンティック用)も格納できます。こういった機能により、MarkLogicは、複数のデータモデルを単一のシステムに統合した真のマルチモデルデータベースとなっています。つまり一個のマルチモデルAPIであらゆるデータに対してクエリを実行できるのです。
MarkLogicは、あらゆるエンティティ(ドキュメント)と関係性(トリプル)を格納するためには完璧なシステムとなっています。
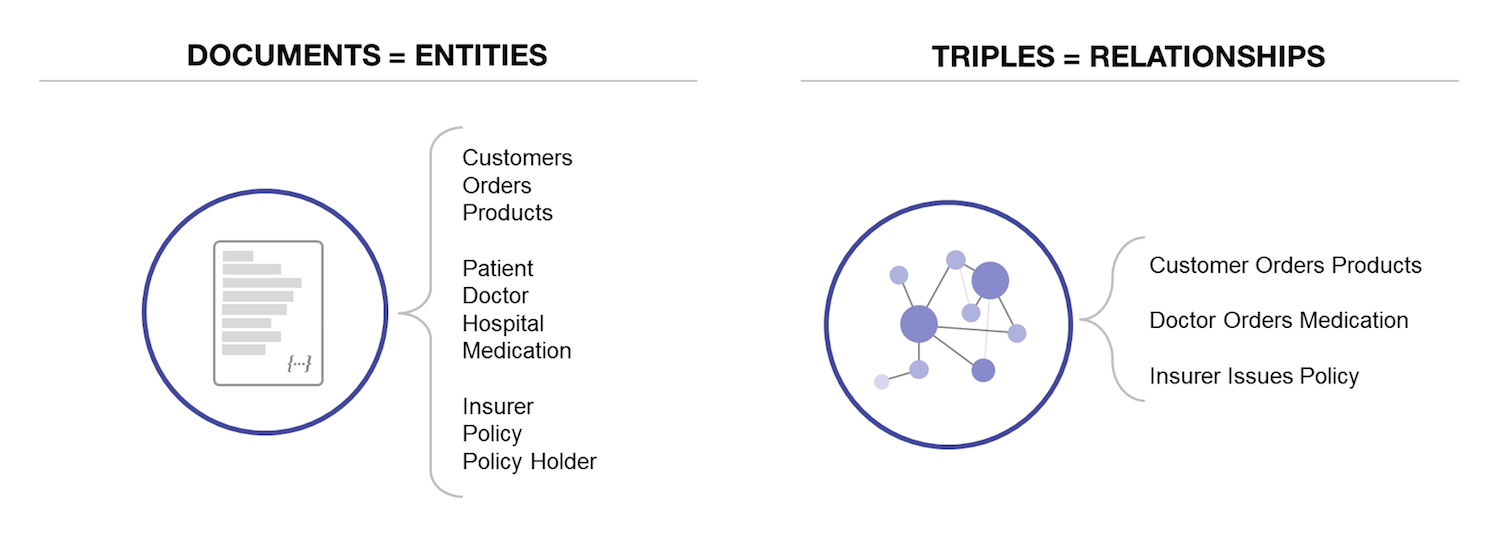
皮肉なことに、一元化されたMarkLogicのシステムと同等の機能をオラクルで実現するには、データベース/検索エンジン/トリプルストアを組み合わせて使う必要があります。MarkLogicは、モダンかつトランザクショナルなエンタープライズアプリケーションに対応した、一元化されたマルチモデルデータベースなのです。
さらに詳しく
『Escape the Matrix』:MarkLogicのエンジニアリング担当SVPであるデイヴィッド・ゴーベットよる45分間のビデオ。異なる複数のスキーマを統合した素晴らしい例です。
エトナ『mplementing an Enterprise Operational Data Hub』:マイク・フィリオン氏(エトナ、アーキテクチャデリバリーディレクター)

マット・アレン
マット・アレンはプロダクトマーケティングマネージャー担当副社長で、業種を問わずMarkLogicのすべての機能とメリットのマーケティングを担当しています。具体的には、製品・エンジニアリングチームとセールス・マーケティングチームを連携し、MarkLogicの技術について説明し、その導入メリットを伝えるコンテンツやイベントの制作に携わっています。カリフォルニア州サンカルロスにあるMarkLogic本社に勤務しています。仕事以外では、大型の油絵を描く画家でもあります。
